吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets,ensemble
from sklearn.model_selection import train_test_split def load_data_regression():
'''
加载用于回归问题的数据集
'''
#使用 scikit-learn 自带的一个糖尿病病人的数据集
diabetes = datasets.load_diabetes()
# 拆分成训练集和测试集,测试集大小为原始数据集大小的 1/4
return train_test_split(diabetes.data,diabetes.target,test_size=0.25,random_state=0) #集成学习梯度提升决策树GradientBoostingRegressor回归模型
def test_GradientBoostingRegressor(*data):
X_train,X_test,y_train,y_test=data
regr=ensemble.GradientBoostingRegressor()
regr.fit(X_train,y_train)
print("Training score:%f"%regr.score(X_train,y_train))
print("Testing score:%f"%regr.score(X_test,y_test)) # 获取分类数据
X_train,X_test,y_train,y_test=load_data_regression()
# 调用 test_GradientBoostingRegressor
test_GradientBoostingRegressor(X_train,X_test,y_train,y_test)

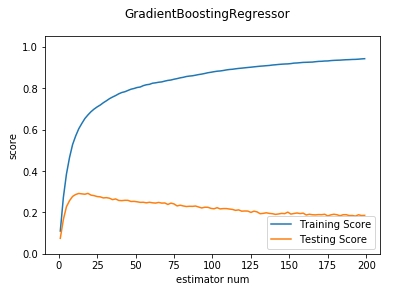
def test_GradientBoostingRegressor_num(*data):
'''
测试 GradientBoostingRegressor 的预测性能随 n_estimators 参数的影响
'''
X_train,X_test,y_train,y_test=data
nums=np.arange(1,200,step=2)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for num in nums:
regr=ensemble.GradientBoostingRegressor(n_estimators=num)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(nums,training_scores,label="Training Score")
ax.plot(nums,testing_scores,label="Testing Score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1.05)
plt.suptitle("GradientBoostingRegressor")
plt.show() # 调用 test_GradientBoostingRegressor_num
test_GradientBoostingRegressor_num(X_train,X_test,y_train,y_test)
def test_GradientBoostingRegressor_maxdepth(*data):
'''
测试 GradientBoostingRegressor 的预测性能随 max_depth 参数的影响
'''
X_train,X_test,y_train,y_test=data
maxdepths=np.arange(1,20)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for maxdepth in maxdepths:
regr=ensemble.GradientBoostingRegressor(max_depth=maxdepth,max_leaf_nodes=None)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(maxdepths,training_scores,label="Training Score")
ax.plot(maxdepths,testing_scores,label="Testing Score")
ax.set_xlabel("max_depth")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(-1,1.05)
plt.suptitle("GradientBoostingRegressor")
plt.show() # 调用 test_GradientBoostingRegressor_maxdepth
test_GradientBoostingRegressor_maxdepth(X_train,X_test,y_train,y_test)

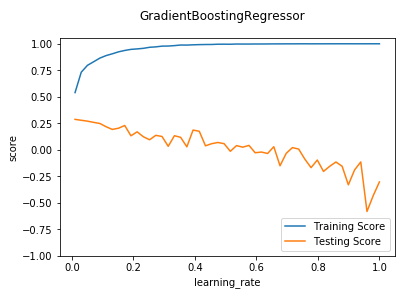
def test_GradientBoostingRegressor_learning(*data):
'''
测试 GradientBoostingRegressor 的预测性能随 learning_rate 参数的影响
'''
X_train,X_test,y_train,y_test=data
learnings=np.linspace(0.01,1.0)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for learning in learnings:
regr=ensemble.GradientBoostingRegressor(learning_rate=learning)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(learnings,training_scores,label="Training Score")
ax.plot(learnings,testing_scores,label="Testing Score")
ax.set_xlabel("learning_rate")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(-1,1.05)
plt.suptitle("GradientBoostingRegressor")
plt.show() # 调用 test_GradientBoostingRegressor_learning
test_GradientBoostingRegressor_learning(X_train,X_test,y_train,y_test)
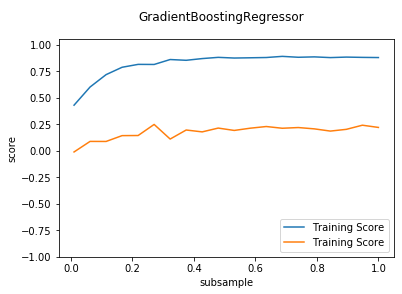
def test_GradientBoostingRegressor_subsample(*data):
'''
测试 GradientBoostingRegressor 的预测性能随 subsample 参数的影响
'''
X_train,X_test,y_train,y_test=data
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
subsamples=np.linspace(0.01,1.0,num=20)
testing_scores=[]
training_scores=[]
for subsample in subsamples:
regr=ensemble.GradientBoostingRegressor(subsample=subsample)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(subsamples,training_scores,label="Training Score")
ax.plot(subsamples,testing_scores,label="Training Score")
ax.set_xlabel("subsample")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(-1,1.05)
plt.suptitle("GradientBoostingRegressor")
plt.show() # 调用 test_GradientBoostingRegressor_subsample
test_GradientBoostingRegressor_subsample(X_train,X_test,y_train,y_test)
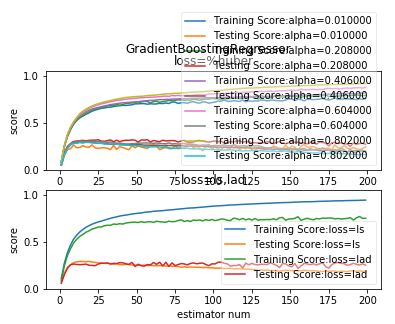
def test_GradientBoostingRegressor_loss(*data):
'''
测试 GradientBoostingRegressor 的预测性能随不同的损失函数和 alpha 参数的影响
'''
X_train,X_test,y_train,y_test=data
fig=plt.figure()
nums=np.arange(1,200,step=2)
########## 绘制 huber ######
ax=fig.add_subplot(2,1,1)
alphas=np.linspace(0.01,1.0,endpoint=False,num=5)
for alpha in alphas:
testing_scores=[]
training_scores=[]
for num in nums:
regr=ensemble.GradientBoostingRegressor(n_estimators=num,loss='huber',alpha=alpha)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(nums,training_scores,label="Training Score:alpha=%f"%alpha)
ax.plot(nums,testing_scores,label="Testing Score:alpha=%f"%alpha)
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right",framealpha=0.4)
ax.set_ylim(0,1.05)
ax.set_title("loss=%huber")
plt.suptitle("GradientBoostingRegressor")
#### 绘制 ls 和 lad
ax=fig.add_subplot(2,1,2)
for loss in ['ls','lad']:
testing_scores=[]
training_scores=[]
for num in nums:
regr=ensemble.GradientBoostingRegressor(n_estimators=num,loss=loss)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(nums,training_scores,label="Training Score:loss=%s"%loss)
ax.plot(nums,testing_scores,label="Testing Score:loss=%s"%loss)
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right",framealpha=0.4)
ax.set_ylim(0,1.05)
ax.set_title("loss=ls,lad")
plt.suptitle("GradientBoostingRegressor")
plt.show() # 调用 test_GradientBoostingRegressor_loss
test_GradientBoostingRegressor_loss(X_train,X_test,y_train,y_test)
def test_GradientBoostingRegressor_max_features(*data):
'''
测试 GradientBoostingRegressor 的预测性能随 max_features 参数的影响
'''
X_train,X_test,y_train,y_test=data
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
max_features=np.linspace(0.01,1.0)
testing_scores=[]
training_scores=[]
for features in max_features:
regr=ensemble.GradientBoostingRegressor(max_features=features)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(max_features,training_scores,label="Training Score")
ax.plot(max_features,testing_scores,label="Training Score")
ax.set_xlabel("max_features")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1.05)
plt.suptitle("GradientBoostingRegressor")
plt.show() # 调用 test_GradientBoostingRegressor_max_features
test_GradientBoostingRegressor_max_features(X_train,X_test,y_train,y_test)
吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型的更多相关文章
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
- 吴裕雄 python 机器学习——人工神经网络感知机学习算法的应用
import numpy as np from matplotlib import pyplot as plt from sklearn import neighbors, datasets from ...
- 吴裕雄 python 机器学习——人工神经网络与原始感知机模型
import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D from ...
- 吴裕雄 python 机器学习——分类决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——回归决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
随机推荐
- 假期学习【二】配置Scala环境(Ubuntu)以及配套Scala编程实验
1.配置Scala环境所需要的所有命令(Ubuntu系统下) 其中scala-2.13.1版本在官网:https://www.scala-lang.org/download/ 下载 2.出现该提示 ...
- 《深入理解java虚拟机》读书笔记一——第二章
第二章 Java内存区域与内存溢出异常 1.运行时数据区域 程序计数器: 当前线程所执行的字节码的行号指示器,用于存放下一条需要运行的指令. 运行速度最快位于处理器内部. 线程私有. 虚拟机栈: 描述 ...
- Vue ui创建项目
vue-cli 3.0 版本为我们提供了集 创建.管理.分析 为一体的可视化界面vue UI,一个可视化项目管理器 一.打开终端,安装最新vue-cli npm install -g @vue/cli ...
- 一点点学习PS--实战五
本节实战的内容,新学习到的功能是:人物影子边缘.立体的心形 1.工具的使用: (1)滤镜--模糊--特殊模糊 (2)滤镜--滤镜库--艺术效果--水彩 (3)滤镜--滤镜库--纹理化 (4)自动形状工 ...
- 题解【洛谷P3574】[POI2014]FAR-FarmCraft
题面 简化版题意: 有一棵 \(n\) 个点的树,有边权. 你初始在 \(1\) 号节点,你需要走遍整棵树为 \(2 \sim n\) 号点的居民分发电脑,但你的汽油只够经过每条边恰好两次. 一个居民 ...
- Python记
在企业应用领域,Java或C#都是不错的选择.
- 如何在linux主机上运行/调试 arm/mips架构的binary
如何在linux主机上运行/调试 arm/mips架构的binary 原文链接M4x@10.0.0.55 本文中用于展示的binary分别来自Jarvis OJ上pwn的add,typo两道题 写这篇 ...
- C#中画三角形和填充三角形的简单实现
C#中画三角形和填充三角形的简单实现: private void Form1_Paint(object sender, PaintEventArgs e) { Graphics g = e.Graph ...
- css 单位之px , em , rem
px : Pixel像素单位.像素是相对显示器分辨率而言.em : 相对长度单位,基准点为父节点字体的大小,如果自身定义了font-size按自身来计算(浏览器默认字体是16px).rem : 相对单 ...
- Python爬取ithome的一所有新闻标题评论数及其他一些信息并存入Excel中。
# coding=utf-8 import numpy as np import pandas as pd import sys from selenium import webdriver impo ...