(19)python scrapy框架
安装scrapy
pycharm 建个纯python工程
settings里




环境变量设置
C:\Python27;C:\Python27\Scripts;
下载win32api
https://sourceforge.net/projects/pywin32/files/pywin32/
找到对应版本安装
import win32api
导入不报错就按成功
创建一个工程
在想要创建工程的位置点击 shift + 右键
scrapy startproject 工程名
目录
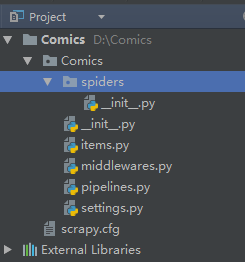
scrapy.cfg:项目的配置文件
spiders文件夹:存储爬虫编写爬虫的目录
Items.py:数据容器,用来存储提取到的数据
settings.py:项目的设置文件
快速生成一个爬虫模板
scrapy genspider 爬虫名 爬虫网址
scrapy genspider huhu http://www.huhumh.com/
它会自动在spiders的文件夹下自动生成一个 huhu.py的文件
# -*- coding: utf-8 -*-
import scrapy class HuhuSpider(scrapy.Spider):
name = 'huhu'
allowed_domains = ['http://www.huhumh.com/']
start_urls = ['http://http://www.huhumh.com//'] def parse(self, response):
pass
这个huh.py用来写爬虫的核心代码
运行爬虫程序
在pycharm里的 Terminal输入: scrapy crawl 爬虫名
scrapy crawl huhu
scrapy命令行指令
显示scrapy版本
scrapy version
scrapy version -v #更全
帮助
scrapy --help
运行一个独立于Python文件的蜘蛛,无需创建一个项目
scrapy runspider myspider.py
查看有哪些当前工程下爬虫列表
scrapy list
在浏览器中打开给定的URL,并以Scrapy spider获取到的形式展现
scrapy view http://www.example.com/some/page.html
些时候spider获取到的页面和普通用户看到的并不相同。 因此该命令可以用来检查spider所获取到的页面,并确认这是您所期望的。
获取给定的URL并使用工程的parse方法分析处理
scrapy parse http://www.example.com/some/page.html
如果您提供 --callback 选项,则使用spider的该方法处理,否则使用 parse 。
支持的选项:
--spider=SPIDER: 跳过自动检测spider并强制使用特定的spider--a NAME=VALUE: 设置spider的参数(可能被重复)--callbackor-c: spider中用于解析返回(response)的回调函数--pipelines: 在pipeline中处理item--rulesor-r: 使用CrawlSpider规则来发现用来解析返回(response)的回调函数--noitems: 不显示爬取到的item--nolinks: 不显示提取到的链接--nocolour: 避免使用pygments对输出着色--depthor-d: 指定跟进链接请求的层次数(默认: 1)--verboseor-v: 显示每个请求的详细信息
scrapy对象
(19)python scrapy框架的更多相关文章
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- [Python][Scrapy 框架] Python3 Scrapy的安装
1.方法(只介绍 pip 方式安装) PS.不清楚 pip(easy_install) 可以百度或留言. cmd命令: (直接可以 pip,而不用跳转到 pip.exe目录下,是因为把所在目录加入 P ...
- python scrapy框架爬虫遇到301
1.什么是状态码301 301 Moved Permanently(永久重定向) 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一.如果可能,拥有链接编 ...
- Python scrapy框架
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
- Python - Scrapy 框架
Scrapy 是采用Python 开发的一个快速可扩展的抓取WEB 站点内容的爬虫框架.Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构 ...
- 我的第一篇博文,Python+scrapy框架安装。
自己用Python脚本写爬虫有一段时日了,也抓了不少网页,有的网页信息两多,一个脚本用exe跑了两个多月,数据还在进行中.但是总觉得这样抓效率有点低,问题也是多多的,很早就知道了这个框架好用,今天终于 ...
- 利用python scrapy 框架抓取豆瓣小组数据
因为最近在找房子在豆瓣小组-上海租房上找,发现搜索困难,于是想利用爬虫将数据抓取. 顺便熟悉一下Python. 这边有scrapy 入门教程出处:http://www.cnblogs.com/txw1 ...
- Python scrapy框架爬取瓜子二手车信息数据
项目实施依赖: python,scrapy ,fiddler scrapy安装依赖的包: 可以到https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载 pywi ...
- python scrapy框架爬取豆瓣
刚刚学了一下,还不是很明白.随手记录. 在piplines.py文件中 将爬到的数据 放到json中 class DoubanmoviePipelin2json(object):#打开文件 open_ ...
随机推荐
- BFS:HDU2054-A==B?(字符串的比较)
A == B ? Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total S ...
- 试水新的Angular4 HTTP API
本文来自网易云社区 作者:梁月康 原文:https://netbasal.com/a-taste-from-the-new-angular-http-client-38fcdc6b359b Angul ...
- Docker danriti/nginx-gunicorn-flask 使用
现成的镜像,已经配置好nginx-gunicorn-flask,可直接部署flask 项目 直接部署flask项目 安装镜像 如果默认源比较慢,可以换成163镜像源 http://hub-mirror ...
- 堆STL和重载运算符
大根堆: 1.priority_queue<int> q;[默认 2. priority_queue< node,vector<node>,less<node> ...
- Leetcode 554.砖墙
砖墙 你的面前有一堵方形的.由多行砖块组成的砖墙. 这些砖块高度相同但是宽度不同.你现在要画一条自顶向下的.穿过最少砖块的垂线. 砖墙由行的列表表示. 每一行都是一个代表从左至右每块砖的宽度的整数列表 ...
- svm常用核函数
SVM核函数的选择对于其性能的表现有至关重要的作用,尤其是针对那些线性不可分的数据,因此核函数的选择在SVM算法中就显得至关重要.对于核技巧我们知道,其目的是希望通过将输入空间内线性不可分的数据映射到 ...
- MySQL主从复制入门
1.MySQL主从复制入门 首先,我们看一个图: MySQL 主从复制与读写分离概念及架构分析 影响MySQL-A数据库的操作,在数据库执行后,都会写入本地的日志系统A中. 假设,实时的将变化了的日志 ...
- w3wp.exe占用cpu特别高
w3wp.exe占用cpu特别高,百度了一下在任务管理器标记出PID可以看到进程号. 试了一下,发现一个xxx网站占用cpu特别高,然后就结束了下进程,再重启网站cpu一下子降下来. 很奇怪,还需要具 ...
- 用Vundle管理Vim插件
作为程序员,一个好用的Vim,是极其重要的,而插件能够使原本功能羸弱的Vim变得像其他功能强大的IDE一样好用.然而下载.配置插件的过程比较繁琐,大家往往需要自己进行下载/配置等操作,如果还涉及到更新 ...
- [HDU3516] Tree Construction [四边形不等式dp]
题面: 传送门 思路: 这道题有个结论: 把两棵树$\left[i,k\right]$以及$\left[k+1,j\right]$连接起来的最小花费是$x\left[k+1\right]-x\left ...