(19)python scrapy框架
安装scrapy
pycharm 建个纯python工程
settings里




环境变量设置
C:\Python27;C:\Python27\Scripts;
下载win32api
https://sourceforge.net/projects/pywin32/files/pywin32/
找到对应版本安装
import win32api
导入不报错就按成功
创建一个工程
在想要创建工程的位置点击 shift + 右键
scrapy startproject 工程名
目录
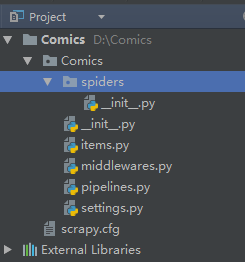
scrapy.cfg:项目的配置文件
spiders文件夹:存储爬虫编写爬虫的目录
Items.py:数据容器,用来存储提取到的数据
settings.py:项目的设置文件
快速生成一个爬虫模板
scrapy genspider 爬虫名 爬虫网址
scrapy genspider huhu http://www.huhumh.com/
它会自动在spiders的文件夹下自动生成一个 huhu.py的文件
# -*- coding: utf-8 -*-
import scrapy class HuhuSpider(scrapy.Spider):
name = 'huhu'
allowed_domains = ['http://www.huhumh.com/']
start_urls = ['http://http://www.huhumh.com//'] def parse(self, response):
pass
这个huh.py用来写爬虫的核心代码
运行爬虫程序
在pycharm里的 Terminal输入: scrapy crawl 爬虫名
scrapy crawl huhu
scrapy命令行指令
显示scrapy版本
scrapy version
scrapy version -v #更全
帮助
scrapy --help
运行一个独立于Python文件的蜘蛛,无需创建一个项目
scrapy runspider myspider.py
查看有哪些当前工程下爬虫列表
scrapy list
在浏览器中打开给定的URL,并以Scrapy spider获取到的形式展现
scrapy view http://www.example.com/some/page.html
些时候spider获取到的页面和普通用户看到的并不相同。 因此该命令可以用来检查spider所获取到的页面,并确认这是您所期望的。
获取给定的URL并使用工程的parse方法分析处理
scrapy parse http://www.example.com/some/page.html
如果您提供 --callback 选项,则使用spider的该方法处理,否则使用 parse 。
支持的选项:
--spider=SPIDER: 跳过自动检测spider并强制使用特定的spider--a NAME=VALUE: 设置spider的参数(可能被重复)--callbackor-c: spider中用于解析返回(response)的回调函数--pipelines: 在pipeline中处理item--rulesor-r: 使用CrawlSpider规则来发现用来解析返回(response)的回调函数--noitems: 不显示爬取到的item--nolinks: 不显示提取到的链接--nocolour: 避免使用pygments对输出着色--depthor-d: 指定跟进链接请求的层次数(默认: 1)--verboseor-v: 显示每个请求的详细信息
scrapy对象
(19)python scrapy框架的更多相关文章
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- [Python][Scrapy 框架] Python3 Scrapy的安装
1.方法(只介绍 pip 方式安装) PS.不清楚 pip(easy_install) 可以百度或留言. cmd命令: (直接可以 pip,而不用跳转到 pip.exe目录下,是因为把所在目录加入 P ...
- python scrapy框架爬虫遇到301
1.什么是状态码301 301 Moved Permanently(永久重定向) 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一.如果可能,拥有链接编 ...
- Python scrapy框架
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
- Python - Scrapy 框架
Scrapy 是采用Python 开发的一个快速可扩展的抓取WEB 站点内容的爬虫框架.Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构 ...
- 我的第一篇博文,Python+scrapy框架安装。
自己用Python脚本写爬虫有一段时日了,也抓了不少网页,有的网页信息两多,一个脚本用exe跑了两个多月,数据还在进行中.但是总觉得这样抓效率有点低,问题也是多多的,很早就知道了这个框架好用,今天终于 ...
- 利用python scrapy 框架抓取豆瓣小组数据
因为最近在找房子在豆瓣小组-上海租房上找,发现搜索困难,于是想利用爬虫将数据抓取. 顺便熟悉一下Python. 这边有scrapy 入门教程出处:http://www.cnblogs.com/txw1 ...
- Python scrapy框架爬取瓜子二手车信息数据
项目实施依赖: python,scrapy ,fiddler scrapy安装依赖的包: 可以到https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载 pywi ...
- python scrapy框架爬取豆瓣
刚刚学了一下,还不是很明白.随手记录. 在piplines.py文件中 将爬到的数据 放到json中 class DoubanmoviePipelin2json(object):#打开文件 open_ ...
随机推荐
- memset和memcpy
void memset(void s, int ch, size_t n); 函数解释:将s中当前位置后面的n个字节 (typedef unsigned int size_t )用 ch 替换并返回 ...
- 关于IDEA 单元测试时 【empty test suite】异常的分析!!
IDEA功能很强大,配置很操蛋,自从用了之后掉了很多坑!!! 这几天要用单元测试,方法完好但是就是一直报empty test suite ,WTF,类找不到 在网上反复的找答案都没有合适 静下心想想, ...
- jQuery+Asp.net 实现简单的下拉加载更多功能
原来做过的商城项目现在需要增加下拉加载的功能,简单的实现了一下.大概可以整理一下思路跟代码. 把需要下拉加载的内容进行转为JSON处理存在当前页面: <script type="tex ...
- mongoTemplate聚合操作Demo
package com.tangzhe.mongodb.mongotemplate; import com.mongodb.BasicDBObject; import com.mongodb.DBOb ...
- mysql查询当天的数据
mysql查询当天的数据 贴代码: #两个时间都使用to_days()函数 select * from reple where to_days(create_time) = to_days(NOW() ...
- RemoteFX
RemoteFX 编辑 RemoteFX是微软在Windows 7/2008 R2 SP1中增加的一项桌面虚拟化技术,使得用户在使用远程桌面或虚拟桌面进行游戏应用时,可以获得和本地桌面一致的效果. 外 ...
- IOS开发---菜鸟学习之路--(二十二)-近期感想以及我的IOS学习之路
在不知不觉当中已经写了21篇内容 其实一开始是没有想些什么东西的 只是买了Air后 感觉用着挺舒服的,每天可以躺在床上,就一台笔记本,不用网线,不用电源,不用鼠标,不用键盘,干干脆脆的就一台笔记本. ...
- jquery左右滑动菜单
<div class="mini-container" style="position:relative;height:100%;"> <di ...
- CSU-2034 Column Addition
CSU-2034 Column Addition Description A multi-digit column addition is a formula on adding two intege ...
- 用例UML图
用例图主要用来描述“用户.需求.系统功能单元”之间的关系.它展示了一个外部用户能够观察到的系统功能模型图. [用途]:帮助开发团队以一种可视化的方式理解系统的功能需求. 用例图中涉及的关系有:关联.泛 ...