pandas中数据聚合【重点】
数据聚合
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
1.数据分类处理的核心: groupby()函数
导入模块:
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
生成假数据
df = DataFrame({"sailer":np.random.randint(0,3,size=50),
"item":np.random.randint(0,3,size=50),
"price":np.random.randint(1,15,size = 50),
"weight":np.random.randint(50,150,size=50)})
df["sailer"] = df["sailer"].map({0:"李大妈",1:"王大爷",2:"宋大妈"})
df["item"] = df["item"].map({0:"白菜",1:"萝卜",2:"青椒"})
def convert(x):
return x-x%10
df["weight"] = df["weight"].map(convert)
df
如:

对数据进行分组,聚合操作
根据item进行分组,然后求出各个菜品的平均价格
g = df.groupby(by=["item"])["price"]
g.median()

表现形式如上边,数据格式为series
然后在根据sailer和item进行分类。
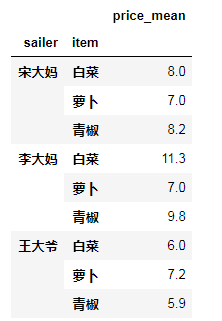
ret = df.groupby(by = ["sailer","item"])[["price"]].mean() #price值变成dataframe二维数如下图:
ret.add_suffix("_mean") #给列添加后缀 add_prefix()添加前缀
根据条件进行分组,然后自定义方法展示数据:如下
ret2 = df.groupby(by = ["sailer","item"])
def count(x):
return (np.round(x.mean(),1),x.min(),x.max()) #numpy中有round()方法是将小数四舍五入到给定的小数位数
ret2.agg(count)
aggregate()或agg()是指在指定轴上使用一个或多个操作进行聚合。

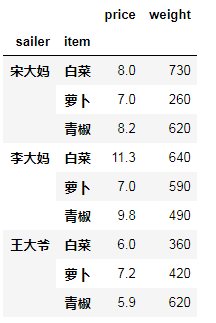
分组后对几个列添加不同的聚合映射关系
如下:对price求平均值,对重量求和
ret2 = df.groupby(by = ["sailer","item"])
ret2.agg({"price":"mean","weight":"sum"})
分组后使用透视表对数据进行聚合操作
pd.pivot_table(df,values=["sailer","weight"],index = ["sailer","item"],aggfunc ={"price":"mean","weight":"max"})
如下:对price、weight分别进行求平均值和最大值操作。

高级数据聚合
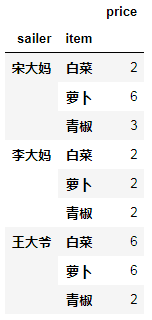
调用transform和apply实现上变相同的功能
df.groupby(["sailer","item"])[["price"]].apply(np.min)
#因为min,mean,median等聚合函数在numpy定义了,所以,调用聚合函数得去numpy中调用
# transform原来的数据有多长,现在的数据就有多长
# 有利于对和原来的数据进行合并。
使用transform对数据进行分组聚合操作
df1 = df.groupby(["sailer","item"])[["price"]].transform(np.mean)
df1.tail()

pandas中数据聚合【重点】的更多相关文章
- Pandas中数据的处理
有两种丢失数据 ——None ——np.nan(NaN) None是python自带的,其类型为python object.因此,None不能参与到任何计算中 Object类型的运算比int类型的运算 ...
- pandas中数据框DataFrame获取每一列最大值或最小值
1.python中数据框求每列的最大值和最小值 df.min() df.max()
- pandas中数据框的一些常见用法
1.创建数据框或读取外部csv文件 创建数据框数据 """ 设计数据 """ import pandas as pd data = {&qu ...
- 利用Python进行数据分析-Pandas(第六部分-数据聚合与分组运算)
对数据集进行分组并对各组应用一个函数(无论是聚合还是转换),通常是数据分析工作中的重要环节.在将数据集加载.融合.准备好之后,通常是计算分组统计或生成透视表.pandas提供了一个灵活高效的group ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札97)掌握pandas中的transform
本文示例文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 开门见山,在pandas中,transform是 ...
- (数据科学学习手札99)掌握pandas中的时序数据分组运算
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们在使用pandas分析处理时间序列数据 ...
- MongoDB中的数据聚合工具Aggregate和Group
周煦辰 2016-01-16 来说说MongoDB中的数据聚合工具. Aggregate是MongoDB提供的众多工具中的比较重要的一个,类似于SQL语句中的GROUP BY.聚合工具可以让开发人员直 ...
- 在Pandas中直接加载MongoDB的数据
在使用Pandas进行数据处理的时候,我们通常从CSV或EXCEL中导入数据,但有的时候数据都存在数据库内,我们并没有现成的数据文件,这时候可以通过Pymongo这个库,从mongoDB中读取数据,然 ...
随机推荐
- scikit-learn使用fetch_mldata无法下载MNIST数据集的问题
scikit-learn使用fetch_mldata无法下载MNIST数据集的问题 0. 写在前面 参考书 <Python数据科学手册> 工具 python3.5.1,Jupyter La ...
- jQuery EasyUI/TopJUI输入框事件监听
jQuery EasyUI/TopJUI输入框事件监听 代码如下: <div data-toggle="topjui-panel" title="" da ...
- linux 01 基础命令
linux 01 基础命令 对于Linux要记住一个概念,一切皆文件,哪怕是目录,也是一个文件 1.修改用户密码 sudo passwd pyvip@Vip:~$ #pyvip表示用户名, Vip表示 ...
- BZOJ 1059(二分图匹配)
要点 发现每行每列都得有1 发现无论怎么换,在同一行的永远在同一行,同一列的永远在同一列 于是换行貌似没什么用啊,换列就够了.换列无法做到则无答案 于是变成了行与列进行二分匹配 #include &l ...
- Codeforces 1159E(拓扑序、思路)
要点 序列上各位置之间的关系常用连边的手段转化为图的问题. 经过一番举例探索不难发现当存在两条有向边交叉时是非法的. -1是模糊的,也就是填多少都可以,那为了尽量避免交叉我们贪心地让它后面那个连它就行 ...
- enum StatCode
public enum StatCode { NORMAL(0,"正常"), FLAME_OUT(1,"熄火"), NOT_INSTALL(2,"未安 ...
- ASP .NET Core 2.1 HTTP Error 502.5 – Process Failure
ASP .NET Core HTTP Error 502.5 – Process Failure https://www.cnblogs.com/loui/p/7826073.html 页面返回错误 ...
- Tomcat 下载及配置
1.下载 下载地址:http://tomcat.apache.org/ 进去后下拉到底部 2.解压 Tomcat不需要安装,直接解压即可.解压后会得到这么一个文件夹 3.在MyEclipse中配置To ...
- for循环操作DOM缓存节点长度?
不管是在网上,还是在翻看书籍的时候,都能看到在使用for循环操作DOM节点时要做数节点长度的缓存,以确保性能最优化! 这二种写法格式大致是下面这样的 /*节点集合*/ var domarr=docum ...
- Linux 安装Memcache扩展支持
查看相关软件包 yum search memcached 安装memcache yum -y install memcachedMemcache关联php yum -y install php-pec ...