Spark Structured streaming框架(1)之基本使用
Spark Struntured Streaming是Spark 2.1.0版本后新增加的流计算引擎,本博将通过几篇博文详细介绍这个框架。这篇是介绍Spark Structured Streaming的基本开发方法。以Spark 自带的example进行测试和介绍,其为"StructuredNetworkWordcount.scala"文件。
1. Quick Example
由于我们是在单机上进行测试,所以需要修单机运行模型,修改后的程序如下:
|
package org.apache.spark.examples.sql.streaming import org.apache.spark.sql.SparkSession /** * Counts words in UTF8 encoded, '\n' delimited text received from the network. * * Usage: StructuredNetworkWordCount <hostname> <port> * <hostname> and <port> describe the TCP server that Structured Streaming * would connect to receive data. * * To run this on your local machine, you need to first run a Netcat server * `$ nc -lk 9999` * and then run the example * `$ bin/run-example sql.streaming.StructuredNetworkWordCount * localhost 9999` */ object StructuredNetworkWordCount { def main(args: Array[String]) { if (args.length < 2) { System.err.println("Usage: StructuredNetworkWordCount <hostname> <port>") System.exit(1) } val host = args(0) val port = args(1).toInt val spark = SparkSession .builder .appName("StructuredNetworkWordCount") .master("local[*]") .getOrCreate() import spark.implicits._ // Create DataFrame representing the stream of input lines from connection to host:port val lines = spark.readStream .format("socket") .option("host", host) .option("port", port) .load() // Split the lines into words val words = lines.as[String].flatMap(_.split(" ")) // Generate running word count val wordCounts = words.groupBy("value").count() // Start running the query that prints the running counts to the console val query = wordCounts.writeStream .outputMode("complete") .format("console") .start() query.awaitTermination() } } |
2. 剖析
对于上述所示的程序,进行如下的解读和分析:
2.1 数据输入
在创建SparkSessiion对象之后,需要设置数据源的类型,及数据源的配置。然后就会数据源中源源不断的接收数据,接收到的数据以DataFrame对象存在,该类型与Spark SQL中定义类型一样,内部由Dataset数组组成。
如下程序所示,设置输入源的类型为socket,并配置socket源的IP地址和端口号。接收到的数据流存储到lines对象中,其类型为DataFarme。
|
// Create DataFrame representing the stream of input lines from connection to host:port val lines = spark.readStream .format("socket") .option("host", host) .option("port", port) .load() |
2.2 单词统计
如下程序所示,首先将接受到的数据流lines转换为String类型的序列;接着每一批数据都以空格分隔为独立的单词;最后再对每个单词进行分组并统计次数。
|
// Split the lines into words val words = lines.as[String].flatMap(_.split(" ")) // Generate running word count val wordCounts = words.groupBy("value").count() |
2.3 数据输出
通过DataFrame对象的writeStream方法获取DataStreamWrite对象,DataStreamWrite类定义了一些数据输出的方式。Quick example程序将数据输出到控制终端。注意只有在调用start()方法后,才开始执行Streaming进程,start()方法会返回一个StreamingQuery对象,用户可以使用该对象来管理Streaming进程。如上述程序调用awaitTermination()方法阻塞接收所有数据。
3. 异常
3.1 拒绝连接
当直接提交编译后的架包时,即没有启动"nc –lk 9999"时,会出现图 11所示的错误。解决该异常,只需在提交(spark-submit)程序之前,先启动"nc"命令即可解决,且不能使用"nc –lk localhost 9999".

图 11
3.2 NoSuchMethodError
当通过mvn打包程序后,在命令行通过spark-submit提交架包,能够正常执行,而通过IDEA执行时会出现图 12所示的错误。

图 12
出现这个异常,是由于项目中依赖的Scala版本与Spark编译的版本不一致,从而导致出现这种错误。图 13和图 14所示,Spark 2.10是由Scala 2.10版本编译而成的,而项目依赖的Scala版本是2.11.8,从而导致出现了错误。
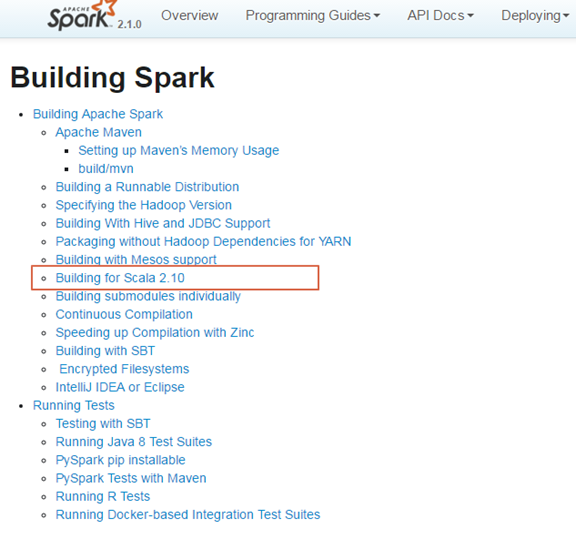
图 13

图 14
解决该问题,只需在项目的pom.xml文件中指定与spark编译的版本一致,即可解决该问题。如图 15所示的执行结果。

图 15
4. 参考文献
Spark Structured streaming框架(1)之基本使用的更多相关文章
- Spark Structured Streaming框架(3)之数据输出源详解
Spark Structured streaming API支持的输出源有:Console.Memory.File和Foreach.其中Console在前两篇博文中已有详述,而Memory使用非常简单 ...
- Spark Structured Streaming框架(1)之基本用法
Spark Struntured Streaming是Spark 2.1.0版本后新增加的流计算引擎,本博将通过几篇博文详细介绍这个框架.这篇是介绍Spark Structured Streamin ...
- Spark Structured Streaming框架(2)之数据输入源详解
Spark Structured Streaming目前的2.1.0版本只支持输入源:File.kafka和socket. 1. Socket Socket方式是最简单的数据输入源,如Quick ex ...
- Spark Structured Streaming框架(2)之数据输入源详解
Spark Structured Streaming目前的2.1.0版本只支持输入源:File.kafka和socket. 1. Socket Socket方式是最简单的数据输入源,如Quick ex ...
- Spark Structured Streaming框架(5)之进程管理
Structured Streaming提供一些API来管理Streaming对象.用户可以通过这些API来手动管理已经启动的Streaming,保证在系统中的Streaming有序执行. 1. St ...
- Spark Structured Streaming框架(4)之窗口管理详解
1. 结构 1.1 概述 Structured Streaming组件滑动窗口功能由三个参数决定其功能:窗口时间.滑动步长和触发时间. 窗口时间:是指确定数据操作的长度: 滑动步长:是指窗口每次向前移 ...
- DataFlow编程模型与Spark Structured streaming
流式(streaming)和批量( batch):流式数据,实际上更准确的说法应该是unbounded data(processing),也就是无边界的连续的数据的处理:对应的批量计算,更准确的说法是 ...
- Spark2.2(三十三):Spark Streaming和Spark Structured Streaming更新broadcast总结(一)
背景: 需要在spark2.2.0更新broadcast中的内容,网上也搜索了不少文章,都在讲解spark streaming中如何更新,但没有spark structured streaming更新 ...
- Spark2.2(三十八):Spark Structured Streaming2.4之前版本使用agg和dropduplication消耗内存比较多的问题(Memory issue with spark structured streaming)调研
在spark中<Memory usage of state in Spark Structured Streaming>讲解Spark内存分配情况,以及提到了HDFSBackedState ...
随机推荐
- Selenium自动化初级/中级网络授课班招生
近期学习selenium和appium的测试人员越来越多,应广大刚接触UI自动化以及对selenium想要更深入了解的测试人员的要求,特请一位资深测试架构师为我们开课讲解selenium,以及如何设计 ...
- python函数(1):初始函数
在学了前面很多python的基础类型后,我们终于可以进入下一阶段,今天我们将走进一个函数的新世界. 预习: 1.写函数,计算传入字符串中[数字].[字母].[空格] 以及 [其他]的个数 2.写函数, ...
- 【SpringMVC】静态资源访问的问题
在项目中经常会用到一些静态的资源,而一般我们在配置SpringMVC时会让SpringMVC接管所有的请求(包括静态资源的访问), 那么我们怎样才能最简单的来配置静态资源的访问呢? 一,在web.xm ...
- ES6数字扩展
前面的话 本文将详细介绍ES6数字扩展 指数运算符 ES2016引入的唯一一个JS语法变化是求幂运算符,它是一种将指数应用于基数的数学运算.JS已有的Math.pow()方法可以执行求幂运算,但它也是 ...
- Redux源码分析之compose
Redux源码分析之基本概念 Redux源码分析之createStore Redux源码分析之bindActionCreators Redux源码分析之combineReducers Redux源码分 ...
- SSE再学习:灵活运用SIMD指令6倍提升Sobel边缘检测的速度(4000*3000的24位图像时间由180ms降低到30ms)。
这半年多时间,基本都在折腾一些基本的优化,有很多都是十几年前的技术了,从随大流的角度来考虑,研究这些东西在很多人看来是浪费时间了,即不能赚钱,也对工作能力提升无啥帮助.可我觉得人类所谓的幸福,可以分为 ...
- 在Navicat 中给Mysql中的某字段添加前缀00
第一次分享心得,希望大家多多关注. 我遇到的情况是这样的,在Navicat中某表的varchar字段内容长度不够5的在内容前面添加‘0’:如字段内容是 101 我就要改成00101: 其中有2个难点: ...
- C语言开发面试题
(以下是题主参加的一家偏向Linux平台开发的公司软件岗位笔试题,分享原题,后面附上题主91分的部分参考答案^V^) 一.(8分)请问一下程序输出什么结果? char *getStr(void) { ...
- POJ3614 Sunscreen 优先队列+贪心
Description To avoid unsightly burns while tanning, each of the C (1 ≤ C ≤ 2500) cows must cover her ...
- 分布式事务,EventBus 解决方案:CAP【中文文档】
前言 很多同学想对CAP的机制以及用法等想有一个详细的了解,所以花了将近两周时间写了这份中文的CAP文档,对 CAP 还不知道的同学可以先看一下这篇文章. 本文档为 CAP 文献(Wiki),本文献同 ...