Spark学习之路(十三)—— Spark Streaming 与流处理
一、流处理
1.1 静态数据处理
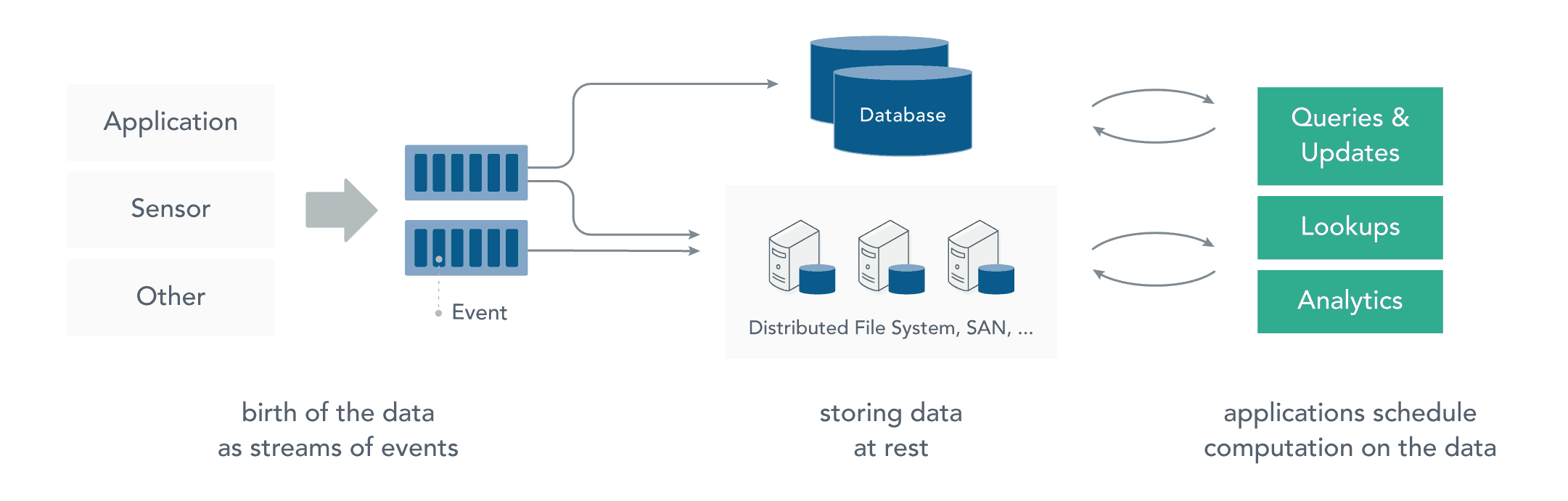
在流处理之前,数据通常存储在数据库,文件系统或其他形式的存储系统中。应用程序根据需要查询数据或计算数据。这就是传统的静态数据处理架构。Hadoop采用HDFS进行数据存储,采用MapReduce进行数据查询或分析,这就是典型的静态数据处理架构。
1.2 流处理
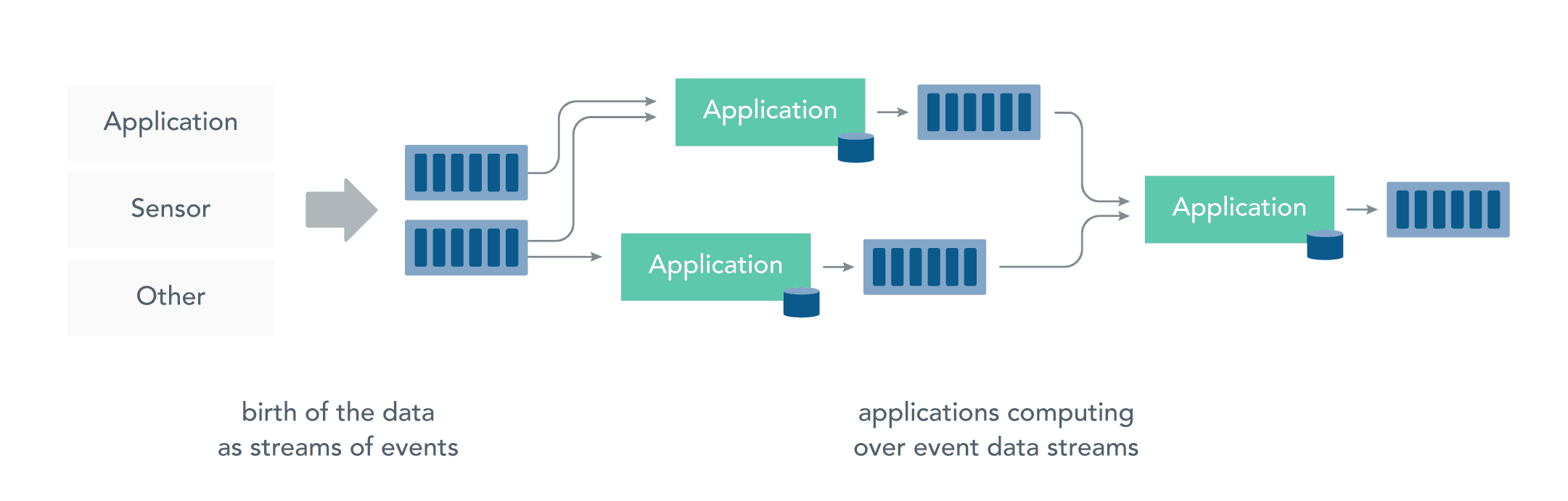
而流处理则是直接对运动中的数据的处理,在接收数据时直接计算数据。
大多数数据都是连续的流:传感器事件,网站上的用户活动,金融交易等等 ,所有这些数据都是随着时间的推移而创建的。
接收和发送数据流并执行应用程序或分析逻辑的系统称为流处理器。流处理器的基本职责是确保数据有效流动,同时具备可扩展性和容错能力,Storm和Flink就是其代表性的实现。
流处理带来了静态数据处理所不具备的众多优点:
- 应用程序立即对数据做出反应:降低了数据的滞后性,使得数据更具有时效性,更能反映对未来的预期;
- 流处理可以处理更大的数据量:直接处理数据流,并且只保留数据中有意义的子集,并将其传送到下一个处理单元,逐级过滤数据,降低需要处理的数据量,从而能够承受更大的数据量;
- 流处理更贴近现实的数据模型:在实际的环境中,一切数据都是持续变化的,要想能够通过过去的数据推断未来的趋势,必须保证数据的不断输入和模型的不断修正,典型的就是金融市场、股票市场,流处理能更好的应对这些数据的连续性的特征和及时性的需求;
- 流处理分散和分离基础设施:流式处理减少了对大型数据库的需求。相反,每个流处理程序通过流处理框架维护了自己的数据和状态,这使得流处理程序更适合微服务架构。
二、Spark Streaming
2.1 简介
Spark Streaming是Spark的一个子模块,用于快速构建可扩展,高吞吐量,高容错的流处理程序。具有以下特点:
- 通过高级API构建应用程序,简单易用;
- 支持多种语言,如Java,Scala和Python;
- 良好的容错性,Spark Streaming支持快速从失败中恢复丢失的操作状态;
- 能够和Spark其他模块无缝集成,将流处理与批处理完美结合;
- Spark Streaming可以从HDFS,Flume,Kafka,Twitter和ZeroMQ读取数据,也支持自定义数据源。

2.2 DStream
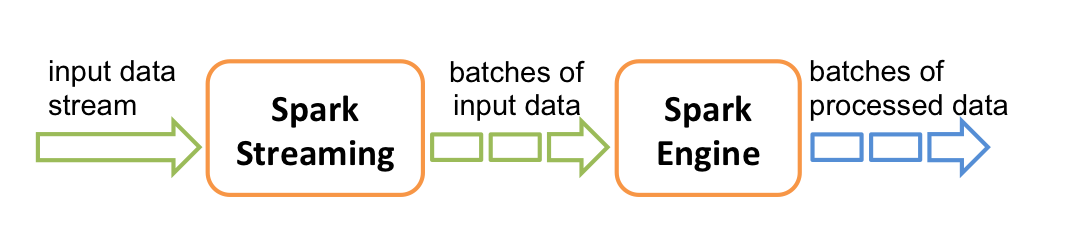
Spark Streaming提供称为离散流(DStream)的高级抽象,用于表示连续的数据流。 DStream可以从来自Kafka,Flume和Kinesis等数据源的输入数据流创建,也可以由其他DStream转化而来。在内部,DStream表示为一系列RDD。
2.3 Spark & Storm & Flink
storm和Flink都是真正意义上的流计算框架,但 Spark Streaming 只是将数据流进行极小粒度的拆分,拆分为多个批处理,使得其能够得到接近于流处理的效果,但其本质上还是批处理(或微批处理)。
参考资料
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Spark学习之路(十三)—— Spark Streaming 与流处理的更多相关文章
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习之路 (二十三)SparkStreaming的官方文档
一.SparkCore.SparkSQL和SparkStreaming的类似之处 二.SparkStreaming的运行流程 2.1 图解说明 2.2 文字解说 1.我们在集群中的其中一台机器上提交我 ...
- Spark学习之路(十六)—— Spark Streaming 整合 Kafka
一.版本说明 Spark针对Kafka的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8和spark-streaming-kafka-0-10,其主要区别如下: s ...
- Spark学习之路(十五)—— Spark Streaming 整合 Flume
一.简介 Apache Flume是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming提供了以下两种方式用于Flu ...
- Spark学习之路(十四)—— Spark Streaming 基本操作
一.案例引入 这里先引入一个基本的案例来演示流的创建:获取指定端口上的数据并进行词频统计.项目依赖和代码实现如下: <dependency> <groupId>org.apac ...
- Spark学习之路 (二十三)SparkStreaming的官方文档[转]
SparkCore.SparkSQL和SparkStreaming的类似之处 SparkStreaming的运行流程 1.我们在集群中的其中一台机器上提交我们的Application Jar,然后就会 ...
- Spark学习之路 (一)Spark初识
目录 一.官网介绍 1.什么是Spark 二.Spark的四大特性 1.高效性 2.易用性 3.通用性 4.兼容性 三.Spark的组成 四.应用场景 正文 回到顶部 一.官网介绍 1.什么是Spar ...
- Spark学习之路 (二十二)SparkStreaming的官方文档
官网地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html 一.简介 1.1 概述 Spark Streamin ...
- Spark学习之路 (一)Spark初识 [转]
官网介绍 什么是Spark 官网地址:http://spark.apache.org/ Apache Spark™是用于大规模数据处理的统一分析引擎. 从右侧最后一条新闻看,Spark也用于AI人工智 ...
随机推荐
- iText 制作PDF
前言 由于在MVC项目中需要使用PDF,所以自己抽空也来看看itext,以便于丰富自己的知识吧.在此也简单的记录一下,说不定以后可能还用的到. 在此您可以下载你想使用的版本http://sourcef ...
- uwp - 做一个相对炫酷的动画按钮/按钮动画
原文:uwp - 做一个相对炫酷的动画按钮/按钮动画 看腻了系统自带的button animation何不尝试下自定义一个较为炫酷的动画顺便提升用户体验.效果图: 动画分为几个部分,分别是:内圆从中心 ...
- CentOS(一) 最小化安装
/etc/sysconfig/selinux 关闭selinux /etc/sysconfig/network-scripts/网卡 设置onboot=yes service network re ...
- Leetcode 268 Missing Number 位运算
题意:先将0, 1, 2, ..., n放入数组,然后去掉其中一个值,找到那个值. 这题与singe number 是一个类型,变形的地方就是首先需要将0, 1, 2, ..., n再次放入这个数组, ...
- 用ORACHK自己主动化检查数据库系统的健壮性
1.orachk工具主要用途 (1)主动检查您的整个软件在操作系统.CRS.数据库.高可用等层面中的严重问题,以便于IT部门整改,提升系统的稳定性 (2)对于您系统中存在的风险提供简单化和合理化的诊断 ...
- 《Linux Device Drivers》第十一章 核心数据类型——note
基本介绍 因为Linux多平台特性,不管是哪一个重要驱动力应该是便携 与内核代码相关的核心问题应该是访问的同时是数据项的已知长度.能力和利用不同的处理器 内核使用的数据类型主要分为三类 类似int这种 ...
- VC6下深入理解new[]和delete[](在多线程下new和delete的时候,必须选择上多线程库,不然可能造成进程崩溃)
多少年了,一直处于C与C++混用的状态,申请空间一直用malloc,释放空间一直用free,为什么?因为他们好理解易操作,就如同输出一直用printf而不用<<,输入一直用scanf而不用 ...
- 写在程序猿的困惑(特别Java程序猿)入行一年,感觉我不知道接下来该怎么办才能不断进步的,寻求翼
入行了一年.感觉不知道接下来该怎么做才干继续进步了,求不吝赐教(V2EX) @kafka0102 :做技术能够学的东西太多了.仅仅是在不同的阶段做好不同的规划.要结合当前所做的事情去做更深入或广度的学 ...
- 不使用运算符(+、-、*、/) 来进行四则运算(C#)
最近在LeetCode 上刷题,遇到一个非常有趣的题目,题目的大概意思就是在不使用运算符的情况下实现两个数的加法...原题点这里>>> 说实话,刚看到这题目,我是一脸懵逼的. 后来仔 ...
- css 浏览器兼容性问题解决
一个.!important (功能有限) 随着IE7正确!important支持, !important 方法现在只IE6兼容.(注意措辞.我记得这句话需要推进的位置.) : #example ...