Spark Streaming vs. Structured Streaming
简介
Spark Streaming
Spark Streaming是spark最初的流处理框架,使用了微批的形式来进行流处理。
提供了基于RDDs的Dstream API,每个时间间隔内的数据为一个RDD,源源不断对RDD进行处理来实现流计算
Structured Streaming
Spark 2.X出来的流框架,采用了无界表的概念,流数据相当于往一个表上不断追加行。
基于Spark SQL引擎实现,可以使用大多数Spark SQL的function
区别
1. 流模型
Spark Streaming

Spark Streaming采用微批的处理方法。每一个批处理间隔的为一个批,也就是一个RDD,我们对RDD进行操作就可以源源不断的接收、处理数据。
spark streaming微批终是批
Structured Streaming
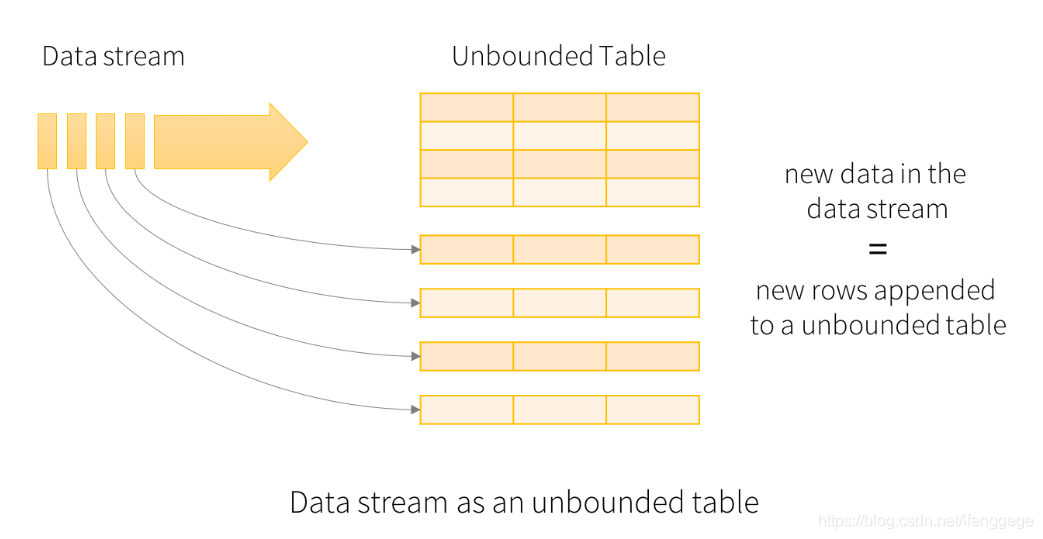
Structured Streaming is to treat a live data stream as a table that is being continuously appended
Structured Streaming将实时数据当做被连续追加的表。流上的每一条数据都类似于将一行新数据添加到表中。
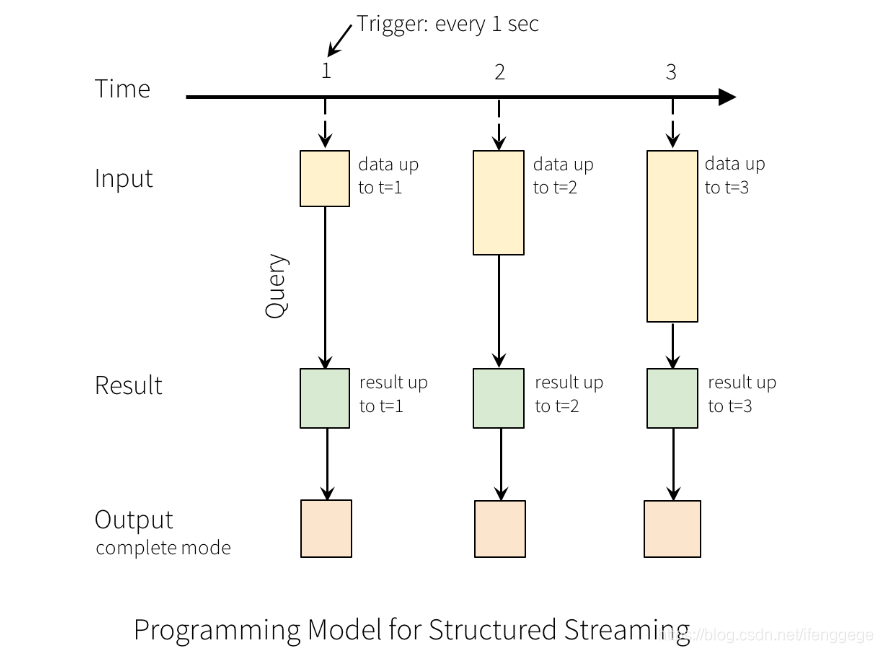
以上图为例,每隔1秒从输入源获取数据到Input Table,并触发Query计算,然后将结果写入Result Table,之后根据指定的Output模式进行写出。
上面的1秒是指定的触发间隔(trigger interval),如果不指定的话,先前数据的处理完成后,系统将立即检查是否有新数据。
需要注意的是,Spark Streaming本身设计就是一批批的以批处理间隔划分RDD;而Structured Streaming中并没有提出批的概念,Structured Streaming按照每个Trigger Interval接收数据到Input Table,将数据处理后再追加到无边界的Result Table中,想要何种方式输出结果取决于指定的模式。所以,虽说Structured Streaming也有类似于Spark Streaming的Interval,其本质概念是不一样的。Structured Streaming更像流模式。
2. RDD vs. DataFrame、DataSet
Spark Streaming中的DStream编程接口是RDD,我们需要对RDD进行处理,处理起来较为费劲且不美观。
stream.foreachRDD(rdd => {
balabala(rdd)
})
Structured Streaming使用DataFrame、DataSet的编程接口,处理数据时可以使用Spark SQL中提供的方法,数据的转换和输出会变得更加简单。
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "hadoop01:9092")
.option("subscribe", "order_data")
.load()
.select($"value".cast("string"))
.as[String]
.writeStream
.outputMode("complete")
.format("console")
3. Process Time vs. Event Time
Process Time:流处理引擎接收到数据的时间
Event Time:时间真正发生的时间
Spark Streaming中由于其微批的概念,会将一段时间内接收的数据放入一个批内,进而对数据进行处理。划分批的时间是Process Time,而不是Event Time,Spark Streaming没有提供对Event Time的支持。
Structured Streaming提供了基于事件时间处理数据的功能,如果数据包含事件的时间戳,就可以基于事件时间进行处理。
这里以窗口计数为例说明一下区别:
我们这里以10分钟为窗口间隔,5分钟为滑动间隔,每隔5分钟统计过去10分钟网站的pv
假设有一些迟到的点击数据,其本身事件时间是12:01,被spark接收到的时间是12:11;在spark streaming的统计中,会毫不犹豫的将它算作是12:05-12:15这个范围内的pv,这显然是不恰当的;在structured streaming中,可以使用事件时间将它划分到12:00-12:10的范围内,这才是我们想要的效果。
4. 可靠性保障
两者在可靠性保证方面都是使用了checkpoint机制。
checkpoint通过设置检查点,将数据保存到文件系统,在出现出故障的时候进行数据恢复。
在spark streaming中,如果我们需要修改流程序的代码,在修改代码重新提交任务时,是不能从checkpoint中恢复数据的(程序就跑不起来),是因为spark不认识修改后的程序了。
在structured streaming中,对于指定的代码修改操作,是不影响修改后从checkpoint中恢复数据的。具体可参见文档。
5. sink
二者的输出数据(写入下游)的方式有很大的不同。
spark streaming中提供了foreachRDD()方法,通过自己编程实现将每个批的数据写出。
stream.foreachRDD(rdd => {
save(rdd)
})
structured streaming自身提供了一些sink(Console Sink、File Sink、Kafka Sink等),只要通过option配置就可以使用;对于需要自定义的Sink,提供了ForeachWriter的编程接口,实现相关方法就可以完成。
// console sink
val query = res
.writeStream
.outputMode("append")
.format("console")
.start()
最后
总体来说,structured streaming有更简洁的API、更完善的流功能、更适用于流处理。而spark streaming,更适用于与偏批处理的场景。
在流处理引擎方面,flink最近也很火,值得我们去学习一番。
reference
https://blog.knoldus.com/spark-streaming-vs-structured-streaming/
https://dzone.com/articles/spark-streaming-vs-structured-streaming
https://spark.apache.org/docs/2.0.2/streaming-programming-guide.html
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
以上为个人理解,如有不对的地方,欢迎交流指正。

个人公众号:码农峰,推送最新行业资讯,每周发布原创技术文章,欢迎大家关注。
Spark Streaming vs. Structured Streaming的更多相关文章
- DataFlow编程模型与Spark Structured streaming
流式(streaming)和批量( batch):流式数据,实际上更准确的说法应该是unbounded data(processing),也就是无边界的连续的数据的处理:对应的批量计算,更准确的说法是 ...
- Spark之Structured Streaming
目录 Part V. Streaming Stream Processing Fundamentals Structured Streaming Basics Event-Time and State ...
- Spark学习进度11-Spark Streaming&Structured Streaming
Spark Streaming Spark Streaming 介绍 批量计算 流计算 Spark Streaming 入门 Netcat 的使用 项目实例 目标:使用 Spark Streaming ...
- Structured Streaming编程 Programming Guide
Structured Streaming编程 Programming Guide Overview Quick Example Programming Model Basic Concepts Han ...
- Spark Streaming揭秘 Day29 深入理解Spark2.x中的Structured Streaming
Spark Streaming揭秘 Day29 深入理解Spark2.x中的Structured Streaming 在Spark2.x中,Spark Streaming获得了比较全面的升级,称为St ...
- Spark Structured streaming框架(1)之基本使用
Spark Struntured Streaming是Spark 2.1.0版本后新增加的流计算引擎,本博将通过几篇博文详细介绍这个框架.这篇是介绍Spark Structured Streamin ...
- Spark Structured Streaming框架(2)之数据输入源详解
Spark Structured Streaming目前的2.1.0版本只支持输入源:File.kafka和socket. 1. Socket Socket方式是最简单的数据输入源,如Quick ex ...
- Spark2.3(四十二):Spark Streaming和Spark Structured Streaming更新broadcast总结(二)
本次此时是在SPARK2,3 structured streaming下测试,不过这种方案,在spark2.2 structured streaming下应该也可行(请自行测试).以下是我测试结果: ...
- Spark2.2(三十三):Spark Streaming和Spark Structured Streaming更新broadcast总结(一)
背景: 需要在spark2.2.0更新broadcast中的内容,网上也搜索了不少文章,都在讲解spark streaming中如何更新,但没有spark structured streaming更新 ...
随机推荐
- zabbix 发送报警邮件
- Java描述设计模式(24):备忘录模式
本文源码:GitHub·点这里 || GitEE·点这里 一.生活场景 1.场景描述 常见的视频播放软件都具备这样一个功能:假设在播放视频西游记,如果这时候切换播放视频红楼梦,当再次切回播放西游记时, ...
- java之初见
1.Java语言的了解: Java语言最早是由SUN公司创造出来的,1991年,SUN公司的green项目,Oak,随后SUN公司和后来的甲骨文公司又先后发布了java1.0,1.1,1.2,1.3, ...
- 快速入门函数式编程——以Javascript为例
函数式编程是在不改变状态和数据的情况下使用表达式和函数来编写程序的一种编程范式.通过遵守这种范式,我们能够编写更清晰易懂.更能抵御bug的代码.这是通过避免使用流控制语句(for.while.brea ...
- day 33 线程锁
Python的GIL锁 - Python内置的一个全局解释器锁,锁的作用就是保证同一时刻一个进程中只有一个线程可以被cpu调度. 为什么有这把GIL锁? 答:Python语言的创始人在开发这门语言时, ...
- Flink中的CEP复杂事件处理 (源码分析)
其实CEP复杂事件处理,简单来说你可以用通过类似正则表达式的方式去表示你的逻辑,表现能力非常的强,用过的人都知道 开篇先偷一张图,整体了解Flink中的CEP中的 一种重要的图 NFA非确定有限状 ...
- Django总结目录
Django总结目录 1. django框架简介及自定义简易版框架 2. 路由层 3. 视图层 4. 模板层 5. 模型层 5.1 基本操作 5.2 多表操作 5.3 进阶相关 6. 组件 6.1 a ...
- while(cin)?
#include<iostream> #include<utility> using namespace std; int main() { int i; do { cout& ...
- scrapy请求传参-BOSS反爬
scrapy请求传参-BOSS反爬 思路总结 首先boss加了反爬 是cookies的 爬取的内容为职位和职位描述 # -*- coding: utf-8 -*- import scrapy from ...
- python函数-参数
python函数-参数 实验室 # 演示形参是可变类型 def register(name, hobby, hobby_list=[]): hobby_list.append(hobby) print ...