如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门。不过不要慌,小编在网上找到了第三方工具,它可以将朋友圈进行导出,之后便可以像我们正常爬虫网页一样进行抓取信息了。
【出书啦】就提供了这样一种服务,支持朋友圈导出,并排版生成微信书。本文的主要参考资料来源于这篇博文:https://www.cnblogs.com/sheng-jie/p/7776495.html ,感谢大佬提供的接口和思路。具体的教程如下。
一、获取朋友圈数据入口
1、关注公众号【出书啦】

2、之后在主页中点击【创作书籍】-->【微信书】。
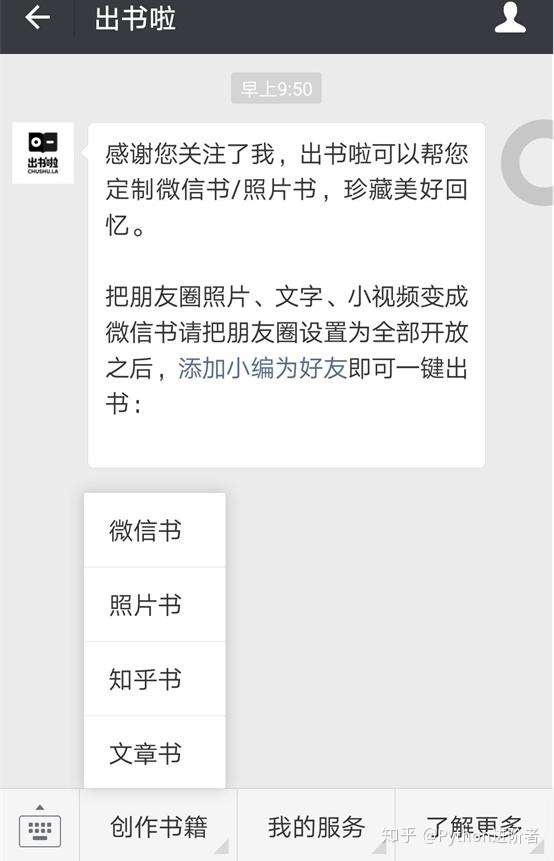
3、点击【开始制作】-->【添加随机分配的出书啦小编为好友即可】,长按二维码之后便可以进行添加好友了。
4、之后耐心等待微信书制作,待完成之后,会收到小编发送的消息提醒,如下图所示。
至此,我们已经将微信朋友圈的数据入口搞定了,并且获取了外链。
确保朋友圈设置为【全部开放】,默认就是全部开放,如果不知道怎么设置的话,请自行百度吧。
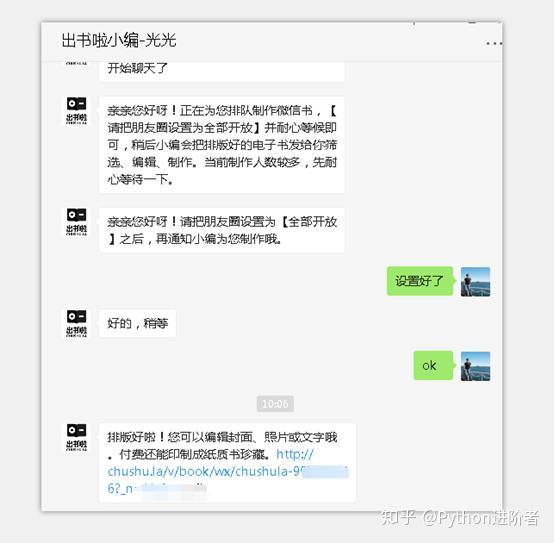
5、点击该外链,之后进入网页,需要使用微信扫码授权登录。
6、扫码授权之后,就可以进入到微信书网页版了,如下图所示。
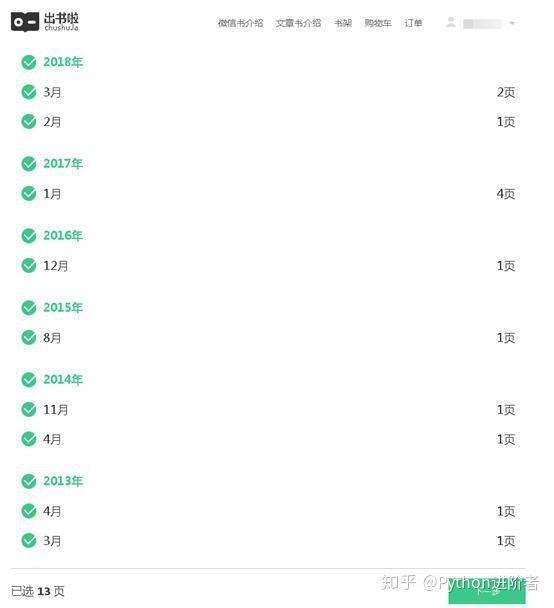
7、接下来我们就可以正常的写爬虫程序进行抓取信息了。在这里,小编采用的是Scrapy爬虫框架,Python用的是3版本,集成开发环境用的是Pycharm。下图是微信书的首页,图片是小编自己自定义的。

二、创建爬虫项目
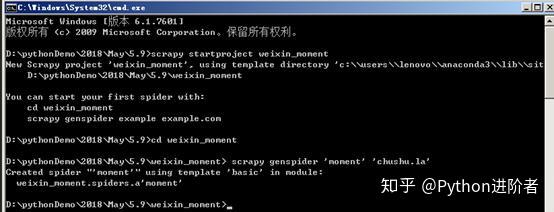
1、确保您的电脑上已经安装好了Scrapy。之后选定一个文件夹,在该文件夹下进入命令行,输入执行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬虫项目。
2、在命令行中输入cd weixin_moment,进入创建的weixin_moment目录。之后输入命令:
scrapy genspider 'moment' 'chushu.la'
,创建朋友圈爬虫,如下图所示。
3、执行以上两步后的文件夹结构如下:
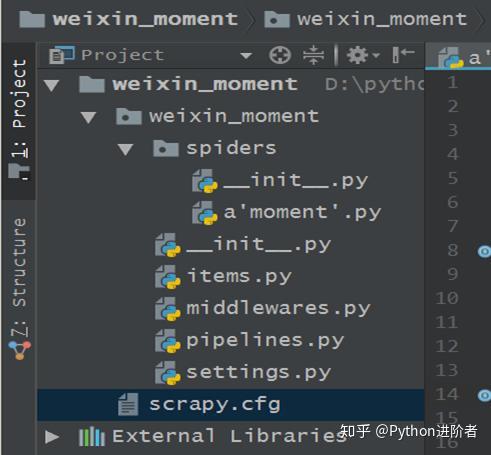
三、分析网页数据
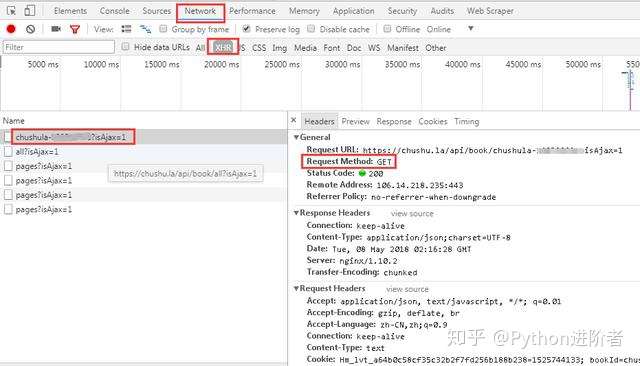
1、进入微信书首页,按下F12,建议使用谷歌浏览器,审查元素,点击“Network”选项卡,然后勾选“Preserve log”,表示保存日志,如下图所示。可以看到主页的请求方式是get,返回的状态码是200,代表请求成功。
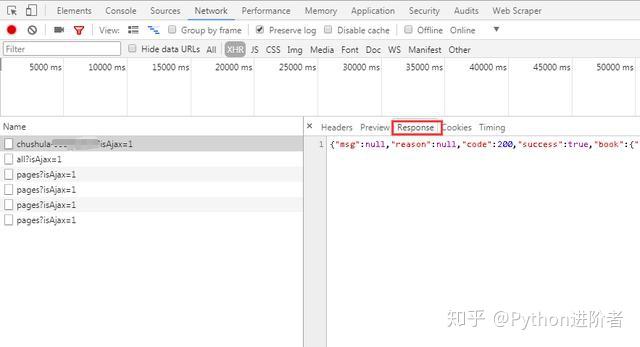
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明我们之后在程序中需要对JSON格式的数据进行处理。
3、点击微信书的“导航”窗口,可以看到数据是按月份进行加载的。当点击导航按钮,其加载对应月份的朋友圈数据。
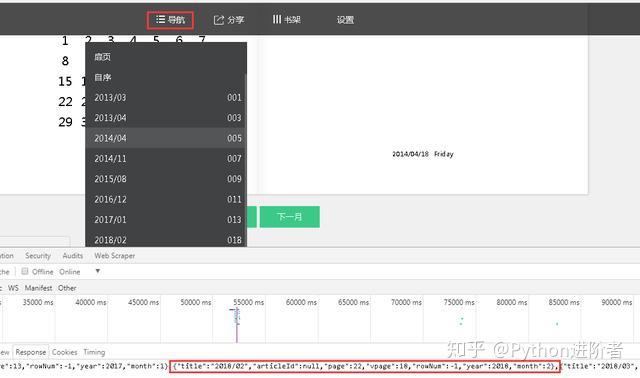
4、当点击【2014/04】月份,之后查看服务器响应数据,可以看到页面上显示的数据和服务器的响应是相对应的。
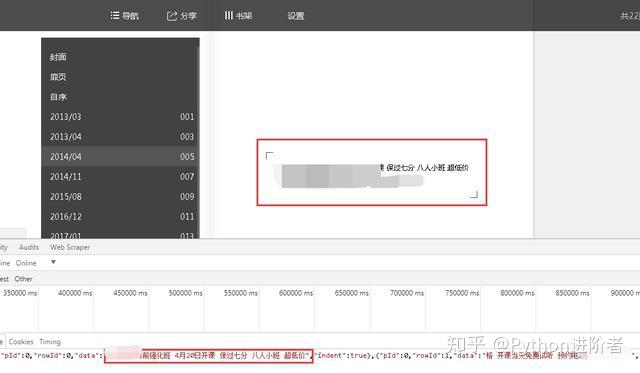
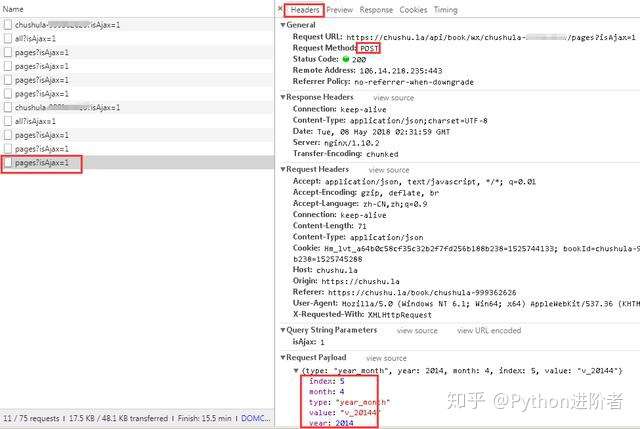
5、查看请求方式,可以看到此时的请求方式变成了POST。细心的伙伴可以看到在点击“下个月”或者其他导航月份的时候,主页的URL是始终没有变化的,说明该网页是动态加载的。之后对比多个网页请求,我们可以看到在“Request Payload”下边的数据包参数不断的发生变化,如下图所示。
6、展开服务器响应的数据,将数据放到JSON在线解析器里,如下图所示:
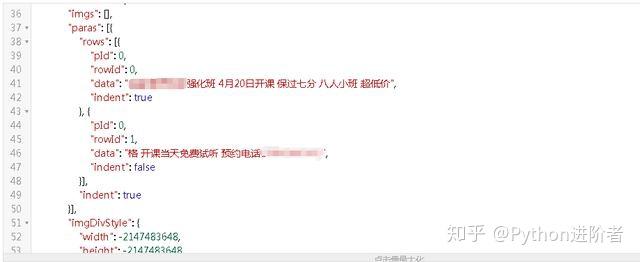
可以看到朋友圈的数据存储在paras /data节点下。
至此,网页分析和数据的来源都已经确定好了,接下来将写程序,进行数据抓取,敬请期待下篇文章~~
如何利用Python网络爬虫抓取微信朋友圈的动态(上)的更多相关文章
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例
前几天给大家分享了利用Python网络爬虫抓取微信朋友圈的动态(上)和利用Python网络爬虫爬取微信朋友圈动态——附代码(下),并且对抓取到的数据进行了Python词云和wordart可视化,感兴趣 ...
- 利用Python网络爬虫抓取微信好友的签名及其可视化展示
前几天给大家分享了如何利用Python词云和wordart可视化工具对朋友圈数据进行可视化,利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,以及利用Python网络爬虫抓取微信好友的所 ...
- 利用Python网络爬虫抓取微信好友的所在省位和城市分布及其可视化
前几天给大家分享了如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,感兴趣的小伙伴可以点击链接进行查看.今天小编给大家介绍如何利用Python网络爬虫抓取微信好友的省位和城市,并且将 ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- python网络爬虫抓取动态网页并将数据存入数据库MySQL
简述以下的代码是使用python实现的网络爬虫,抓取动态网页 http://hb.qq.com/baoliao/ .此网页中的最新.精华下面的内容是由JavaScript动态生成的.审查网页元素与网页 ...
- python网络爬虫抓取网站图片
本文介绍两种爬取方式: 1.正则表达式 2.bs4解析Html 以下为正则表达式爬虫,面向对象封装后的代码如下: import urllib.request # 用于下载图片 import os im ...
- 基于Thinkphp5+phpQuery 网络爬虫抓取数据接口,统一输出接口数据api
TP5_Splider 一个基于Thinkphp5+phpQuery 网络爬虫抓取数据接口 统一输出接口数据api.适合正在学习Vue,AngularJs框架学习 开发demo,需要接口并保证接口不跨 ...
- 利用Python网络爬虫采集天气网的实时信息—BeautifulSoup选择器
相信小伙伴们都知道今冬以来范围最广.持续时间最长.影响最重的一场低温雨雪冰冻天气过程正在进行中.预计,今天安徽.江苏.浙江.湖北.湖南等地有暴雪,局地大暴雪,新增积雪深度4-8厘米,局地可达10-20 ...
随机推荐
- PCA与特征选取
一.什么是PCA PCA,即PrincipalComponents Analysis,也就是主成份分析: 通俗的讲,就是寻找一系列的投影方向,高维数据按照这些方向投影后其方差最大化(方差最大的即是第一 ...
- python的read() 、readline()、readlines()、xreadlines()
先来一个小例子: import sys dir= os.path.dirname(os.path.abspath(__file__)) file_path='%s/test.txt' % dir f ...
- MySQL学习笔记_6_SQL语言的设计与编写(下)
SQL语言的设计与编写(下) --SELECT查询精讲 概要: SELECT[ALL | DISTINCT] #distinct 明显的,清楚的,有区别的 {*|table.*|[table.]fie ...
- javascript语法之流程控制语句
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- ORACLE里锁有以下几种模式,v$locked_object,locked_mode
ORACLE里锁有以下几种模式: 0:none 1:null 空 2:Row-S 行共享(RS):共享表锁,sub share 3:Row-X 行独占(RX):用于行的修改,sub exclusiv ...
- Android开发艺术探索——新的征程,程序人生路漫漫!
Android开发艺术探索--新的征程,程序人生路漫漫! 偶尔写点东西分享,但是我还是比较喜欢写笔记,看书,群英传看完了,是学到了点东西,开始看这本更加深入Android的书籍了,不知道适不适合自己, ...
- [Ext.Net]动态生成控件(二)--js动态添加文本框
转自:http://www.ext.net.cn/forum.php?mod=viewthread&tid=11931 点击一个按钮就出现一行控件,点击删除控件就可将一行控件删除,这是不是你一 ...
- Binder和SurfaceFlinger以及SystemServer介绍-android学习之旅(79)
由于binder机制的存在,使得进程A可以访问进程B中的对象. Android系统Binder机制中的四个组件Client.Server.Service Manager和Binder驱动程序: 1. ...
- Android中怎样获取SD卡路径
很多时候我们需要将我们的数据或者apk保存到SD卡中,但是使用绝对路径可能会遇到错误,怎样解决这个问题呢? 可以通过以下方法获取SD卡的路径: Environment.getExternalS ...
- Swing组件 创建窗口应用
package com.swing; import java.awt.BorderLayout; import java.awt.event.ActionEvent; import java.awt. ...