评估指标【交叉验证&ROC曲线】
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 10 11:21:27 2018 @author: zhen
"""
from sklearn.datasets import fetch_mldata
import numpy as np
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import precision_recall_curve
import matplotlib
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
from sklearn.ensemble import RandomForestClassifier mnist = fetch_mldata('MNIST original', data_home='D:/AnalyseData学习资源库/人工智能开发/分类评估/资料/test_data_home') x, y = mnist['data'], mnist['target']
some_digit = x[36000] #获取第36000行数据 some_digit_image = some_digit.reshape(28, 28) plt.imshow(some_digit_image, cmap=matplotlib.cm.binary,
interpolation='nearest', vmin=0, vmax=1)
plt.axis('off')
plt.show() x_train, x_test, y_train, y_test = x[:60000], x[60000:], y[:60000], y[60000:]
shuffle_index = np.random.permutation(60000) x_train, y_train = x_train[shuffle_index], y_train[shuffle_index] y_train_5 = (y_train == 5)
y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(loss='log', random_state=42, max_iter=1000, tol=1e-4)
sgd_clf.fit(x_train, y_train_5) result = sgd_clf.predict([some_digit]) print(cross_val_score(sgd_clf, x_train, y_train_5, cv=3, scoring='accuracy'))
print(cross_val_score(sgd_clf, x_train, y_train_5, cv=3, scoring='precision'))
print(cross_val_score(sgd_clf, x_train, y_train_5, cv=3, scoring='recall')) sgd_clf.fit(x_train, y_train_5) y_scores = sgd_clf.decision_function([some_digit]) threshold = 0
y_some_digit_pred = (y_scores > threshold) threshold = 200000
y_some_digit_pred = (y_scores > threshold) # cv 数据集划分的个数
y_scores = cross_val_predict(sgd_clf, x_train, y_train_5, cv=3, method='decision_function') precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores) def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
plt.plot(thresholds, precisions[:-1], 'b--',label='Precision')
plt.plot(thresholds, recalls[:-1], 'r--', label='Recall')
plt.xlabel("Threshold")
plt.legend(loc='upper left')
plt.ylim([0, 1])
plt.show() def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label='roc')
plt.plot([0, 1], [0, 1], 'k--', label='mid')
plt.legend(loc='lower right')
# plt.axes([0, 1, 0, 1]) : 前两个参数表示坐标原点的位置,后两个表示x,y轴的长度
plt.xlabel('fpr')
plt.ylabel('tpr')
plt.show() plot_precision_recall_vs_threshold(precisions, recalls, thresholds) fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
plot_roc_curve(fpr, tpr) print(roc_auc_score(y_train_5, y_scores)) forest_clf = RandomForestClassifier(random_state=42)
y_probas_forest = cross_val_predict(forest_clf, x_train, y_train_5, cv=3, method='predict_proba')
y_scores_forest = y_probas_forest[:, 1]
fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5, y_scores_forest)
plt.plot(fpr, tpr, 'b:', label='SGD')
plt.plot(fpr_forest, tpr_forest, label='Random Forest')
plt.legend(loc='lower right')
plt.show() print(roc_auc_score(y_train_5, y_scores_forest))

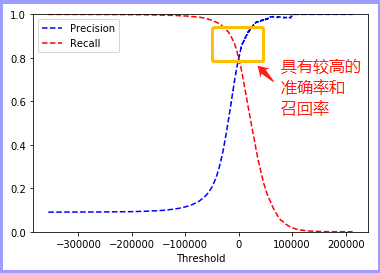
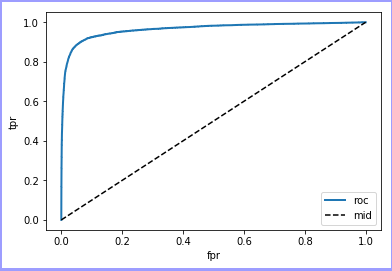
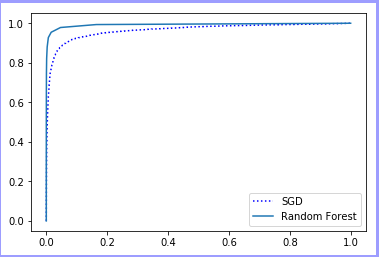
总结:正向准确率和召回率在整体上成反比,可知在使用相同数据集,相同验证方式的情况下,随机森林要优于随机梯度下降!
评估指标【交叉验证&ROC曲线】的更多相关文章
- 【分类模型评判指标 二】ROC曲线与AUC面积
转自:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80499031 略有改动,仅供个人学习使用 简介 ROC曲线与AUC面积均是用来 ...
- 【机器学习】--模型评估指标之混淆矩阵,ROC曲线和AUC面积
一.前述 怎么样对训练出来的模型进行评估是有一定指标的,本文就相关指标做一个总结. 二.具体 1.混淆矩阵 混淆矩阵如图: 第一个参数true,false是指预测的正确性. 第二个参数true,p ...
- 评价指标的局限性、ROC曲线、余弦距离、A/B测试、模型评估的方法、超参数调优、过拟合与欠拟合
1.评价指标的局限性 问题1 准确性的局限性 准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷.比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率.所以,当 ...
- 评估指标:ROC,AUC,Precision、Recall、F1-score
一.ROC,AUC ROC(Receiver Operating Characteristic)曲线和AUC常被用来评价一个二值分类器(binary classifier)的优劣 . ROC曲线一般的 ...
- 召回率、AUC、ROC模型评估指标精要
混淆矩阵 精准率/查准率,presicion 预测为正的样本中实际为正的概率 召回率/查全率,recall 实际为正的样本中被预测为正的概率 TPR F1分数,同时考虑查准率和查全率,二者达到平衡,= ...
- PR曲线,ROC曲线,AUC指标等,Accuracy vs Precision
作为机器学习重要的评价指标,标题中的三个内容,在下面读书笔记里面都有讲: http://www.cnblogs.com/charlesblc/p/6188562.html 但是讲的不细,不太懂.今天又 ...
- 从TP、FP、TN、FN到ROC曲线、miss rate、行人检测评估
从TP.FP.TN.FN到ROC曲线.miss rate.行人检测评估 想要在行人检测的evaluation阶段要计算miss rate,就要从True Positive Rate讲起:miss ra ...
- [机器学习] 性能评估指标(精确率、召回率、ROC、AUC)
混淆矩阵 介绍这些概念之前先来介绍一个概念:混淆矩阵(confusion matrix).对于 k 元分类,其实它就是一个k x k的表格,用来记录分类器的预测结果.对于常见的二元分类,它的混淆矩阵是 ...
- 机器学习 - 案例 - 样本不均衡数据分析 - 信用卡诈骗 ( 标准化处理, 数据不均处理, 交叉验证, 评估, Recall值, 混淆矩阵, 阈值 )
案例背景 银行评判用户的信用考量规避信用卡诈骗 ▒ 数据 数据共有 31 个特征, 为了安全起见数据已经向了模糊化处理无法读出真实信息目标 其中数据中的 class 特征标识为是否正常用户 (0 代表 ...
随机推荐
- SLAM+语音机器人DIY系列:(五)树莓派3开发环境搭建——1.安装系统ubuntu_mate_16.04
摘要 通过前面一系列的铺垫,相信大家对整个miiboo机器人的DIY有了一个清晰整体的认识.接下来就正式进入机器人大脑(嵌入式主板:树莓派3)的开发.本章将从树莓派3的开发环境搭建入手,为后续ros开 ...
- Hibernate学习——持久化类的学习
A.概念 持久化:将内存中的对象持久化(存储)到数据库的过程.Hibernate就是持久化的框架. 持久化类:一个普通java对象与数据库的表建立了映射关系,那么这个类在Hiberna中被称为持久化类 ...
- 结合JDK源码看设计模式——组合模式
前言: 相信大家都打开过层级很多很多的文件夹.如果把第一个文件夹看作是树的根节点的话,下面的子文件夹就可以看作一个子节点.不过最终我们寻找的还是文件夹中的文件,文件可以看做是叶子节点.下面我们介绍一种 ...
- 总结微信公众平台网页开发中遇到的ios的兼容问题
1. ios中音频不自动播放: 原因:出于节省流量的初衷,ios系统禁止音视频自动播放. 解决方案:使用微信的JS-SDK. DEMO: 先引入微信的JS-SDK, <script src=&q ...
- sublime text 3 无法安装Package Control插件解决办法
sublime text 3 无法安装Package Control插件解决办法 ***关于sublime text 3 常用的 Package Control插件的安装方法*** 1.CTRL+` ...
- 【原】无脑操作:TypeScript环境搭建
概述:本文描述TypeScript环境搭建,以及基于VSCode的自动编译设置和调试设置.网络上很多相应文章的方式过时了或者无法试验成功. ------------------------------ ...
- Linux 操作系统基础
list : ls 目录: 文件,路径映射. ls : -l : lang 长格式, 显示完整信息. 文件类型: -: 普通文件(f) d: 目录文件 b: 块设备文件(block) c: 字块设备文 ...
- JAVAFX之tableview界面实时刷新导致的内存溢出(自己挖的坑,爬着也要出来啊0.0)
这几天遇到了一个问题,不幸开发的一个cs架构的工具,客户端开启后,内存一直在缓慢增长最终导致进程卡死,花了4天时间,终于爬出来了... 客户端通过timer定时器每30秒查询一次数据库以及一些业务逻辑 ...
- PuppeteerSharp: 更友好的 Headless Chrome C# API
前端就有了对 headless 浏览器的需求,最多的应用场景有两个 UI 自动化测试:摆脱手工浏览点击页面确认功能模式 爬虫:解决页面内容异步加载等问题 也就有了很多杰出的实现,前端经常使用的莫过于 ...
- CAS、原子操作类的应用与浅析及Java8对其的优化
前几天刷朋友圈的时候,看到一段话:如果现在我是傻逼,那么我现在不管怎么努力,也还是傻逼,因为我现在的傻逼是由以前决定的,现在努力,是为了让以后的自己不再傻逼.话糙理不糙,如果妄想现在努力一下,马上就不 ...