Apache Hudi集成Apache Zeppelin实战
1. 简介
Apache Zeppelin 是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等等。当前Hive与SparkSQL已经支持查询Hudi的读优化视图和实时视图。所以理论上Zeppelin的notebook也应当拥有这样的查询能力。
2.实现效果
2.1 Hive
2.1.1 读优化视图
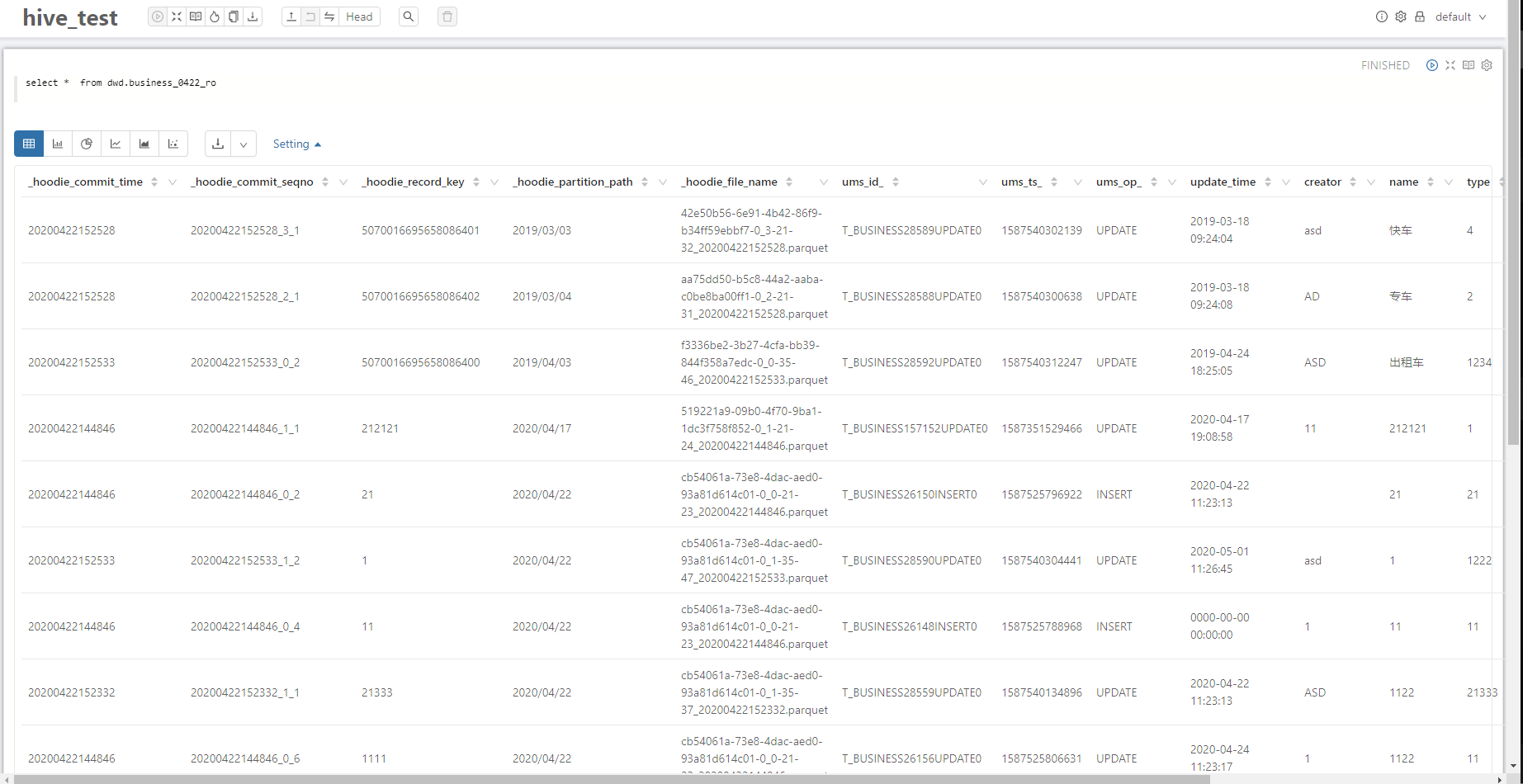
2.1.2 实时视图
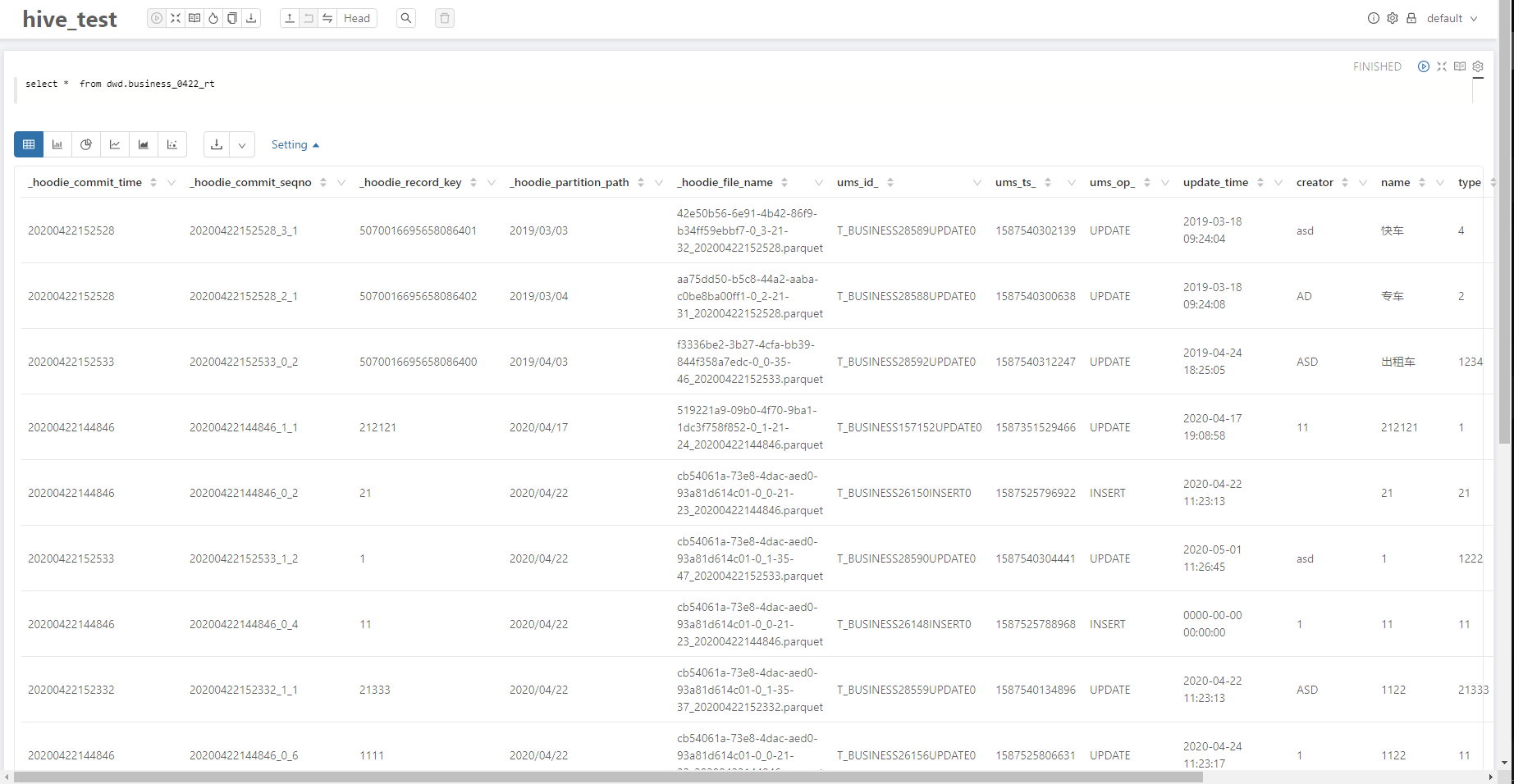
2.2 Spark SQL
2.2.1 读优化视图
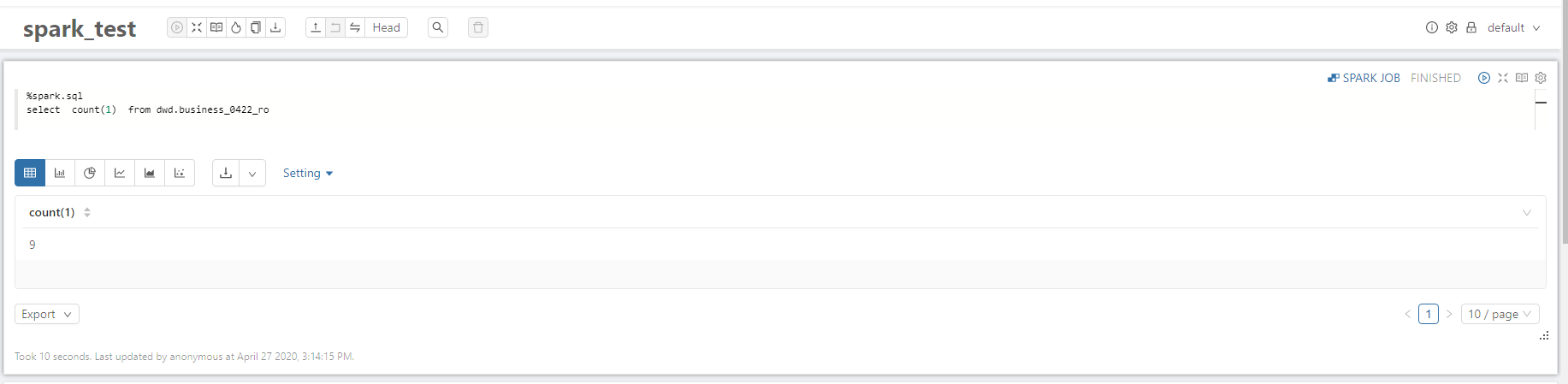
2.2.2 实时视图
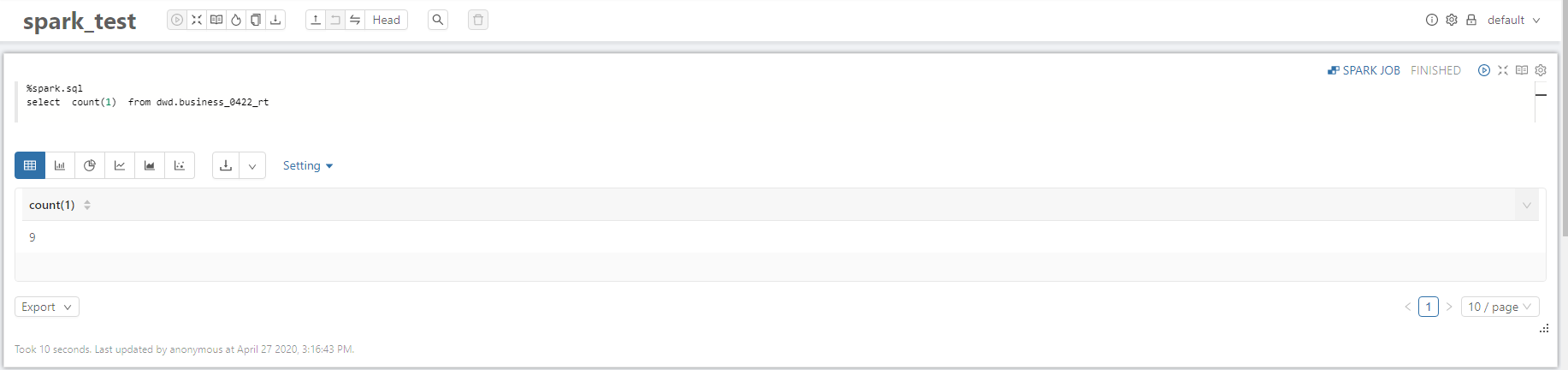
3.常见问题整理
3.1 Hudi包适配
cp hudi-hadoop-mr-bundle-0.5.2-SNAPSHOT.jar zeppelin/lib
cp hudi-hive-bundle-0.5.2-SNAPSHOT.jar zeppelin/lib
cp hudi-spark-bundle_2.11-0.5.2-SNAPSHOT.jar zeppelin/lib
Zeppelin启动时会默认加载lib下的包,对于Hudi这类外部依赖,适合直接放在zeppelin/lib下以避免 Hive或Spark SQL在集群上找不到对应Hudi依赖。
3. 2 parquet jar包适配
Hudi包的parquet版本为1.10,当前CDH集群parquet版本为1.9,所以在执行Hudi表查询时,会报很多jar包冲突的错。
解决方法:在zepeelin所在节点的spark/jars目录下将parquet包升级成1.10。
副作用:zeppelin 以外的saprk job 分配到 parquet 1.10的集群节点的任务可能会失败。
建议:zeppelin 以外的客户端也会有jar包冲突的问题。所以建议将集群的spark jar 、parquet jar以及相关依赖的jar做全面升级,更好地适配Hudi的能力。
3.3 Spark Interpreter适配
相同sql在Zeppelin上使用Spark SQL查询会出现比hive查询记录条数多的现象。
问题原因:当向Hive metastore中读写Parquet表时,Spark SQL默认将使用Spark SQL自带的Parquet SerDe(SerDe:Serialize/Deserilize的简称,目的是用于序列化和反序列化),而不是用Hive的SerDe,因为Spark SQL自带的SerDe拥有更好的性能。
这样导致了Spark SQL只会查询Hudi的流水记录,而不是最终的合并结果。
解决方法:set spark.sql.hive.convertMetastoreParquet=false
方法一:直接在页面编辑属性

方法二:编辑 zeppelin/conf/interpreter.json添加
interpreter
"spark.sql.hive.convertMetastoreParquet": {
"name": "spark.sql.hive.convertMetastoreParquet",
"value": false,
"type": "checkbox"
},
4. Hudi增量视图
对于Hudi增量视图,目前只支持通过写Spark 代码的形式拉取。考虑到Zeppelin在notebook上有直接执行代码和shell 命令的能力,后面考虑封装这些notebook,以支持sql的方式查询Hudi增量视图。
Apache Hudi集成Apache Zeppelin实战的更多相关文章
- Apache Hudi集成Spark SQL抢先体验
Apache Hudi集成Spark SQL抢先体验 1. 摘要 社区小伙伴一直期待的Hudi整合Spark SQL的PR正在积极Review中并已经快接近尾声,Hudi集成Spark SQL预计会在 ...
- Apache Hudi与Apache Flink集成
感谢王祥虎@wangxianghu 投稿 Apache Hudi是由Uber开发并开源的数据湖框架,它于2019年1月进入Apache孵化器孵化,次年5月份顺利毕业晋升为Apache顶级项目.是当前最 ...
- 生态 | Apache Hudi集成Alluxio实践
原文链接:https://mp.weixin.qq.com/s/sT2-KK23tvPY2oziEH11Kw 1. 什么是Alluxio Alluxio为数据驱动型应用和存储系统构建了桥梁, 将数据从 ...
- Apache Hudi + AWS S3 + Athena实战
Apache Hudi在阿里巴巴集团.EMIS Health,LinkNovate,Tathastu.AI,腾讯,Uber内使用,并且由Amazon AWS EMR和Google云平台支持,最近Ama ...
- 重磅!Vertica集成Apache Hudi指南
1. 摘要 本文演示了使用外部表集成 Vertica 和 Apache Hudi. 在演示中我们使用 Spark 上的 Apache Hudi 将数据摄取到 S3 中,并使用 Vertica 外部表访 ...
- 基于 Apache Hudi 和DBT 构建开放的Lakehouse
本博客的重点展示如何利用增量数据处理和执行字段级更新来构建一个开放式 Lakehouse. 我们很高兴地宣布,用户现在可以使用 Apache Hudi + dbt 来构建开放Lakehouse. 在深 ...
- Apache Hudi重磅特性解读之存量表高效迁移机制
1. 摘要 随着Apache Hudi变得越来越流行,一个挑战就是用户如何将存量的历史表迁移到Apache Hudi,Apache Hudi维护了记录级别的元数据以便提供upserts和增量拉取的核心 ...
- 恭喜!Apache Hudi社区新晋多位Committer
1. 介绍 经过Apache Hudi项目委员会讨论及投票,向Udit Mehrotra.Gary Li.Raymond Xu.Pratyaksh Sharma 4人发出Committer邀请,4人均 ...
- Apache Hudi助力nClouds加速数据交付
1. 概述 在nClouds上,当客户的业务决策取决于对近实时数据的访问时,客户通常会向我们寻求有关数据和分析平台的解决方案.但随着每天创建和收集的数据量都在增加,这使得使用传统技术进行数据分析成为一 ...
随机推荐
- 基于MVP模式实现四则运算器
基于MVP模式四则运算器 来到新东家,项目的框架采用的是MVP模式,刚来公司的时候,项目经理给予分配小任务,首先熟悉MVP模式,而后普通的四则运算器的实现使用MVP分层.这里主要回顾当时做任务时候的对 ...
- 模块 time datetime 时间获取和处理
模块_time 和时间有关系的我们就要用到时间模块.在使用模块之前,应该首先导入这个模块. 1 延时 time.sleep(secs) (线程)推迟指定的时间运行.单位为秒. 2 获取当前时间戳tim ...
- Codeforces Round #625 (1A - 1D)
A - Journey Planning 题意: 有一列共 n 个城市, 每个城市有美丽值 b[i], 要访问一个子序列的城市, 这个子序列相邻项的原项数之差等于美丽值之差, 求最大的美丽值总和. ...
- vue 听说你很会传值?
前置 大小 vue 项目都离不开组件通讯, 在这里总结一下vue组件通讯方式并列出, 都是简单的例子. 适合像我这样的小白.如有错误,欢迎指正. 温馨提示: 下文没有列出 vuex, vuex 也是重 ...
- Markdown语法快速学习
Markdown 简洁语法说明 0.前言 一直以来都是以word文档做笔记,存在很多问题,比如代码格式.高亮等.这次公司要求使用markdown,感觉眼前一亮,以前word的问题都得到了解决,而且可以 ...
- Vim查找与替换命令大全,功能完爆IDE!
Vi/Vim 可以说是文本编辑中的一代传奇人物,直至现在,它仍然在高级程序员的武器库中占有一席之地.每个 Linux 发行版默认都包含Vim ,而且即使你不是 Linux 系统用户,你也可以安装 Vi ...
- 1039 Course List for Student (25分)
Zhejiang University has 40000 students and provides 2500 courses. Now given the student name lists o ...
- js之ES6的Class类
JavaScript ES6之前的还没有Class类的概念,生成实例对象的传统方法是通过构造函数. 例如: function Mold(a,b){ this.a=a; this.b=b; } Mold ...
- 微信小程序页面跳转的三种方式总结
原文链接 https://blog.csdn.net/zgmu/article/details/72123329 首先我们了解到,小程序规定页面路径只能有五层,所以我们尽量避免多层级的页面跳转 页面跳 ...
- 将wxpy的登录二维码放到网页上登录
from flask import Flask, Response from flask.views import MethodView from threading import Thread fr ...