060 SparkStream 的wordcount示例
1.SparkStream
入口:StreamingContext
抽象:DStream
2.SparkStreaming内部原理
当一个批次到达的时候,会产生一个rdd,这个rdd的数据就是这个批次所接收/应该处理的数据内容,内部具体执行是rdd job的调度
batchDuration: 产生RDD的间隔时间(定时任务,间隔给定时间后会生产一个RDD),产生的RDD会缓存到一个Map<Time, RDD>;RDD的调度当集合中有一个rdd的time时间超过当前时间的时候(>=),对应的rdd被触发操作
一:安装nc
1.说明
netcat(nc)是一个简单而有用的工具,被誉为网络安全界的“瑞士均道”。
不仅可以通过使用TCP或UDP协议的网络连接读写数据,同时还是一个功能强大的网络调试和探测工具,能够建立你需要的几乎所有类型的网络连接。
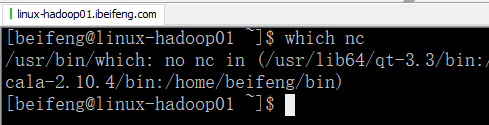
2.检测nc
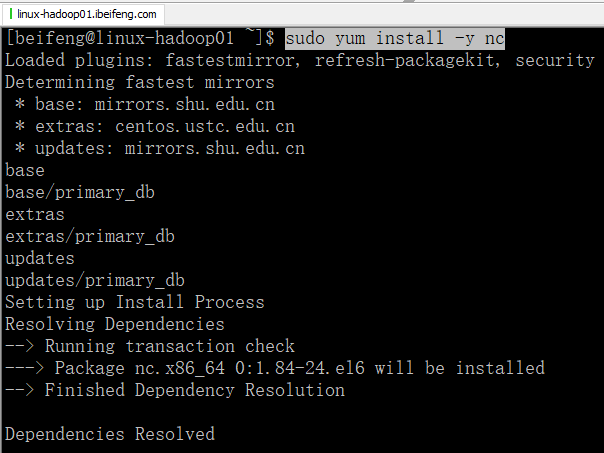
3.安装
sudo yum install -y nc
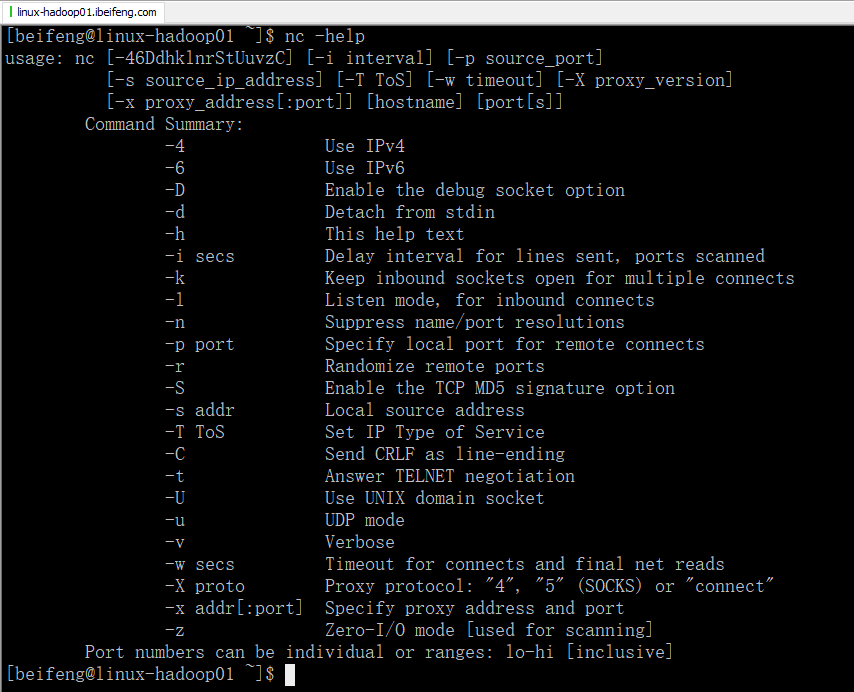
4.检查是否可以使用
5.使用数据进行测试
在一个终端输入数据:

6.解决问题
因为,这里安装了高版本的nc,centos在6.4不适合nc。
不建议使用nc这种yum的方式。
7.卸载
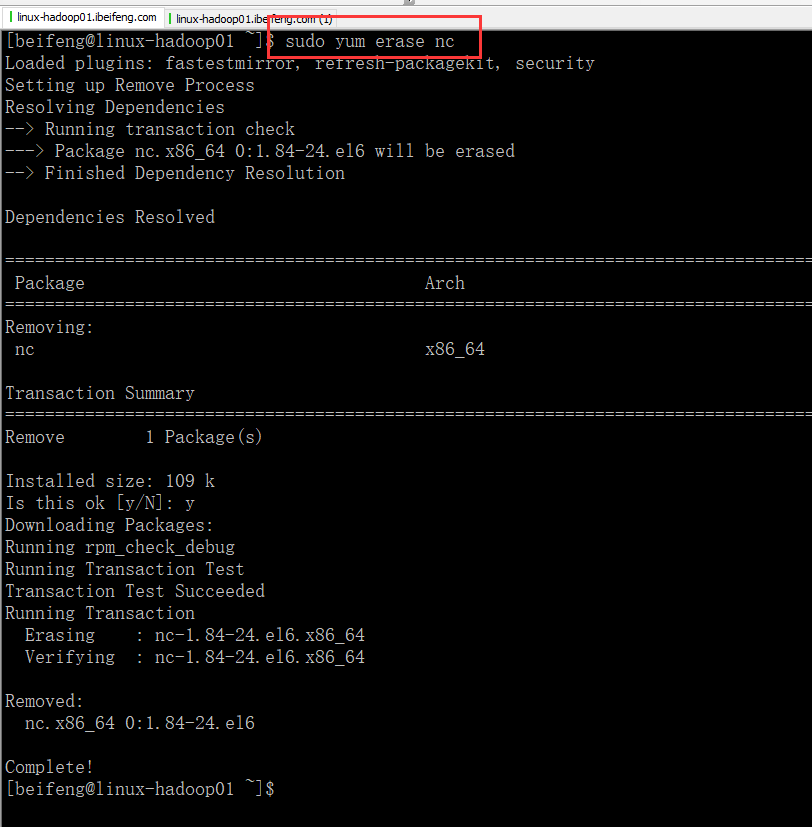
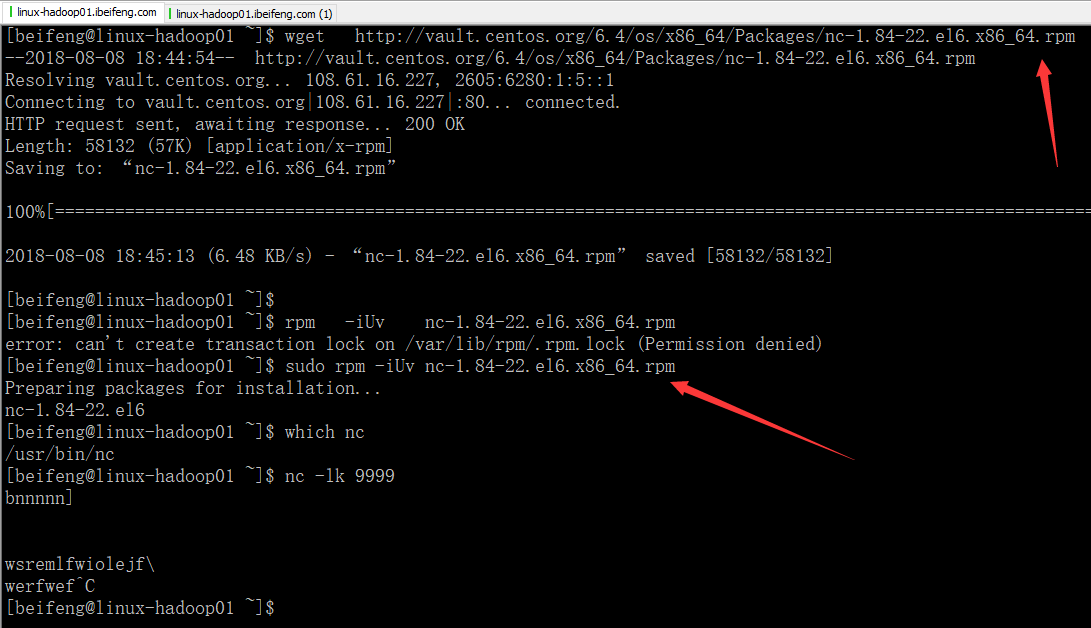
8.重新安装
下载合适的版本
wget http://vault.centos.org/6.4/os/x86_64/Packages/nc-1.84-22.el6.x86_64.rpm
rpm -iUv nc-1.84-22.el6.x86_64.rpm
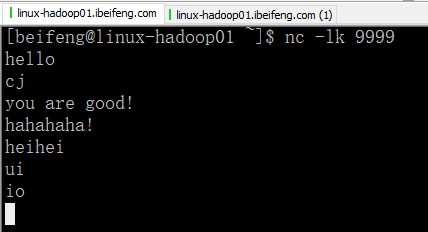
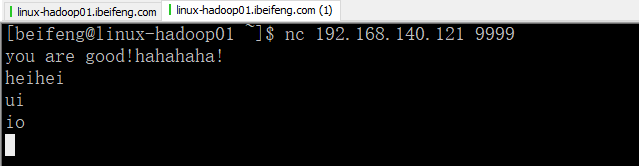
9.测试接受数据
发送:
接收:
10.yum install nc.x86_64
这样下载的nc版本是nc-1.84-24.e
版本还是高,和直接yum install nc的版本一样。
二:程序
1.程序
package com.stream.it
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object SparkStreamWordcount {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setAppName("spark-streaming-wordcount")
.setMaster("local[*]")
val sc=SparkContext.getOrCreate(conf)
val ssc=new StreamingContext(sc,Seconds(15))
val hostname="linux-hadoop01.ibeifeng.com"
val port=9999
val dstream=ssc.socketTextStream(hostname,port)
/**
* 80%的RDD上的方法可以在DStream上直接使用
*/
val resultWordcount=dstream
.filter(line=>line.nonEmpty)
.flatMap(line=>line.split(" ").map((_,1)))
.reduceByKey(_+_)
resultWordcount.foreachRDD(rdd=>{
rdd.foreachPartition(iter=>iter.foreach(println))
})
//启动
ssc.start()
//等到
ssc.awaitTermination()
}
}
2.发送数据
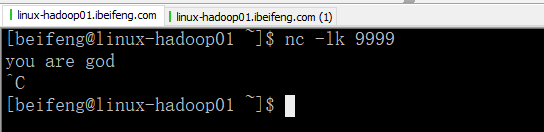
3.控制台

060 SparkStream 的wordcount示例的更多相关文章
- WordCount示例深度学习MapReduce过程(1)
我们都安装完Hadoop之后,按照一些案例先要跑一个WourdCount程序,来测试Hadoop安装是否成功.在终端中用命令创建一个文件夹,简单的向两个文件中各写入一段话,然后运行Hadoop,Wou ...
- WordCount示例深度学习MapReduce过程
转自: http://blog.csdn.net/yczws1/article/details/21794873 . 我们都安装完Hadoop之后,按照一些案例先要跑一个WourdCount程序,来测 ...
- hadoop学习第三天-MapReduce介绍&&WordCount示例&&倒排索引示例
一.MapReduce介绍 (最好以下面的两个示例来理解原理) 1. MapReduce的基本思想 Map-reduce的思想就是“分而治之” Map Mapper负责“分”,即把复杂的任务分解为若干 ...
- MapReduce 编程模型 & WordCount 示例
学习大数据接触到的第一个编程思想 MapReduce. 前言 之前在学习大数据的时候,很多东西很零散的做了一些笔记,但是都没有好好去整理它们,这篇文章也是对之前的笔记的整理,或者叫输出吧.一来是加 ...
- 九、sparkStream的scala示例
简介 sparkStream官网:http://spark.apache.org/docs/latest/streaming-programming-guide.html#overview spark ...
- Storm入门(四)WordCount示例
一.关联代码 使用maven,代码如下. pom.xml 和Storm入门(三)HelloWorld示例相同 RandomSentenceSpout.java /** * Licensed to t ...
- 【Big Data - Hadoop - MapReduce】初学Hadoop之图解MapReduce与WordCount示例分析
Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算. HDFS是Google File System(GFS) ...
- 初学Hadoop之图解MapReduce与WordCount示例分析
Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算. HDFS是Google File System(GFS) ...
- Erlang基础 -- 介绍 -- Wordcount示例演示
在前两个blog中,已经说了Erlang的历史.应用场景.特点,这次主要演示一个Wordcount的示例,就是给定一个文本文件,统计这个文本文件中的单词以及该单词出现的次数. 今天和群友们讨论了一个问 ...
随机推荐
- VBS将本地的Excel数据导入到SQL Server中
VBS将本地的Excel数据导入到SQL Server中 高文龙关注0人评论1170人阅读2017-05-14 12:54:44 VBS将本地的Excel数据导入到SQL Server中 最近有个测试 ...
- ORACLE环境变量定义
export在linux的bash中可以理解为设置环境变量.设置后能够被当前的shell及子shell使用. 这些变量的含义有一些有意义,可以查看相应的文档,我给你解释一些我知道的: ORACLE_H ...
- Confluence 6 用自带的用户管理
在一些特定的情况下,你可能希望禁用 Confluence 自带的用户管理或完全使用外部的用户目录进行用户管理.例如 Jira 软件或者 Jira Service Desk.你可以在 Confluenc ...
- laravel 框架后台主菜单接口
后台菜单调用接口:/admin/manages ManageRepository类: 每个路由中注册: 等等: 最后后台菜单返回:
- laravel 中CSS 预编译语言 Sass 快速入门教程
CSS 预编译语言概述 CSS 作为一门样式语言,语法简单,易于上手,但是由于不具备常规编程语言提供的变量.函数.继承等机制,因此很容易写出大量没有逻辑.难以复用和扩展的代码,在日常开发使用中,如果没 ...
- Java 9 中的 9 个新特性你知道吗
摘要: Java 8 发布三年多之后,即将快到2017年7月下一个版本发布的日期了. 你可能已经听说过 Java 9 的模块系统,但是这个新版本还有许多其它的更新. 这里有九个令人兴奋的新功能将与 J ...
- hdfs数据到hbase过程
需求:将HDFS上的文件中的数据导入到hbase中 实现上面的需求也有两种办法,一种是自定义mr,一种是使用hbase提供好的import工具 一.hdfs中的数据是这样的 hbase创建好表 cre ...
- Python自定义-分页器
Python自定义-分页器 分页功能在每个网站都是必要的,对于分页来说,其实就是根据用户的输入计算出应该在数据库表中的起始位置. 1.设定每页显示数据条数 2.用户输入页码(第一页.第二页...) 3 ...
- pycaffe训练的完整组件示例
pycaffe训练的完整组件示例 为什么写这篇博客 1. 需要用到pycaffe 因为用到的开源代码基于Caffe:要维护的项目基于Caffe.基本上是用Caffe的Python接口. 2. 训练中想 ...
- Caffe和py-faster-rcnn日常使用备忘录
罗列日常使用中遇到的问题和解决办法.包括: { caffe使用中的疑惑和解释: 无法正常执行 train/inference 的情况: Caffe基础工具的微小调整,比如绘loss曲线图: 调试pyt ...