sklearn交叉验证3-【老鱼学sklearn】
在上一个博文中,我们用learning_curve函数来确定应该拥有多少的训练集能够达到效果,就像一个人进行学习时需要做多少题目就能拥有较好的考试成绩了。
本次我们来看下如何调整学习中的参数,类似一个人是在早上7点钟开始读书好还是晚上8点钟读书好。
加载数据
数据仍然利用手写数字识别作为训练数据:
from sklearn.datasets import load_digits
# 加载数据
digits = load_digits()
X = digits.data
y = digits.target
调整参数
我们想要调整·SVC(gamma=0.001)·SVC中的gamma参数,看到底把gamma参数设置成哪个值是最优的。
因此需要定义测试的参数范围,这里设置了参数值的范围为从10的-6次方到10的-2.3次方,总共5个值:
import numpy as np
# 定义gamma参数的可能取值范围,从10**-6, 到10**-2.3,总共5个参数值
param_range = np.logspace(-6, -2.3, 5)
用validation_curve不停尝试在不同参数值下的损失函数值:
from sklearn.model_selection import validation_curve
from sklearn.svm import SVC
# param_name中指定了修改SVC中的哪个参数值,这里修改的是gamma参数值;param_range参数指定了具体参数值的可选范围
train_loss, test_loss = validation_curve(SVC(), X, y, param_name="gamma", param_range=param_range, cv=10, scoring='neg_mean_squared_error')
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
可视化图形
可视化图形,横坐标为参数可选值的范围,纵坐标为在各参数下的损失函数值
# 可视化图形,横坐标为参数可选值的范围,纵坐标为在各参数下的损失函数值
import matplotlib.pyplot as plt
plt.plot(param_range, train_loss_mean, label="Train")
plt.plot(param_range, test_loss_mean, label="Test")
plt.legend()
plt.show()
图形显示为:
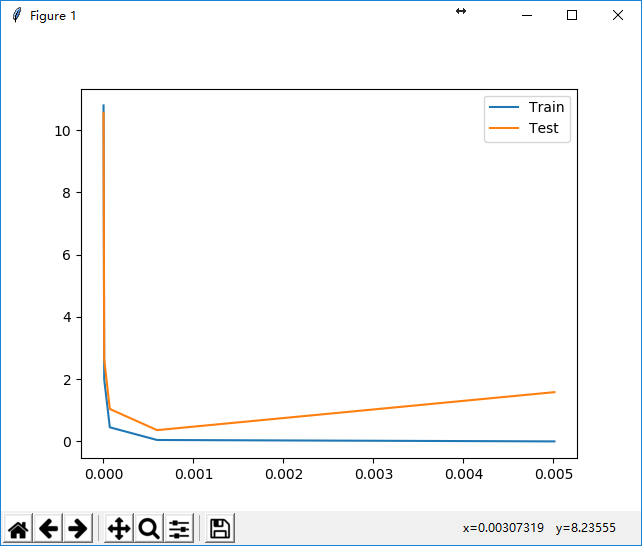
在这个图形中,我们发现gamma值有一个转折点,当其在0.001之后,测试集的误差值就开始扩大了,因此,从图形上看,一个比较好的学习参数值是gamma=0.001或者再往前一点点,大概在0.0007左右。
完整代码
完整的代码如下:
from sklearn.datasets import load_digits
# 加载数据
digits = load_digits()
X = digits.data
y = digits.target
import numpy as np
# 定义gamma参数的可能取值范围,从10**-6, 到10**-2.3,总共5个参数值
param_range = np.logspace(-6, -2.3, 5)
from sklearn.model_selection import validation_curve
from sklearn.svm import SVC
# param_name中指定了修改SVC中的哪个参数值,这里修改的是gamma参数值;param_range参数指定了具体参数值的可选范围
train_loss, test_loss = validation_curve(SVC(), X, y, param_name="gamma", param_range=param_range, cv=10, scoring='neg_mean_squared_error')
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
# 可视化图形,横坐标为参数可选值的范围,纵坐标为在各参数下的损失函数值
import matplotlib.pyplot as plt
plt.plot(param_range, train_loss_mean, label="Train")
plt.plot(param_range, test_loss_mean, label="Test")
plt.legend()
plt.show()
sklearn交叉验证3-【老鱼学sklearn】的更多相关文章
- sklearn交叉验证-【老鱼学sklearn】
交叉验证(Cross validation),有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法.于是可以先在一个子集上做分析, 而其它子集则用来做后续对此分析的确认及验证. 一开始 ...
- sklearn交叉验证2-【老鱼学sklearn】
过拟合 过拟合相当于一个人只会读书,却不知如何利用知识进行变通. 相当于他把考试题目背得滚瓜烂熟,但一旦环境稍微有些变化,就死得很惨. 从图形上看,类似下图的最右图: 从数学公式上来看,这个曲线应该是 ...
- sklearn保存模型-【老鱼学sklearn】
训练好了一个Model 以后总需要保存和再次预测, 所以保存和读取我们的sklearn model也是同样重要的一步. 比如,我们根据房源样本数据训练了一下房价模型,当用户输入自己的房子后,我们就需要 ...
- sklearn数据库-【老鱼学sklearn】
在做机器学习时需要有数据进行训练,幸好sklearn提供了很多已经标注好的数据集供我们进行训练. 本节就来看看sklearn提供了哪些可供训练的数据集. 这些数据位于datasets中,网址为:htt ...
- sklearn模型的属性与功能-【老鱼学sklearn】
本节主要讲述模型中的各种属性及其含义. 例如上个博文中,我们有用线性回归模型来拟合房价. # 创建线性回归模型 model = LinearRegression() # 训练模型 model.fit( ...
- sklearn标准化-【老鱼学sklearn】
在前面的一篇博文中关于计算房价中我们也大致提到了标准化的概念,也就是比如对于影响房价的参数中有面积和户型,面积的取值范围可以很广,它可以从0-500平米,而户型一般也就1-5. 标准化就是要把这两种参 ...
- 二分类问题续 - 【老鱼学tensorflow2】
前面我们针对电影评论编写了二分类问题的解决方案. 这里对前面的这个方案进行一些改进. 分批训练 model.fit(x_train, y_train, epochs=20, batch_size=51 ...
- tensorflow卷积神经网络-【老鱼学tensorflow】
前面我们曾有篇文章中提到过关于用tensorflow训练手写2828像素点的数字的识别,在那篇文章中我们把手写数字图像直接碾压成了一个784列的数据进行识别,但实际上,这个图像是2828长宽结构的,我 ...
- 机器学习- Sklearn (交叉验证和Pipeline)
前面一节咱们已经介绍了决策树的原理已经在sklearn中的应用.那么这里还有两个数据处理和sklearn应用中的小知识点咱们还没有讲,但是在实践中却会经常要用到的,那就是交叉验证cross_valid ...
随机推荐
- Django url (路由)
1.路由的基本使用 #url 是个函数,有四个参数,第一个参数要传正则表达式,第二个参数传函数内存地址,第三个传默认参数,第四个传路由别名 url(r'^yaopipqideneirong/art ...
- PHP 5.6 中 Automatically populating $HTTP_RAW_POST_DATA is deprecated and will be removed in a future version
解决方法 找到php.ini 文件, 把always_populate_raw_post_data 修改为-1 就行了. always_populate_raw_post_data=-1
- 守护进程(Daemon)
守护进程的概念 守护进程(Daemon)一般是为了保护我们的程序/服务的正常运行,当程序被关闭.异常退出等时再次启动程序/恢复服务. 例如 http 服务的守护进程叫 httpd,mysql 服务的守 ...
- python实现域名解析和归属地查询
前言工作中有时要查询域名解析和获取域名相关IP归属地信息 安装依赖python2:pip install dnspythonpython3:python3 -m pip install -i http ...
- Sequence II HDU - 5919(主席树)
Mr. Frog has an integer sequence of length n, which can be denoted as a1,a2,⋯,ana1,a2,⋯,anThere are ...
- Memory Layout for Multiple and Virtual Inheritance
Memory Layout for Multiple and Virtual Inheritance(By Edsko de Vries, January 2006)Warning. This art ...
- jmeter笔记(2)--组件介绍
1.测试计划 测试计划(Test Plan)是使用JMeter进行测试的起点,它是其它JMeter测试元件的容器. 2.Threads(Users)-线程组 每个测试需求的必备组件,是用来模拟用户并发 ...
- 洛谷P2120 [ZJOI2007]仓库建设 斜率优化DP
做的第一道斜率优化\(DP\)QwQ 原题链接1/原题链接2 首先考虑\(O(n^2)\)的做法:设\(f[i]\)表示在\(i\)处建仓库的最小费用,则有转移方程: \(f[i]=min\{f[j] ...
- ASP.NET知识点汇总
一 ,html属性20181113常用的居中方法1 text-align2 float3 margin (margin-left matgin-right margin-bottom margin-t ...
- busybox(四)完善
目录 busybox(四)完善 proc挂载 手动挂载 proc解析 使用脚本自动挂载 使用mount-a挂载 udev/mdev 挂载 使用jffs2 文件系统格式 安装zlib 安装jffs2 生 ...