PCA误差
我们知道,PCA是用于对数据做降维的,我们一般用PCA把m维的数据降到k维(k < m)。
那么问题来了,k取值多少才合适呢?
PCA误差
PCA的原理是,为了将数据从n维降低到k维,需要找到k个向量,用于投影原始数据,是投影误差(投影距离)最小。
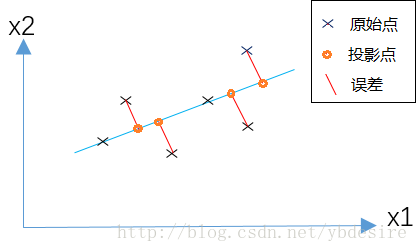
用公式来表示,如下
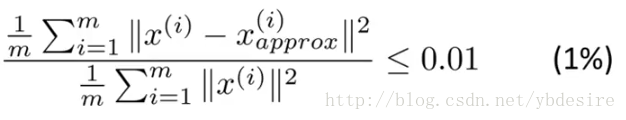
其中
- m表示特征个数
分子表示原始点与投影点之间的距离之和,而误差越小,说明降维后的数据越能完整表示降维前的数据。如果这个误差小于0.01,说明降维后的数据能保留99%的信息。
k值选取的原理
实际应用中,我们一般根据上式,选择能使误差小于0.01(99%的信息都被保留)或0.05(95%的信息都被保留)的k值。
而在实际编码中,参考文章《详解主成分分析PCA》,在PCA的实现过程中,对协方差矩阵做奇异值分解时,能得到S矩阵(特征值矩阵)。
PCA误差的表达式等效于下式
从代码示例中,可以看出,将数据从三维降到二维,保留了99.997%的信息。
[U,S,V] = np.linalg.svd(sigma) # 奇异值分解
(S[0]+S[1])/(S www.hbs90.cn/ www.boshenyl.cn [0]+S[1]+S[2])
# result = 0.99996991682077252- 1
- 2
- 3
实际使用
用sklearn封装的PCA方法,做PCA的代码如下。PCA方法参数n_components,如果设置为整数,则n_components=k。如果将其设置为小数,则说明降维后的数据能保留的信息。
from sklearn.decomposition import PCA
import numpy as np
from sklearn.preprocessing import StandardScaler
x=np.array([[10001,2,55],www.feihuanyule.com [16020,4,11], [12008,6,33], [13131,8,22]])
# feature normalization (feature scaling)
X_scaler = StandardScaler()
x = X_scaler.fit_transform(x)
# PCA
pca = PCA(n_components=0.9)# 保证降维后的数据保持90%的信息
pca.fit(x)
pca.transform(x所以在实际使用PCA时,我们不需要选择k,而是直接设置n_components为float数据。
总结
PCA主成分数量k的选择,是一个数据压缩的问题。通常我们直接将sklearn中PCA方法参数n_components设置为float数据,来间接解决k值选取问题。
但有的时候我们降维只是为了观测数据(visualization),这种情况下一般将k选择为2或3。
参考
- Andrew NG在coursera的机器学习课程
- PCA的完整实现过程代码详解
- http://stackoverflow.com/questions/33509074/sklearn-pca-calculate-of-variance-retained-for-choosing-k
PCA误差的更多相关文章
- Stanford机器学习笔记-10. 降维(Dimensionality Reduction)
10. Dimensionality Reduction Content 10. Dimensionality Reduction 10.1 Motivation 10.1.1 Motivation ...
- PCA算法的最小平方误差解释
PCA算法另外一种理解角度是:最小化点到投影后点的距离平方和. 假设我们有m个样本点,且都位于n维空间 中,而我们要把原n维空间中的样本点投影到k维子空间W中去(k<n),并使得这m个点到投影点 ...
- 机器学习基础与实践(三)----数据降维之PCA
写在前面:本来这篇应该是上周四更新,但是上周四写了一篇深度学习的反向传播法的过程,就推迟更新了.本来想参考PRML来写,但是发现里面涉及到比较多的数学知识,写出来可能不好理解,我决定还是用最通俗的方法 ...
- PRML读书会第十二章 Continuous Latent Variables(PCA,Principal Component Analysis,PPCA,核PCA,Autoencoder,非线性流形)
主讲人 戴玮 (新浪微博: @戴玮_CASIA) Wilbur_中博(1954123) 20:00:49 我今天讲PRML的第十二章,连续隐变量.既然有连续隐变量,一定也有离散隐变量,那么离散隐变量是 ...
- PCA 主成分分析(Principal components analysis )
问题 1. 比如拿到一个汽车的样本,里面既有以“千米/每小时”度量的最大速度特征,也有“英里/小时”的最大速度特征,显然这两个特征有一个多余. 2. 拿到一个数学系的本科生期末考试成绩单,里面有三列, ...
- 机器学习公开课笔记(8):k-means聚类和PCA降维
K-Means算法 非监督式学习对一组无标签的数据试图发现其内在的结构,主要用途包括: 市场划分(Market Segmentation) 社交网络分析(Social Network Analysis ...
- 主元分析PCA理论分析及应用
首先,必须说明的是,这篇文章是完完全全复制百度文库当中的一篇文章.本人之前对PCA比较好奇,在看到这篇文章之后发现其对PCA的描述非常详细,因此迫不及待要跟大家分享一下,希望同样对PCA比较困惑的朋友 ...
- 四大机器学习降维算法:PCA、LDA、LLE、Laplacian Eigenmaps
四大机器学习降维算法:PCA.LDA.LLE.Laplacian Eigenmaps 机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中.降维的本质是学习一个映 ...
- (六)6.6 Neurons Networks PCA
主成分分析(PCA)是一种经典的降维算法,基于基变换,数据原来位于标准坐标基下,将其投影到前k个最大特征值对应的特征向量所组成的基上,使得数据在新基各个维度有最大的方差,且在新基的各个维度上数据是不相 ...
随机推荐
- CC3200使用MQTT的SSL加密证书可用日期修改
1. 在使用CC3200进行SSL加密的时候,需要证书,但是证书有一个截止日期,如果当前CC3200没有设置这个日期,那么证书通信会失败,需要添加代码 int setDeviceTime() { Sl ...
- 转 Cobar使用文档(可用作MySQL大型集群解决方案)
转自:http://blog.csdn.net/shagoo/article/details/8191346 最近好不容易抽空研究了下Cobar,感觉这个产品确实很不错(在文档方面比Amoeba强多了 ...
- Ruby 基础教程1-4
1.对象 数值对象 字符串对象 数组对象,散列对象 正则表达式对象 时间对象 文件对象 符号对象 2.类 Numeric String Array Hash Regexp File Symbol 3. ...
- photoshop cc 2018安装破解教程(破解补丁,亲测,绝对可用)
破解步骤说明:下载地址百度网盘,https://pan.baidu.com/s/1cWtpUesl2fms3tFwEC0MiQ 1.右键解压Adobe Photoshop CC 2018 64位这个文 ...
- hdu1312Red and Black(迷宫dfs,一遍)
Red and Black Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Tot ...
- hdu1455Sticks(经典dfs+剪枝)
Sticks Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Subm ...
- P/Invoke 光标的操作
获取与设置光标在屏幕上的位置 GetCursorPos 获取光标在屏幕上的位置,光标位置始终是在屏幕坐标纵指定的,并且不受包含光标的窗口映射模式的影响 函数原型: BOOL GetCursorPos( ...
- Objective-C 构造方法 分类 类的深入研究
构造方法 1.对象创建的原理 new的拆分两部曲 Person *p = [Person alloc]; 分配内存(+alloc) Person *p = [p init]; 初始化(-init) 合 ...
- 初学Direct X(5)
初学Direct X(5) 前面学习了使用表面绘制屏幕,但这种方法与另一种比较起来,有着绘图速度颇慢以及缺乏对任何透明类型的支持,这就是前面的篮框以及炸弹会有黑色背景的原因,这种方法就是纹理.他可以绘 ...
- 自己来编写一份 Python 脚本 第一版
解决问题 我们已经探索了 Python 语言中的许多部分,现在我们将通过设计并编写一款程序来了解如何把这些部分组合到一起.这些程序一定是能做到一些有用的事情.这节的Python教程就是教大家方法去学习 ...