二分类算法的评价指标:准确率、精准率、召回率、混淆矩阵、AUC
评价指标是针对同样的数据,输入不同的算法,或者输入相同的算法但参数不同而给出这个算法或者参数好坏的定量指标。
以下为了方便讲解,都以二分类问题为前提进行介绍,其实多分类问题下这些概念都可以得到推广。
准确率
准确率是最好理解的评价指标,它是一个比值:
\[
准确率 = \cfrac{算法分类正确的数据个数}{输入算法的数据的个数}
\]
但是使用准确率评价算法有一个问题,就是在数据的类别不均衡,特别是有极偏的数据存在的情况下,准确率这个评价指标是不能客观评价算法的优劣的。例如下面这个例子:
我们检测对 1000 个人是否患有癌症进行检测,其实癌症是一个发病率很低的疾病,我们就假定这 1000 个人里面只有 3 个人真正患病。
此时,我们可以“无脑地”设计一个算法,就预测这 1000 个人全部健康。根据准确率的定义,除了那 3 个真正患病的病人我们预测错了,其余健康的 997 人我们的算法都预测正确了,此时
\[
准确率 = \cfrac{算法分类正确的数据}{输入算法的数据的总数} = \cfrac{997}{1000} = 99.7\%
\]
事实上,这样的算法没有任何的预测能力,真的用于医疗是极其不负责的,于是我们就应该考虑是不是评价指标出了问题。这个时候就需要别的评价指标了。
精准率、召回率
要解释清楚精准率和召回率,得先解释混淆矩阵,二分类问题的混淆矩阵由 4 个数构成。首先我们将二分类问题中,我们关心的,少数的那一部分数据,我们称之为正例(positive),就如同预测癌症,癌症患者就定义为正例。那么剩下的就定义为负例(negative)。
于是,我们定义:
TN:算法预测为负例(N),实际上也是负例(N)的个数,即算法预测对了(True);
FP:算法预测为正例(P),实际上是负例(N)的个数,即算法预测错了(False);
FN:算法预测为负例(N),实际上是正例(P)的个数,即算法预测错了(False);
TP:算法预测为正例(P),实际上也是正例(P)的个数,即算法预测对了(True)。
这 4 个定义由两个字母组成,第 1 个字母表示算法预测正确或者错误,第 2 个字母表示算法预测的结果。
混淆矩阵
混淆矩阵定义如下:
| 预测值 0 | 预测值 1 | |
|---|---|---|
| 真实值 0 | TN | FP |
| 真实值 1 | FN | TP |
记忆方法:真实值更重要,所以真实值处在第一个维度,就是行。
精准率(precision)的定义:
\[
{\rm precision} = \cfrac{TP}{TP+FP}
\]
所以,精准率就是“预测为正例的那些数据里预测正确的数据个数”。
召回率(recall)的定义:
\[{\rm recall} = \cfrac{TP}{TP+FN}\]
所以,召回率就是“真实为正例的那些数据里预测正确的数据个数”。
在不同的应用场景下,我们的关注点不同,例如,在预测股票的时候,我们更关心精准率,即我们预测升的那些股票里,真的升了有多少,因为那些我们预测升的股票都是我们投钱的。而在预测病患的场景下,我们更关注召回率,即真的患病的那些人里我们预测错了情况应该越少越好,因为真的患病如果没有检测出来,结果其实是很严重的,之前那个无脑的算法,召回率就是 0。
精准率和召回率是此消彼长的,即精准率高了,召回率就下降,在一些场景下要兼顾精准率和召回率,就有 F1 score。
F1 score
F1 score 是精准率和召回率的兼顾指标,定义如下:
\[\frac{1}{F1} = \frac{1}{2}(\frac{1}{precision} + \frac{1}{recall})\]
整理一下:
\[F1 = \frac{2 \cdot precision \cdot recall}{precision + recall}\]
其实 F1 score 是精准率和召回率的调和平均数,调和平均数的性质就是,只有当精准率和召回率二者都非常高的时候,它们的调和平均才会高。如果其中之一很低,调和平均就会被拉得接近于那个很低的数。
AUC(Area Under Curve)
AUC 是另一种评价二分类算法的指标,被定义为 ROC 曲线下的面积,显然这个面积的数值不会大于 1。我个人觉得和 F1 score 差不多,都是综合评价精准率和召回率的指标,只不过绘制 ROC 曲线使用了另外两个此消彼长的指标 。
横坐标:假正率(False positive rate, FPR),预测为正但实际为负的样本占所有负例样本的比例;
\[FPR = \frac{FP}{TN + FP}\]
纵坐标:真正率(True positive rate, TPR),这个其实就是召回率,预测为正且实际为正的样本占所有正例样本的比例。
\[TPR = \frac{TP}{TP + FN}\]
诸如逻辑回归这样的分类算法而言,通常预测的都是一个概率值,我们会认为设置一个阈值,超过这个阈值,就预测为其中一类,不超过这个阈值,定义为另外一类。于是,不同的阈值就对应了不同的假正率和真正率,于是通过不同的阈值就形成了假正率和真正率序列,它们就可以在直角坐标系上通过描点成为光滑曲线。这个曲线就是 ROC 曲线,ROC 曲线下的面积就是 AUC。
AUC 高的算法通常认为更好。
那么为什么不用精准率和召回率画曲线求面积呢,其实是完全可以的。
精准率-召回率曲线也叫 pr 曲线,画出来是这样的。
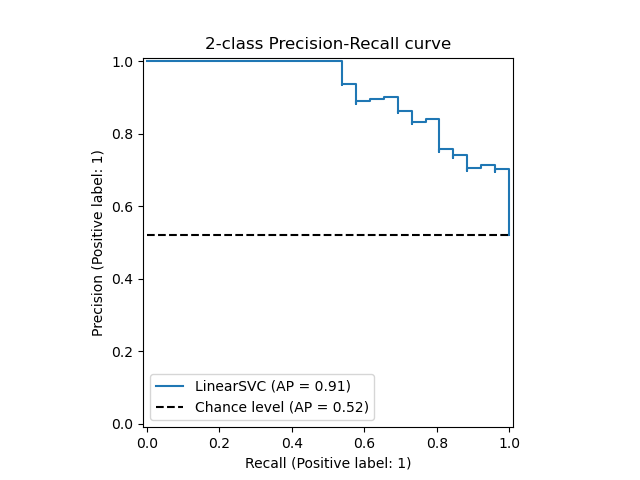
而 roc 曲线画出来是这样的:
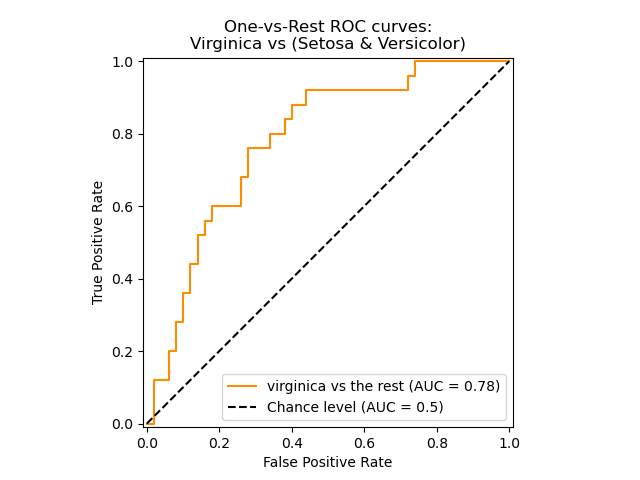
pr 曲线从左到右是下降的,roc 曲线从左到右是上升的,我个人觉得二者都行,只不过最终人们都采用 roc 曲线(上面两张图片都来自 scikit-learn 官方网站)。
参考资料:
机器学习之分类性能度量指标 : ROC曲线、AUC值、正确率、召回率
https://zhwhong.cn/2017/04/14/ROC-AUC-Precision-Recall-analysis/
二分类算法的评价指标:准确率、精准率、召回率、混淆矩阵、AUC的更多相关文章
- 机器学习算法中的准确率(Precision)、召回率(Recall)、F值(F-Measure)
摘要: 数据挖掘.机器学习和推荐系统中的评测指标—准确率(Precision).召回率(Recall).F值(F-Measure)简介. 引言: 在机器学习.数据挖掘.推荐系统完成建模之后,需要对模型 ...
- sklearn调用分类算法的评价指标
sklearn分类算法的评价指标调用#二分类问题的算法评价指标import numpy as npimport matplotlib.pyplot as pltimport pandas as pdf ...
- 【笔记】二分类算法解决多分类问题之OvO与OvR
OvO与OvR 前文书道,逻辑回归只能解决二分类问题,不过,可以对其进行改进,使其同样可以用于多分类问题,其改造方式可以对多种算法(几乎全部二分类算法)进行改造,其有两种,简写为OvO与OvR OvR ...
- 评估指标:准确率(Precision)、召回率(Recall)以及F值(F-Measure)
为了能够更好的评价IR系统的性能,IR有一套完整的评价体系,通过评价体系可以了解不同信息系统的优劣,不同检索模型的特点,不同因素对信息检索的影响,从而对信息检索进一步优化. 由于IR的目标是在较短时间 ...
- 【AUC】二分类模型的评价指标ROC Curve
AUC是指:从一堆样本中随机抽一个,抽到正样本的概率比抽到负样本的概率大的可能性! AUC是一个模型评价指标,只能用于二分类模型的评价,对于二分类模型,还有很多其他评价指标,比如logloss,acc ...
- matlab 实现感知机线性二分类算法(Perceptron)
感知机是简单的线性分类模型 ,是二分类模型.其间用到随机梯度下降方法进行权值更新.参考他人代码,用matlab实现总结下. 权值求解过程通过Perceptron.m函数完成 function W = ...
- 推荐系统评测指标—准确率(Precision)、召回率(Recall)、F值(F-Measure)
下面简单列举几种常用的推荐系统评测指标: 1.准确率与召回率(Precision & Recall) 准确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量.其中精度 ...
- 推荐系统评测指标--准确率(Precision)和召回率(Recall)、F值(F-Measure)
转自http://bookshadow.com/weblog/2014/06/10/precision-recall-f-measure/ 1,准确率和召回率是广泛应用于信息检索和统计学分类领域的两个 ...
- logistic regression二分类算法推导
随机推荐
- win7启动tomcat失败处理
本地启动tomcat 后访问 127.0.0.1:8080 失败,查看错误如下 使用如下命令杀死占用8080的进程 netstat -ano | findstr 8080 # 查看8080端口状态 t ...
- 关于js计算非等宽字体宽度的方法
准备一个容器 首先在body外插入一个absolute的容器避免重绘: const svgWidthTestContainer = document.createElement('svg'); svg ...
- Android 调用摄像头功能【拍照与视频】
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/ma_hoking/article/details/28292973 应用场景: 在Android开发 ...
- 字符串连连看 (和hihocoder 字符消除类似)
题目描述 对于输入的字符串,从左到右扫描字符串,如果存在由三个以上(包括三个)连续相同字符组成的子串,就将这个子串从原串中去掉,并将原有字符串剩下的部分拼接到一起.重复上述过程,直到无法去掉任何子串 ...
- java实现spark常用算子之collect
import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.a ...
- vue-cli设置引入目录
打开build/webpack.base.conf.js 找到module.exports下的resolve这行 刚开始是这样的 resolve: { extensions: ['.js', '.vu ...
- Scala Nothing 从官方DOC翻译
Nothing is - together with scala.Null - at the bottom of Scala's type hierarchy. Scala中的Nothing和Null ...
- Linux学习--第十天--bash脚本、用户自定义变量、环境变量、位置参数变量、预定义变量、标准输入输出、wc、history、dd、PS1
shell简介 分为两种c shell 和b shell b shell:sh.ksh.Bash.psh.zsh: (Bash和sh兼容,linux基本shell是Bash) c shell:csh. ...
- BZOJ[3252]攻略(长链剖分)
BZOJ[3252]攻略 Description 题目简述:树版[k取方格数] 众所周知,桂木桂马是攻略之神,开启攻略之神模式后,他可以同时攻略k部游戏.今天他得到了一款新游戏<XX半岛> ...
- C#任务Task
完整调用 TaskCreationOptions tcOptions = TaskCreationOptions.PreferFairness | TaskCreationOptions.LongRu ...