3、激活层(Activiation Layers)及参数
caffe激活层(Activiation Layers)
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的。从bottom得到一个blob数据输入,运算后,从top输入一个blob数据。在运算过程中,没有改变数据的大小,即输入和输出的数据大小是相等的。
输入:n*c*h*w
输出:n*c*h*w
常用的激活函数有sigmoid, tanh,relu等
1、Sigmoid
原型:
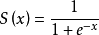
层类型:Sigmoid
layer {
name: "encode1neuron"
bottom: "encode1"
top: "encode1neuron"
type: "Sigmoid"
}
2、ReLU / Rectified-Linear and Leaky-ReLU
ReLU是目前使用最多的激活函数,主要因为其收敛更快,并且能保持同样效果。
标准的ReLU函数为max(x, 0),当x>0时,输出x; 当x<=0时,输出0
f(x)=max(x,0)
层类型:ReLU
可选参数:
negative_slope:默认为0. 对标准的ReLU函数进行变化,如果设置了这个值,那么数据为负数时,就不再设置为0,而是用原始数据乘以negative_slope
layer {
name: "relu1"
type: "ReLU"
bottom: "pool1"
top: "pool1"
}
3、TanH / Hyperbolic Tangent
利用双曲正切函数对数据进行变换。
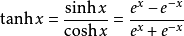
层类型:TanH
layer {
name: "layer"
bottom: "in"
top: "out"
type: "TanH"
}
4、Absolute Value
求每个输入数据的绝对值。
f(x)=Abs(x)
层类型:AbsVal
layer {
name: "layer"
bottom: "in"
top: "out"
type: "AbsVal"
}
5、Power
对每个输入数据进行幂运算
f(x)= (shift + scale * x) ^ power
层类型:Power
可选参数:
power: 默认为1
scale: 默认为1
shift: 默认为0
layer {
name: "layer"
bottom: "in"
top: "out"
type: "Power"
power_param {
power: 2
scale: 1
shift: 0
}
}
6、BNLL
binomial normal log likelihood的简称
f(x)=log(1 + exp(x))
层类型:BNLL
layer {
name: "layer"
bottom: "in"
top: "out"
type: “BNLL”
}
参考:http://www.cnblogs.com/denny402/p/5072507.html
3、激活层(Activiation Layers)及参数的更多相关文章
- Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
- 转 Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
- [转] caffe视觉层Vision Layers 及参数
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. 1.Convolution层: 就是卷积层,是卷积神经 ...
- caffe(4) 激活层(Activation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
- 【转】Caffe初试(六)激活层及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- [转] caffe激活层及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
- 激活层和pooling的作用
激活层: 激活函数其中一个重要的作用是加入非线性因素的,将特征映射到高维的非线性区间进行解释,解决线性模型所不能解决的问题 pooling层: 1. invariance(不变性),这种不变性包括tr ...
随机推荐
- 基于HTML5的RDP访问实战
基于HTML5的RDP访问实战 1.安装guacamole 2.下载源码 3.安装服务端 安装报错 错误 参考 http://www.remotespark.com/html5.html ...
- SetDns.bat 2014-03-28 20:00:19
此BAT文件,可以帮助便捷切换dns设置,Win7系统需使用管理员身份运行. @echo off echo 设置为GoogleDNS(1)/dhcp(2)/OpenDNS(3) set /p sel= ...
- HBase批量插入的简单代码
由于项目需要从HBase里读取数据,进行MapReduce之后输出到HDFS中. 为了测试方便,我这里写了一个批量插入HBase数据的测试代码.采用的Maven工程. 打算,今后的所有用到的小测试例子 ...
- linux tomcat自动部署shell
#!/bin/bash #defined TOMCAT_HOME="/usr/java/tomcat/tomcat" TOMCAT_PORT=80 PROJECT ...
- 通过cat方式生成yum源
cat >> /etc/yum.repos.d/centos7.repo << EOF[test-iso7]name=CentOS- - Mediabaseurl=http:/ ...
- HDU 4126 Genghis Khan the Conqueror (树形DP+MST)
题意:给一图,n个点,m条边,每条边有个花费,给出q条可疑的边,每条边有新的花费,每条可疑的边出现的概率相同,求不能经过原来可疑边 (可以经过可疑边新的花费构建的边),注意每次只出现一条可疑的边,n个 ...
- java Calender类
1.Calender和Date相互转化 public static void main(String[] args) { // TODO Auto-generated method stub Cale ...
- 浅说Java反射机制
工作中遇到,问题解决: JAVA语言中的反射机制: 在Java 运行时 环境中,对于任意一个类,能否知道这个类有哪些属性和方法? 对于任意一个对象,能否调用他的方法?这些答案是肯定的,这种动态获取类的 ...
- 学习tomcat(一)----用IDEA调试tomcat源码
一直在使用tomcat,但却不怎么熟悉tomcat的"运作流程",今天就 参照参考文章进行了代码搭建(代码的github在文末),并修改了一些操作.学习下tomcat的" ...
- 深入理解java虚拟机(八)类加载过程详解
类从被加载到虚拟机内存开始,到卸载出内存为止,它的整个生命周期包括:加载(Loading).验证(Verification).准备(Preparation).解析(Resolution).初始化(In ...