Springboot+ELK实现日志系统简单搭建
前面简单介绍了ELK三剑客中的其中两个Elasticsearch和Kibana的简单使用,如果对这两个不了解,可以看下下面的
现在来看看这最后一个Logstash
还是这个地方https://elasticsearch.cn/download/ 下载与es,kibana版本对应的Logstash,然后解压。
1.和es一样,如果机器内存小,有想玩这个的,记得把config下面的jvm.options文件中的jvm参数设置小点,我设置的256m:
-Xms256m
-Xmx256m
2.写配置文件logstash.conf,默认有个logstash-sample.conf这个文件,可以直接拿来修改
内容如下:
#暴露9090端口作为输入
input {
tcp {
#host 192.168.0.69
port => 9090
}
}
#输出到elasticsearch,此输出创建一个名为myserver的索引
output {
elasticsearch {
hosts => ["http://192.168.0.67:9200"]
index => "myserver"
}
}
以上就是最简单的配置了
3.使用此配置文件启动logstash:./bin/logstash -f ./config/logstash.conf

4.创建spingboot工程,springboot日志本来就用的logback,但是我们还需要引入相关的logstash依赖
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>6.2</version>
</dependency>
5.在appliction.properties配置文件指定logstash服务的端口位置,就是上面logstash 暴露出来的输入端口,我们上面的是9090端口
logstash.address=192.168.0.69:9090
6.logback日志配置文件:logback-spring.xml(resources下面和工程appliction配置文件同级)
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--logstash地址,从application.properties中获取-->
<springProperty scope="context" name="LOGSTASH_ADDRESS" source="logstash.address"/> <!--输出到logstash的appender-->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!--可以访问的logstash日志收集端口-->
<destination>${LOGSTASH_ADDRESS}</destination>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>Asia/Shanghai</timeZone>
</timestamp>
<pattern>
<pattern>
{
"app": "my-server",
"level": "%level",
"thread": "%thread",
"logger": "%logger{50} %M %L ",
"message": "%msg"
}
</pattern>
</pattern>
<stackTrace>
<throwableConverter class="net.logstash.logback.stacktrace.ShortenedThrowableConverter">
<maxDepthPerThrowable>100</maxDepthPerThrowable>
<rootCauseFirst>true</rootCauseFirst>
<inlineHash>true</inlineHash>
</throwableConverter>
</stackTrace>
</providers>
</encoder>
</appender> <root level="INFO">
<appender-ref ref="LOGSTASH"/>
</root>
</configuration>
7.启动springboot服务,这个时候我们会发现控制台不会再输出日志了,因为日志输出到logstash,再由logstash发送到es去了。
调用我们接口查看下服务是否成功启动了

说明服务已经成功启动,现在去看kibana查看日志信息
8.搜索是否有myserver的索引,可以看到tomcat 8080端口启动的日志

我们每次都这样搜索来看是不是很不方便,我们可以把这个索引加到discover中,后续只需要在里面搜索我们想要内容就行了
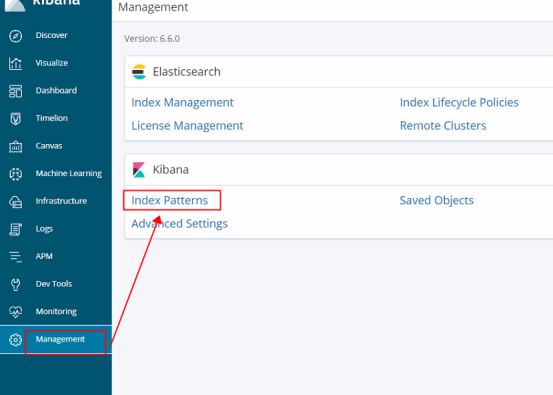
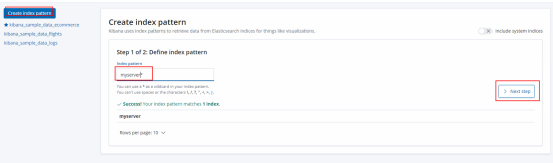
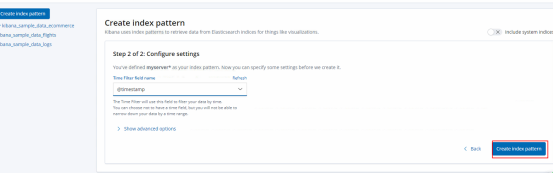
9.Management --->Index Patterns --->Create index pattern--->搜索匹配的索引然后创建
创建好了就可以在kibana的index列表看见这个索引了
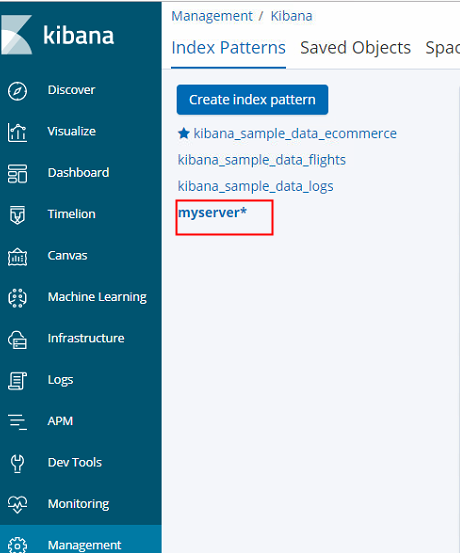
现在就可以discover中使用这个索引了,不用再去dev tools工具中去写查询了

我们着看刚才调用接口打印的日志就可以在discover中看见了
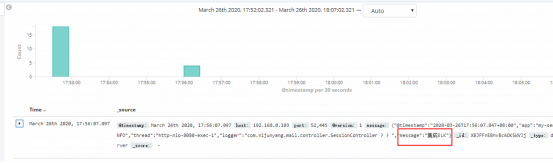
10.discover中信息筛选:默认的筛选时间是15分钟内的,如果时间比较久了就需要重新选择下时间,然后输入要搜索的内容port,我们就可以看到之前服务起动的日志了
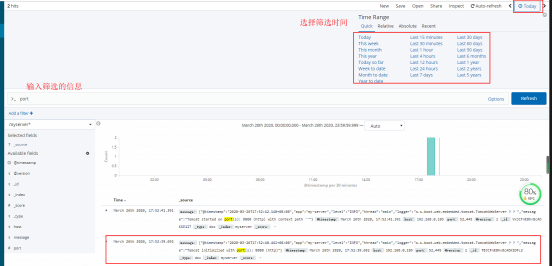
ELK简单的集成使用,大概就是这个样子了,当然logstash中还可以去过滤处理数据。像我们现在的日志在kibana里面的格式是很难看的。
Springboot+ELK实现日志系统简单搭建的更多相关文章
- ELK分布式日志系统的搭建
前言 ELK即分别为ElasticSearch.Logstash(收集.分析.过滤日志的工具).Kibana(es的可视化工具),其主要工作原理就是由不同机器上的logstash收集日志后发送给es, ...
- 【7.1.1】ELK日志系统单体搭建
ELK是什么? 一般来说,为了提高服务可用性,服务器需要部署多个实例,每个实例都是负载均衡转发的后的,如果还用老办法登录服务器去tail -f xxx.log,有很大可能错误日志未出现在当前服务器中, ...
- .NET下日志系统的搭建——log4net+kafka+elk
.NET下日志系统的搭建--log4net+kafka+elk 前言 我们公司的程序日志之前都是采用log4net记录文件日志的方式(有关log4net的简单使用可以看我另一篇博客),但是随着 ...
- ELK +Nlog 分布式日志系统的搭建 For Windows
前言 我们为啥需要全文搜索 首先,我们来列举一下关系型数据库中的几种模糊查询 MySql : 一般情况下LIKE 模糊查询 SELECT * FROM `LhzxUsers` WHERE UserN ...
- ELK统一日志系统的应用
收集和分析日志是应用开发中至关重要的一环,互联网大规模.分布式的特性决定了日志的源头越来越分散, 产生的速度越来越快,传统的手段和工具显得日益力不从心.在规模化场景下,grep.awk 无法快速发挥作 ...
- Ubuntu学习笔记-win7&Ubuntu双系统简单搭建系统指南
win7&Ubuntu双系统简单搭建系统指南 本文是自己老本子折腾Ubuntu的一些记录,主要是搭建了一个能够足够娱乐(不玩游戏)专注练习自己编程能力的内容.只是简单的写了关于系统的安装和一些 ...
- springboot+ELK+logback日志分析系统demo
之前写的有点乱,这篇整理了一下搭建了一个简单的ELK日志系统 借鉴此博客完成:https://blog.csdn.net/qq_22211217/article/details/80764568 设置 ...
- mysql日志系统简单使用
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品.MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBM ...
- springboot elk实时日志搭建
https://blog.csdn.net/yy756127197/article/details/78873310 基本的上的过程如这篇博客,logback的配置文件和依赖不太一样 具体见源码其中的 ...
- ELK+Kafka日志收集环境搭建
1.搭建Elasticsearch环境并测试: (1)删除es的容器 (2)删除es的镜像 (3)宿主机调内存: 执行命令:sudo sysctl -w vm.max_map_count=655360 ...
随机推荐
- Go笔记(4)-流程控制
5.Go语言流程控制 程序流程的控制结构一般有三种,顺序结构,选择结构,循环结构 (1)选择结构 if语句 if流程控制与其他语言的if流程控制基本相同 package main import &qu ...
- [ABC328D] Take ABC 题解
题目翻译 题目描述 给你一个字符串 \(S\) 包含 A.B 和 C 三个不用的字符. 只要字符串 \(S\) 中包含连续的 ABC 就将 ABC 删除掉 再字符串 \(S\) 不能操作之后输出这个字 ...
- [ABC284G] Only Once
Problem Statement For a sequence of length $N$, $A = (A_1,A_2,\dots,A_N)$, consisting of integers be ...
- Chrome扩展的核心:manifest 文件(上)
大家好,我是dom哥.我正在写关于 Chrome 扩展开发的系列文章,感兴趣的可以点个小星星. Chrome 在全球浏览器市场份额独占 6 成,无论是对普通用户还是开发者,都是电脑里的必备利器.Chr ...
- zookeeper JavaApi 创建节点
import org.apache.curator.RetryPolicy; import org.apache.curator.framework.CuratorFramework; import ...
- Spring系列:基于Spring-AOP和Spring-Aspects实现AOP切面编程
目录 一.概念及相关术语 概念 相关术语 ①横切关注点 ②通知(增强) ③切面 ④目标 ⑤代理 ⑥连接点 ⑦切入点 作用 二.基于注解的AOP 技术说明 准备工作 创建切面类并配置 各种通知 切入点表 ...
- JDK8提供的常用计量单位
时间计量单位:Duration @DurationUnit(ChronoUnit.HOURS) private Duration serverTimeout; 空间计量单位:DataSize @Dat ...
- JXNU acm选拔赛 最小的数
最小的数 Time Limit : 3000/1000ms (Java/Other) Memory Limit : 65535/32768K (Java/Other) Total Submissi ...
- bash shell笔记整理——cd命令、目录路径
cd---change directory 改变目录的意思 语法: cd [选项] <目录> 选项: -L 会自动进入符号连接目录(默认) -P 进入符号连接目录的真实目录下. 常用: 命 ...
- Spingboot整合Dubbo+zookeeper
前言: 2023-12-26 19:38:05 最近学习分布式技术:Dubbo+zookeeper,准备写一个demo用springboot整合dubbo和zookeeper.但是看了网上一些教程都是 ...