从0开始学爬虫12之使用requests库基本认证
从0开始学爬虫12之使用requests库基本认证
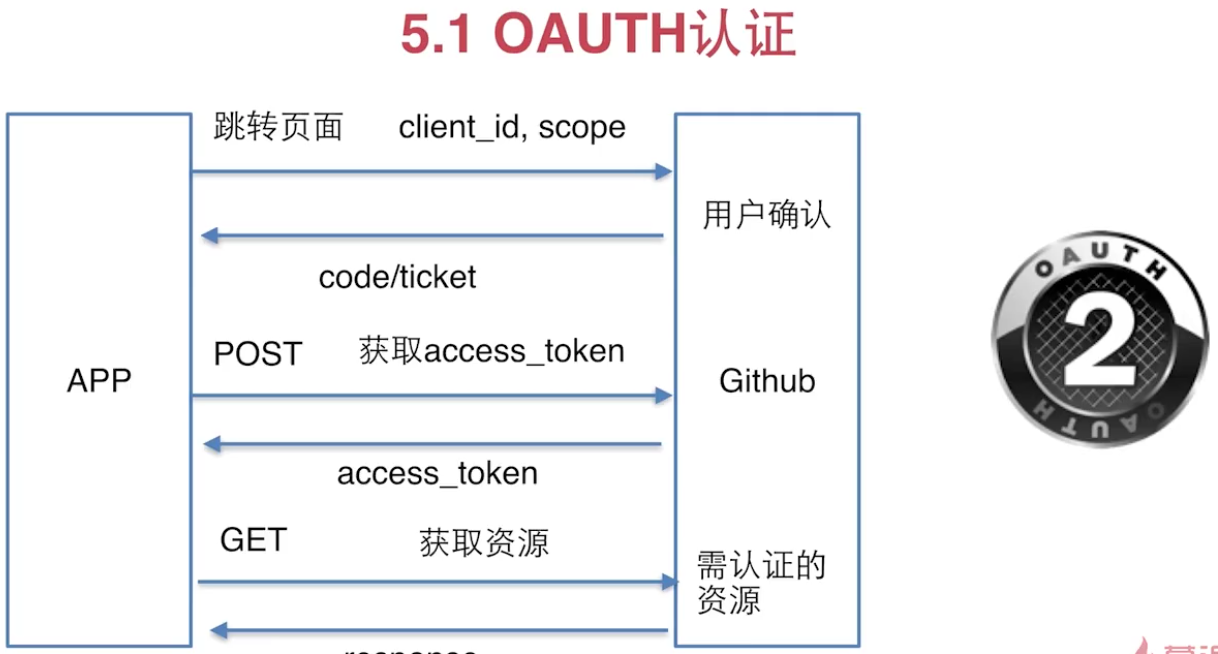
此处我们使用github的token进行简单测试验证

# coding=utf-8 import requests BASE_URL = "https://api.github.com" def construct_url(endpoint):
return '/'.join([BASE_URL, endpoint]) def basic_auth():
'''
基本认证
:return:
''' response = requests.get(construct_url('user'), auth=('reblue520','reblue520'))
print response.text
print response.status_code
print response.request.headers def basic_oauth():
# 添加github中添加的token认证
headers = {'Authorization': 'token 748fa57d10'}
# user/emails
response = requests.get(construct_url('user/emails'), headers=headers)
print response.request.headers
print response.text
print response.status_code from requests.auth import AuthBase class GithubAuth(AuthBase):
# 自定义auth,对aut进行优化
def __init__(self, token):
self.token = token def __call__(self, r):
# requests 加 headers信息
r.headers['Authorization'] = ' '.join(['token', self.token])
return r def oath_advanced():
auth = GithubAuth('748fa57d10')
response = requests.get(construct_url('user/emails'), auth=auth)
print response.text if __name__ == '__main__':
# basic_auth()
# basic_oauth()
oath_advanced()
从0开始学爬虫12之使用requests库基本认证的更多相关文章
- 从0开始学爬虫11之使用requests库下载图片
从0开始学爬虫11之使用requests库下载图片 # coding=utf-8 import requests def download_imgage(): ''' demo: 下载图片 ''' h ...
- 从0开始学爬虫9之requests库的学习之环境搭建
从0开始学爬虫9之requests库的学习之环境搭建 Requests库的环境搭建 环境:python2.7.9版本 参考文档:http://2.python-requests.org/zh_CN/l ...
- 从0开始学爬虫8使用requests/pymysql和beautifulsoup4爬取维基百科词条链接并存入数据库
从0开始学爬虫8使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 Python使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 参考 ...
- 从0开始学爬虫4之requests基础知识
从0开始学爬虫4之requests基础知识 安装requestspip install requests get请求:可以用浏览器直接访问请求可以携带参数,但是又长度限制请求参数直接放在URL后面 P ...
- 从0开始学爬虫3之xpath的介绍和使用
从0开始学爬虫3之xpath的介绍和使用 Xpath:一种HTML和XML的查询语言,它能在XML和HTML的树状结构中寻找节点 安装xpath: pip install lxml HTML 超文本标 ...
- 从0开始学爬虫2之json的介绍和使用
从0开始学爬虫2之json的介绍和使用 Json 一种轻量级的数据交换格式,通用,跨平台 键值对的集合,值的有序列表 类似于python中的dict Json中的键值如果是字符串一定要用双引号 jso ...
- Python爬虫利器一之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- (转)Python爬虫利器一之Requests库的用法
官方文档 以下内容大多来自于官方文档,本文进行了一些修改和总结.要了解更多可以参考 官方文档 安装 利用 pip 安装 $ pip install requests 或者利用 easy_install ...
- 网络爬虫必备知识之requests库
就库的范围,个人认为网络爬虫必备库知识包括urllib.requests.re.BeautifulSoup.concurrent.futures,接下来将结对requests库的使用方法进行总结 1. ...
随机推荐
- littlefs了解一下
littlefs是一个文件系统,断电数据不会出异常,适合IOT场景.
- CS229开源项目
斯坦福大学CS 229机器学习备忘单: https://github.com/kaobeixingfu/stanford-cs-229-machine-learning CS229机器学习算法的Pyt ...
- 判断指定对象是否进入浏览器可视窗口,true 进入,false 没进入
//判断指定对象是否进入浏览器可视窗口,true 进入,false 没进入 var $win = $(window);//jQuery 的 window 对象 即:文档对象 function isVi ...
- 在新浪SAE上搭建微信公众号的python应用
微信公众平台的开发者文档https://www.w3cschool.cn/weixinkaifawendang/ python,flask,SAE(新浪云),搭建开发微信公众账号http://www. ...
- 搭建使用PHPstorm环境
本周学习内容: 1.学习PHP: 2.复习技能表: 3.学习正则表达式: 实验内容: 1.安装PHPstorm环境,破解PHPstorm: 2.PHPstorm运行PHP代码 3.PHPstorm安装 ...
- 【转】根据Quartz-Cron表达式获取最近几次执行时间
public static List<String> getRecentTriggerTime(String cron) { List<String> list = new A ...
- luogu 3466 对顶堆
显然答案是将一段区间全部转化成了其中位数这样的话,需要维护一个数据结构支持查询当前所有数中位数对顶堆 用两个堆将 < 中位数的数放入大根堆将 > 中位数的数放入小根堆这样就会存在删除操作 ...
- noi.ac #37 dp计数
#include<algorithm> #include<cstring> #include<cstdio> #include<iostream> ty ...
- PKUSC2019 改题记录
PKUSC2019 改题记录 我真的是个sb... 警告:不一定是对的... D1T1 有一个国家由\(n\)个村庄组成,每个村庄有一个人.对每个\(i\in[1,n-1],\)第\(i\)个村庄到第 ...
- @RestController和@GetMapping
@RestController 可以代替@Controller使用,使用了@RestController的控制器默认所有请求方法都用了@ResponseBody注解. @GetMapping(&quo ...