从0开始学爬虫11之使用requests库下载图片
从0开始学爬虫11之使用requests库下载图片
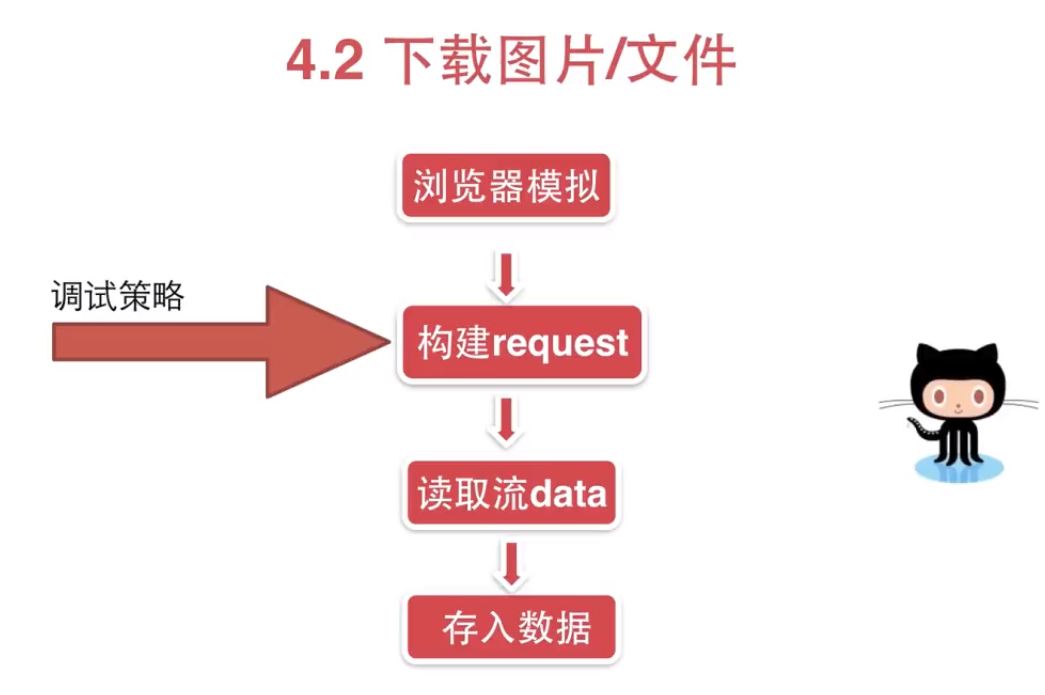
# coding=utf-8
import requests def download_imgage():
'''
demo: 下载图片
'''
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
url = "https://ss0.bdstatic.com/94oJfD_bAAcT8t7mm9GUKT-xh_/timg?image&quality=100&size=b4000_4000&sec=1563595148&di=1239a9121c930e1ab892faa7cd0b8f8a&src=http://m.360buyimg.com/pop/jfs/t23434/230/1763906670/10667/55866a07/5b697898N78cd1466.jpg"
response = requests.get(url,headers=headers, stream=True)
with open('demo.jpg', 'wb') as fd:
for chunk in response.iter_content(128):
fd.write(chunk) print response.content def download_image_improved():
# 伪造headers信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
# 限定url
url = "https://ss0.bdstatic.com/94oJfD_bAAcT8t7mm9GUKT-xh_/timg?image&quality=100&size=b4000_4000&sec=1563595148&di=1239a9121c930e1ab892faa7cd0b8f8a&src=http://m.360buyimg.com/pop/jfs/t23434/230/1763906670/10667/55866a07/5b697898N78cd1466.jpg"
response = requests.get(url, headers=headers, stream=True)
# contextlib 管理上下文信息
from contextlib import closing
# 可以关闭文件流
with closing(requests.get(url, headers=headers, stream=True)) as response:
# 打开文件
with open('demo1.jpg', 'wb') as fd:
# 每128字节写入一次
for chunk in response.iter_content(128):
fd.write(chunk) if __name__ == '__main__':
# download_imgage()
download_image_improved()
从0开始学爬虫11之使用requests库下载图片的更多相关文章
- 从0开始学爬虫12之使用requests库基本认证
从0开始学爬虫12之使用requests库基本认证 此处我们使用github的token进行简单测试验证 # coding=utf-8 import requests BASE_URL = " ...
- 从0开始学爬虫9之requests库的学习之环境搭建
从0开始学爬虫9之requests库的学习之环境搭建 Requests库的环境搭建 环境:python2.7.9版本 参考文档:http://2.python-requests.org/zh_CN/l ...
- 从0开始学爬虫8使用requests/pymysql和beautifulsoup4爬取维基百科词条链接并存入数据库
从0开始学爬虫8使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 Python使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 参考 ...
- 从0开始学爬虫4之requests基础知识
从0开始学爬虫4之requests基础知识 安装requestspip install requests get请求:可以用浏览器直接访问请求可以携带参数,但是又长度限制请求参数直接放在URL后面 P ...
- 从0开始学爬虫3之xpath的介绍和使用
从0开始学爬虫3之xpath的介绍和使用 Xpath:一种HTML和XML的查询语言,它能在XML和HTML的树状结构中寻找节点 安装xpath: pip install lxml HTML 超文本标 ...
- 从0开始学爬虫2之json的介绍和使用
从0开始学爬虫2之json的介绍和使用 Json 一种轻量级的数据交换格式,通用,跨平台 键值对的集合,值的有序列表 类似于python中的dict Json中的键值如果是字符串一定要用双引号 jso ...
- Python爬虫利器一之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- (转)Python爬虫利器一之Requests库的用法
官方文档 以下内容大多来自于官方文档,本文进行了一些修改和总结.要了解更多可以参考 官方文档 安装 利用 pip 安装 $ pip install requests 或者利用 easy_install ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
随机推荐
- 【技术分享】linux各种一句话反弹shell总结——攻击者指定服务端,受害者主机(无公网IP)主动连接攻击者的服务端程序(CC server),开启一个shell交互,就叫反弹shell。
反弹shell背景: 想要搞清楚这个问题,首先要搞清楚什么是反弹,为什么要反弹.假设我们攻击了一台机器,打开了该机器的一个端口,攻击者在自己的机器去连接目标机器(目标ip:目标机器端口),这是比较常规 ...
- 51nod 2488 矩形并的面积
在二维平面上,给定两个矩形,满足矩形的每条边分别和坐标轴平行,求这个两个矩形的并的面积.即它们重叠在一起的总的面积. 收起 输入 8个数,分别表示第一个矩形左下角坐标为(A,B),右上角坐标为(C ...
- BOM常用属性与方法
BOMBrowser Object Modelwindow浏览器窗口window方法locationlocation常用属性screen显示器屏幕screen常用属性navigator浏览器软件nav ...
- littlefs了解一下
littlefs是一个文件系统,断电数据不会出异常,适合IOT场景.
- windows nginx 目录配置
http { server { listen 80; server_name www.test.com; location / { root E:/data/www; index index.html ...
- matlab的diff()函数
diff():求差分 一阶差分 X = [1 1 2 3 5 8 13 21]; Y = diff(X) 结果: Y = 0 1 1 2 3 5 8 X = [1 1 1; 5 5 5; 25 25 ...
- 对日开发中 PG , PL , SE , PM 是什么
PG(ProGramer)指程序员. 这类人才在企业中所占数量最多,通常占到整个项目员工数的70%,也是企业中最紧缺的一类职位,一般为具有专业知识的软件工程技术人员. PL(project leade ...
- codevs1504愚蠢的组合数 / RQNOJ愚蠢的组合数
1504 愚蠢的组合数 时间限制: 2 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题解 题目描述 Description 最近老师教了狗狗怎么算组合数,狗狗又 ...
- 行列式的组合定义及其应用--反对称阵的Pfaffian
以组合定义为出发点的行列式理论的引入方式在很多高等代数或线性代数的教材中被采用, 其优缺点同样明显. 组合定义形式上的简单是其最大的优点, 用它可以简洁地证明行列式的所有性质, 并快速进入行列式的计算 ...
- OpenStack RPC框架解析
1 消息队列Rabbitmq介绍 Rabbitmq的整体架构图 (1)Rabbitmq Server:中间那部分就是Rabbitmq Server,也叫broken server,主要是负责消息的传 ...