从0开始学爬虫2之json的介绍和使用
从0开始学爬虫2之json的介绍和使用
Json
- 一种轻量级的数据交换格式,通用,跨平台
- 键值对的集合,值的有序列表
- 类似于python中的dict
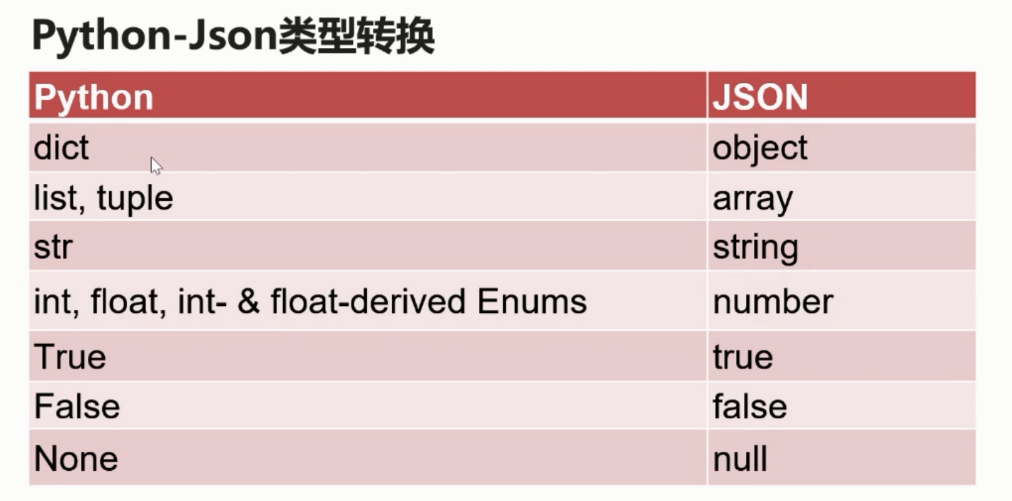
Json中的键值如果是字符串一定要用双引号
json文件static/book.json
{
"name": "Python书籍",
"origin_price": ,
"pub_date": "2018-4-14 17:00:00",
"store": ["京东","淘宝"],
"author": ["张三","李四","Jhone"],
"is_valid":true,
"is_sale": false,
"meta":{
"isbn":"abc-123",
"pages":
},
"desc":null
}
Json的常用方法练习use_json.py
#coding=utf-8 import json def python_to_json():
"""将python对象转换成json"""
d = {
'name': 'python书籍',
'price':62.3,
'is_valid': True
}
# intend是加入缩进效果
rest = json.dumps(d, indent=4)
print(rest) def json_to_python():
""" 将json转换成python """
data = '''
{
"name": "Python书籍",
"origin_price": 66,
"pub_date": "2018-4-14 17:00:00",
"store": ["京东","淘宝"],
"author": ["张三","李四","Jhone"],
"is_valid":true,
"is_sale": false,
"meta":{
"isbn":"abc-123",
"pages":300
},
"desc":null
}
'''
rest = json.loads(data)
print(rest) def json_to_python_from_file():
"""从文件读取内容并转换为python对象"""
f = open('./static/book.json', 'r', encoding='utf-8') s = f.read()
print(s)
rest = json.loads(s)
print(rest["name"]) f.close() if __name__ == '__main__':
python_to_json()
# json_to_python()
# json_to_python_from_file()
从0开始学爬虫2之json的介绍和使用的更多相关文章
- 从0开始学爬虫3之xpath的介绍和使用
从0开始学爬虫3之xpath的介绍和使用 Xpath:一种HTML和XML的查询语言,它能在XML和HTML的树状结构中寻找节点 安装xpath: pip install lxml HTML 超文本标 ...
- 从0开始学爬虫4之requests基础知识
从0开始学爬虫4之requests基础知识 安装requestspip install requests get请求:可以用浏览器直接访问请求可以携带参数,但是又长度限制请求参数直接放在URL后面 P ...
- 从0开始学爬虫12之使用requests库基本认证
从0开始学爬虫12之使用requests库基本认证 此处我们使用github的token进行简单测试验证 # coding=utf-8 import requests BASE_URL = " ...
- 从0开始学爬虫11之使用requests库下载图片
从0开始学爬虫11之使用requests库下载图片 # coding=utf-8 import requests def download_imgage(): ''' demo: 下载图片 ''' h ...
- 从0开始学爬虫9之requests库的学习之环境搭建
从0开始学爬虫9之requests库的学习之环境搭建 Requests库的环境搭建 环境:python2.7.9版本 参考文档:http://2.python-requests.org/zh_CN/l ...
- 从0开始学爬虫8使用requests/pymysql和beautifulsoup4爬取维基百科词条链接并存入数据库
从0开始学爬虫8使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 Python使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 参考 ...
- 从0开始学爬虫10之urllib和requests库与github/api的交互
urllib库的使用 # coding=utf-8 import urllib2 import urllib # htpbin模拟的环境 URL_IP="http://10.11.0.215 ...
- 从0开始学爬虫7之BeautifulSoup模块的简单介绍
参考文档: https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ # 安装 beautifulsoup4 (pytools) D:\pyt ...
- 一起学爬虫——使用selenium和pyquery爬取京东商品列表
layout: article title: 一起学爬虫--使用selenium和pyquery爬取京东商品列表 mathjax: true --- 今天一起学起使用selenium和pyquery爬 ...
随机推荐
- 开发搭建环境之springboot配置logback日志管理
首先书写logback-spring.xml文件为: <?xml version="1.0" encoding="UTF-8"?><confi ...
- EF映射——从数据库更新实体
最近在做ITOO项目,由于更新了数据库,需要重新从数据库映射到实体,本来看过关于EF的学习资料,直接可以从数据库更新到实体,但这种小事也是有很多问题的,必须在更新的时候做好选择.下面分享一下如何从数据 ...
- 帝国CMS熊掌号数据主动推送插件【原创】
因为昨晚一个朋友他是帝国CMS做的网站,叫我给他做个熊掌号改造和熊掌号推送,所以花了一个小时时间做了这个插件,有需要的朋友可以拿去. 第一步:在后台执行以下数据库语句: CREATE TABLE `b ...
- docker创建Webvirtmgr容器
链接:https://hub.docker.com/r/unws/webvirtmgr/ Webvirtmgr Dockerfile 拉起镜像并创建webvirtmgr用户和组(注意uid和guid必 ...
- CheckList 如何梳理可减少上线的验证时间(总结篇)
对CheckList的执行发起的思考? (1)功能越来越多,CheckList越补充越多,执行CheckList时间越来越长,如何减少上线的验证时间?(2)减少上线验证的时间外,如何保证质量?上线后少 ...
- Linux PAM 之cracklib模块
如何在Linux系统中限制密码长度的同时对密码的复杂程度也进行管理,最近发现有人的密码符合长度规则,但是却很简单很容易被猜出来,查了相关资料后发现了PAM中的pam_cracklib模块就是用来 ...
- ES基本搜索(1)
1.空搜索 GET <写路径>/_search 返回的结果: eg: GET propdict/doc/_search { , "timed_out": false, ...
- 【贪心】Communication System POJ 1018
题目链接:http://poj.org/problem?id=1018 题目大意:有n种通讯设备,每种有mi个制造商,bi.pi分别是带宽和价格.在每种设备中选一个制造商让最小带宽B与总价格P的比值B ...
- UWB DWM1000 开源项目框架 之 温度采集
在之前博文开源一套uwb 框架,后面几篇博文会基于这个开源框架进行简单开发. 让uwb使用者更清楚了解基于这个basecode 开发工作. 这里所做内容是,采集dwm1000 温度,并发送到另一个节点 ...
- Codeforces Round #609 (Div. 2) 【A,B,C】
题意:给一个n<=1e7,找两个合数a和b使得a-b的差为n. 构造a=3n,b=2n,必含有公因子n,只有当n是1的时候是特例. #include<bits/stdc++.h> u ...