“达观杯”文本分类--baseline
结合tfidf权重,对“达观杯”提供的文本,进行文本分类,作为baseline,后续改进均基于此。
1.比赛地址及数据来源
2.代码及解析
# -*- coding: utf-8 -*- """
@简介:tfidf特征/ SVM模型
@成绩: 0.77
"""
#导入所需要的软件包
import pandas as pd
from sklearn.svm import LinearSVC
from sklearn.feature_extraction.text import TfidfVectorizer print("开始...............") #====================================================================================================================
# @代码功能简介:从硬盘上读取已下载好的数据,并进行简单处理
# @知识点定位:数据预处理
#====================================================================================================================
df_train = pd.read_csv('./data/train_set.csv') # 数据读取
df_test = pd.read_csv('./data/test_set.csv') # 观察数据,原始数据包含id、article(原文)列、word_seg(分词列)、class(类别标签)
df_train.drop(columns=['article', 'id'], inplace=True) # drop删除列
df_test.drop(columns=['article'], inplace=True) #==========================================================
# @代码功能简介:将数据集中的字符文本转换成数字向量,以便计算机能够进行处理(一段文字 ---> 一个向量)
# @知识点定位:特征工程
#==========================================================
vectorizer = TfidfVectorizer(ngram_range=(1, 2), min_df=3, max_df=0.9)
'''
ngram_range=(1, 2) : 词组长度为1和2
min_df : 忽略出现频率小于3的词
max_df : 忽略在百分之九十以上的文本中出现过的词
'''
vectorizer.fit(df_train['word_seg']) # 构造tfidf矩阵
x_train = vectorizer.transform(df_train['word_seg']) # 构造训练集的tfidf矩阵
x_test = vectorizer.transform(df_test['word_seg']) # 构造测试的tfidf矩阵 y_train = df_train['class']-1 #训练集的类别标签(减1方便计算) #==========================================================
# @代码功能简介:训练一个分类器
# @知识点定位:传统监督学习算法之线性逻辑回归模型
#========================================================== classifier = LinearSVC() # 实例化逻辑回归模型
classifier.fit(x_train, y_train) # 模型训练,传入训练集及其标签 #根据上面训练好的分类器对测试集的每个样本进行预测
y_test = classifier.predict(x_test) #将测试集的预测结果保存至本地
df_test['class'] = y_test.tolist()
df_test['class'] = df_test['class'] + 1
df_result = df_test.loc[:, ['id', 'class']]
df_result.to_csv('./results/beginner.csv', index=False) print("完成...............")
3.问题修复
由于提供的数据集较大,一般运行时间再10到15分钟之间,基础电脑配置在4核8G的样子(越消耗内存在6.2G),因此,一般可能会遇到内存溢出的错误。

可限制每次读取的数据量,具体解决办法如下:
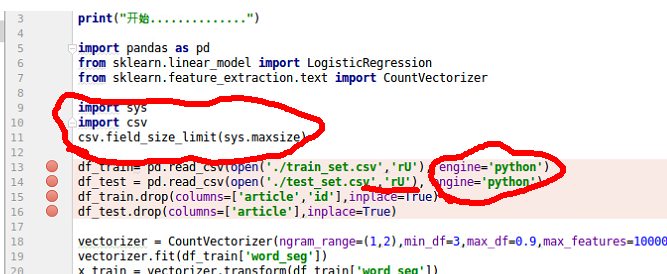
当然,你也可以换一个配置更高的电脑。
“达观杯”文本分类--baseline的更多相关文章
- Bert文本分类实践(一):实现一个简单的分类模型
写在前面 文本分类是nlp中一个非常重要的任务,也是非常适合入坑nlp的第一个完整项目.虽然文本分类看似简单,但里面的门道好多好多,作者水平有限,只能将平时用到的方法和trick在此做个记录和分享,希 ...
- Bert文本分类实践(二):魔改Bert,融合TextCNN的新思路
写在前面 文本分类是nlp中一个非常重要的任务,也是非常适合入坑nlp的第一个完整项目.虽然文本分类看似简单,但里面的门道好多好多,博主水平有限,只能将平时用到的方法和trick在此做个记录和分享 ...
- python - 实现文本分类[简单使用第三方库完成]
第三方库 pandas sklearn 数据集 来自于达观杯 训练:train.txt 测试:test.txt 概述 TF-IDF 模型提取特征值建立逻辑回归模型 代码 # _*_ coding:ut ...
- 在 TensorFlow 中实现文本分类的卷积神经网络
在TensorFlow中实现文本分类的卷积神经网络 Github提供了完整的代码: https://github.com/dennybritz/cnn-text-classification-tf 在 ...
- fastText文本分类算法
1.概述 FastText 文本分类算法是有Facebook AI Research 提出的一种简单的模型.实验表明一般情况下,FastText 算法能获得和深度模型相同的精度,但是计算时间却要远远小 ...
- FastText 文本分类使用心得
http://blog.csdn.net/thriving_fcl/article/details/53239856 最近在一个项目里使用了fasttext[1], 这是facebook今年开源的一个 ...
- NLP(七) 信息抽取和文本分类
命名实体 专有名词:人名 地名 产品名 例句 命名实体 Hampi is on the South Bank of Tungabhabra river Hampi,Tungabhabra River ...
- NLP(十六)轻松上手文本分类
背景介绍 文本分类是NLP中的常见的重要任务之一,它的主要功能就是将输入的文本以及文本的类别训练出一个模型,使之具有一定的泛化能力,能够对新文本进行较好地预测.它的应用很广泛,在很多领域发挥着重要 ...
- 基于Text-CNN模型的中文文本分类实战 流川枫 发表于AI星球订阅
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
随机推荐
- unity www下载导致内存占用增加问题
服务端或者数据库更改导致客户端更改,最合理的处理方法是客户端时刻检测版本号(可以通过实时检测版本号),如果实时刷新数据库的数据开销比较大,尤其是有图片元素时. 采用unity www类下载时,虽然结束 ...
- swiper轮播
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- HyperLPR车牌识别
简介 本文基于HyperLPR进行修改,完整代码参考https://github.com/Liuyubao/PlateRecognition. HyperLPR是一个使用深度学习针对对中文车牌识别的实 ...
- 洛谷P2858 【[USACO06FEB]奶牛零食Treats for the Cows】
我们可以记录头和尾再加一个卖了的零食数目,如果头超过尾就return 0. 如果遇到需要重复使用的数,(也就是不为零的d数组)就直接return d[tuo][wei]. 如果没有,就取卖头一个与最后 ...
- MIT线性代数:7.主变量,特解,求解AX=0
- 学习笔记33_EF跨数据库
在App.Config中,可以: (1)自定义类 public xxxxDbContext() { public XXXXDbContext():base("name=xxxxContain ...
- NOIP模拟测试40
考试时打了三个正解(或者叫能A的算法?),但是最终一个都没有A. 比较失败的一次考试. T1.队长快跑 先打了70分的dp,然后发现这个式子可以优化,拿线段树搞一下就好了,发现考试已经过去1h了,决定 ...
- Jenkins发送测试报告
邮件全局配置 邮件插件:Email Extension Plugin 功能:发送邮件 邮件全局配置:jenkins--系统管理--系统配置:截图: 配置说明: 系统管理员邮件地址:必须配置,配置后邮件 ...
- Hybrid App: 了解JavaScript如何与Native实现混合开发
一.简介 Hybrid Development混合开发是目前移动端开发异常火热的新兴技术,它能够实现跨平台开发,极大地节约了人力和资源成本.跨平台开发催生了很多新的开源框架,就目前而言,在混合开发中比 ...
- 使用springcloud开发测试问题总结
使用springcloud开发测试 如下描述的问题,没有指明是linux部署的,都是在windows开发环境上部署验证发现的. Issue1配置客户端不使用配置中心 问题描述: 配置客户端使用配置中心 ...