requests+lxml+xpath爬取豆瓣电影
(1)lxml解析html
from lxml import etree
#创建一个html对象
html=stree.HTML(text)
result=etree.tostring(html,encoding="utf-8").decode("utf-8")
requests+lxml+xpath实现豆瓣电影爬虫
import requests
from lxml import etree
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
}
原始界面:
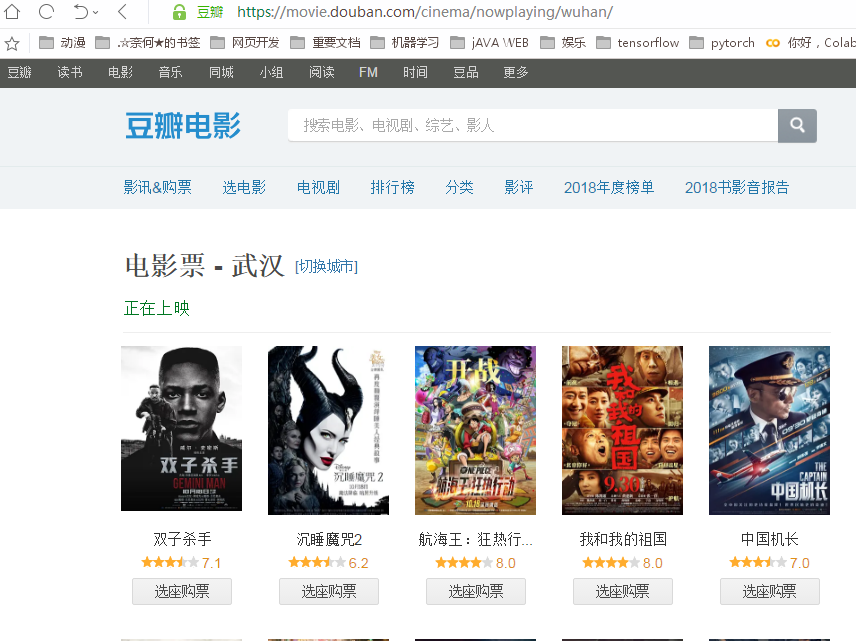
url="https://movie.douban.com/cinema/nowplaying/wuhan/"
response=request.get(url,headers=headers)
text=response.text
html=etree.HTML(text)
我们会得到一个html对象

转换成字符串看下结果
result=etree.tostring(html,encoding="utf-8").decode("utf-8")
部分结果如下:

然后进行xpath解析:
我们对准其中一部电影点击鼠标右键--检查,得到如下视图:

我们发现,上映电影的信息都在带有属性lists的ul中,我们可以对此进行xpath解析,(我们解析的是html对象,而不是转成字符串的结果):
uls=html.xpath("//ul[@class='lists']")[0]
我们在转成字符串查看一下结果:
res=etree.tostring(uls,encoding="utf-8").decode("utf-8")
print(res)

正是我们想要的,我们接着解析里面的内容:
首先获取所有的li:
#这句的意思是获取当前uls下的所有直接li
lis=uls.xpath("./li)
结果是一系列的li对象:

我们再分别进行解析:
movies=[]
for li in lis:
name=li.xpath("@data-title")[0]
score=li.xpath("@data-score")[0]
country=li.xpath("@data-region")[0]
director=li.xpath("@data-director")[0]
actors=li.xpath("@data-actors")[0]
category=li.xpath("@data-category")[0]
movie={
"name":name,
"score":score,
"country":country,
"director":director,
"actors":actors,
"category":category
}
movies.append(movie)
print(movies)
部分结果如下:

在json中格式化结果如下:

至此,一个初步的爬虫就完成了。
requests+lxml+xpath爬取豆瓣电影的更多相关文章
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- requests+lxml+xpath爬取电影天堂
1.导入相应的包 import requests from lxml import etree 2.原始ur url="https://www.dytt8.net/html/gndy/dyz ...
- requests结合xpath爬取豆瓣最新上映电影
# -*- coding: utf-8 -*- """ 豆瓣最新上映电影爬取 # ul = etree.tostring(ul, encoding="utf-8 ...
- python3+requests+BeautifulSoup+mysql爬取豆瓣电影top250
基础页面:https://movie.douban.com/top250 代码: from time import sleep from requests import get from bs4 im ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
随机推荐
- Angular 内嵌视图、宿主视图
解析视图: 内嵌视图 - 连接到模板的嵌入视图,在组件模板元素中添加模板(DOM元素.DOM元素组) 宿主视图 - 连接到组件的嵌入视图,在组件元素中添加别的组件 使用类说明: ElementRef ...
- 概率与期望详解!一次精通oi中的概率期望
目录 基础概念 最大值不超过Y的期望 概率为P时期望成功次数 基础问题 拿球 随机游走 经典问题 期望线性性练习题 例题选讲 noip2016换教室 区间交 0-1边树求直径期望 球染色 区间翻转 二 ...
- jQuery常用方法(三)-jQuery Ajax
JQuery Ajax 方法说明: load( url, [data], [callback] ) 装入一个远程HTML内容到一个DOM结点. $("#feeds").load(& ...
- jQuery常用方法(一)-基础
$("p").addClass(css中定义的样式类型); 给某个元素添加样式 $("img").attr({src:"test.jpg", ...
- OKR群:为什么说每个程序员都应该有自己的个人OKR
个人OKR OKR,即Object and Key Result,是IT大厂最近争相推广的目标管理工具,例如腾讯.百度和头条(字节跳动). 其实,OKR并不是仅仅只适用于公司和部门内部,我们个人也可以 ...
- linux下安装配置go语言环境
1,golang中国下载go源码 http://www.golangtc.com/download 请对应系统版本号,linux-amd64.tar.gz为64位系统(推荐) ,linux-386 ...
- 新手安装vue-cli脚手架
首先这片文章借鉴了很多博主的,再此对他们表示感谢. 什么是vue? Vue.js是一套构建用户界面的渐进式框架.Vue 只关注视图层,采用自底向上增量开发的设计. Vue 的目标是通过尽可能简单的 A ...
- 软件开发工具(第7章:Eclipse入门)
一.Eclipse简介 Eclipse [iˈklips],是一个开放源代 码的.基于Java的可扩展集成应 用程序开发环境. Eclipse最初主要用来进行Java语 言开发,但并非只有这个用途. ...
- Mint(Linux)系统设置优化及其常用软件安装笔记
LInux /home下中文目录如何修改成英文? 打开终端,在终端中输入命令: export LANG=en_US xdg-user-dirs-gtk-update 跳出对话框询问是否将目录转化为英文 ...
- 面试常考各类排序算法总结.(c#)
前言 面试以及考试过程中必会出现一道排序算法面试题,为了加深对排序算法的理解,在此我对各种排序算法做个总结归纳. 1.冒泡排序算法(BubbleSort) 1.1 算法描述 (1)比较相邻的元素.如果 ...