Java - JDBC批量插入原理
一、说明
在JDBC中,executeBatch这个方法可以将多条dml语句批量执行,效率比单条执行executeUpdate高很多,这是什么原理呢?在mysql和oracle中又是如何实现批量执行的呢?本文将给大家介绍这背后的原理。
二、实验介绍
本实验将通过以下三步进行
a. 记录jdbc在mysql中批量执行和单条执行的耗时
b. 记录jdbc在oracle中批量执行和单条执行的耗时
c. 记录oracle plsql批量执行和单条执行的耗时
相关java和数据库版本如下:Java17,Mysql8,Oracle11G
三、正式实验
在mysql和oracle中分别创建一张表
create table t ( -- mysql中创建表的语句
id int,
name1 varchar(100),
name2 varchar(100),
name3 varchar(100),
name4 varchar(100)
);
create table t ( -- oracle中创建表的语句
id number,
name1 varchar2(100),
name2 varchar2(100),
name3 varchar2(100),
name4 varchar2(100)
);
在实验前需要打开数据库的审计
mysql开启审计:
set global general_log = 1;
oracle开启审计:
alter system set audit_trail=db, extended;
audit insert table by scott; -- 实验采用scott用户批量执行insert的方式
java代码如下:
import java.sql.*;
public class JdbcBatchTest {
/**
* @param dbType 数据库类型,oracle或mysql
* @param totalCnt 插入的总行数
* @param batchCnt 每批次插入的行数,0表示单条插入
*/
public static void exec(String dbType, int totalCnt, int batchCnt) throws SQLException, ClassNotFoundException {
String user = "scott";
String password = "xxxx";
String driver;
String url;
if (dbType.equals("mysql")) {
driver = "com.mysql.cj.jdbc.Driver";
url = "jdbc:mysql://ip/hello?useServerPrepStmts=true&rewriteBatchedStatements=true";
} else {
driver = "oracle.jdbc.OracleDriver";
url = "jdbc:oracle:thin:@ip:orcl";
}
long l1 = System.currentTimeMillis();
Class.forName(driver);
Connection connection = DriverManager.getConnection(url, user, password);
connection.setAutoCommit(false);
String sql = "insert into t values (?, ?, ?, ?, ?)";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
for (int i = 1; i <= totalCnt; i++) {
preparedStatement.setInt(1, i);
preparedStatement.setString(2, "red" + i);
preparedStatement.setString(3, "yel" + i);
preparedStatement.setString(4, "bal" + i);
preparedStatement.setString(5, "pin" + i);
if (batchCnt > 0) {
// 批量执行
preparedStatement.addBatch();
if (i % batchCnt == 0) {
preparedStatement.executeBatch();
} else if (i == totalCnt) {
preparedStatement.executeBatch();
}
} else {
// 单条执行
preparedStatement.executeUpdate();
}
}
connection.commit();
connection.close();
long l2 = System.currentTimeMillis();
System.out.println("总条数:" + totalCnt + (batchCnt>0? (",每批插入:"+batchCnt) : ",单条插入") + ",一共耗时:"+ (l2-l1) + " 毫秒");
}
public static void main(String[] args) throws SQLException, ClassNotFoundException {
exec("mysql", 10000, 50);
}
}
代码中几个注意的点,
- mysql的url需要加入useServerPrepStmts=true&rewriteBatchedStatements=true参数。
- batchCnt表示每次批量执行的sql条数,0表示单条执行。
首先测试mysql
exec("mysql", 10000, batchCnt);
代入不同的batchCnt值看执行时长
batchCnt=50 总条数:10000,每批插入:50,一共耗时:4369 毫秒
batchCnt=100 总条数:10000,每批插入:100,一共耗时:2598 毫秒
batchCnt=200 总条数:10000,每批插入:200,一共耗时:2211 毫秒
batchCnt=1000 总条数:10000,每批插入:1000,一共耗时:2099 毫秒
batchCnt=10000 总条数:10000,每批插入:10000,一共耗时:2418 毫秒
batchCnt=0 总条数:10000,单条插入,一共耗时:59620 毫秒
查看general log
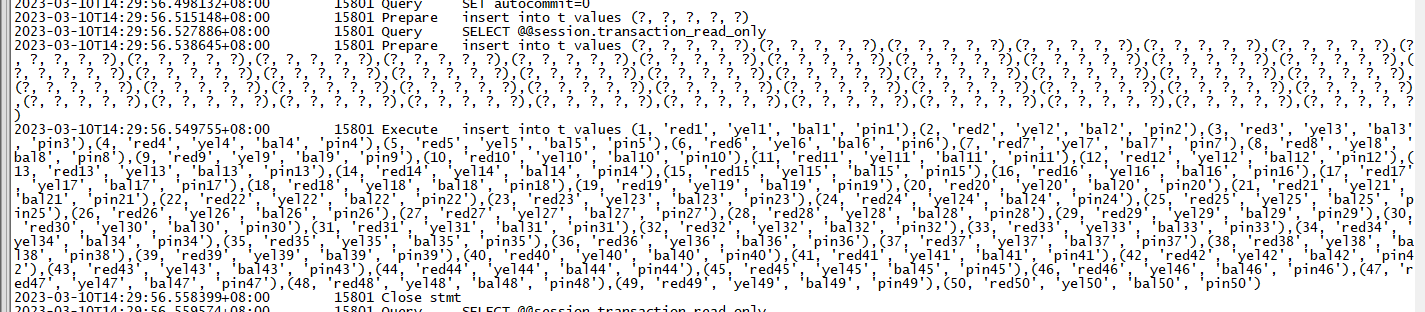
batchCnt=50
batchCnt=0
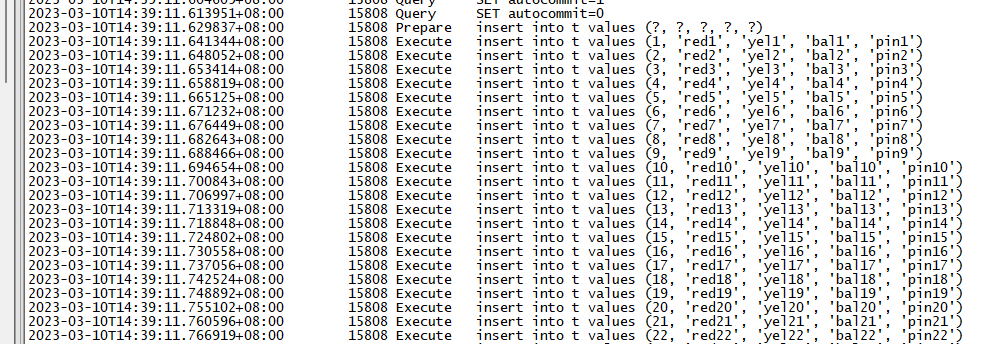
可以得出几个结论:
- 批量执行的效率相比单条执行大大提升。
- mysql的批量执行其实是改写了sql,将多条insert合并成了insert xx values(),()...的方式去执行。
- 将batchCnt由50改到100的时候,时间基本上缩短了一半,但是再扩大这个值的时候,时间缩短并不明显,执行的时间甚至还会升高。
分析原因:
当执行一条sql语句的时候,客户端发送sql文本到数据库服务器,数据库执行sql再将结果返回给客户端。总耗时 = 数据库执行时间 + 网络传输时间。使用批量执行减少往返的次数,即降低了网络传输时间,总时间因此降低。但是当batchCnt变大,网络传输时间并不是最主要耗时的时候,总时间降低就不会那么明显。特别是当batchCnt=10000,即一次性把1万条语句全部执行完,时间反而变多了,这可能是由于程序和数据库在准备这些入参时需要申请更大的内存,所以耗时更多(我猜的)。
再来说一句,batchCnt这个值是不是能无限大呢,假设我需要插入的是1亿条,那么我能一次性批量插入1亿条吗?当然不行,我们不考虑undo的空间问题,首先你电脑就没有这么大的内存一次性把这1亿条sql的入参全部保存下来,其次mysql还有个参数max_allowed_packet限制单条语句的长度,最大为1G字节。当语句过长的时候就会报"Packet for query is too large (1,773,901 > 1,599,488). You can change this value on the server by setting the 'max_allowed_packet' variable"。
接下来测试oracle
exec("oracle", 10000, batchCnt);
代入不同的batchCnt值看执行时长
batchCnt=50 总条数:10000,每批插入:50,一共耗时:2055 毫秒
batchCnt=100 总条数:10000,每批插入:100,一共耗时:1324 毫秒
batchCnt=200 总条数:10000,每批插入:200,一共耗时:856 毫秒
batchCnt=1000 总条数:10000,每批插入:1000,一共耗时:785 毫秒
batchCnt=10000 总条数:10000,每批插入:10000,一共耗时:804 毫秒
batchCnt=0 总条数:10000,单条插入,一共耗时:60830 毫秒
可以看到oracle中执行的效果跟mysql中基本一致,批量执行的效率相比单条执行都大大提升。问题就来了,oracle中并没有这种insert xx values(),()..语法呀,那它是怎么做到批量执行的呢?
查看当执行batchCnt=50的审计视图dba_audit_trail
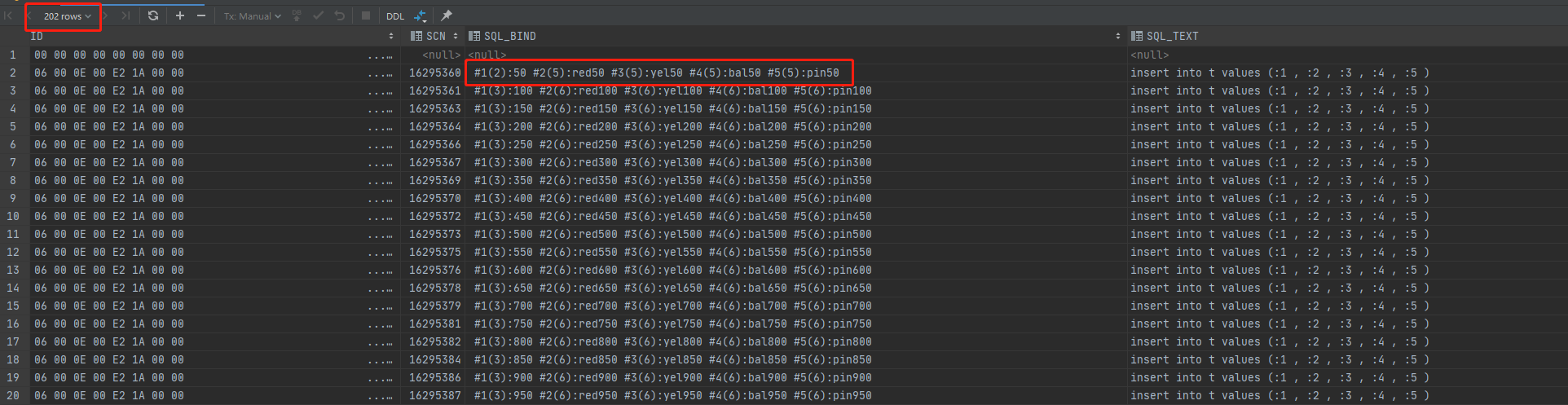
从审计的结果中可以看到,batchCnt=50的时候,审计记录只有200条(扣除登入和登出),也就是sql只执行了200次。sql_text没有发生改写,仍然是"insert into t values (:1 , :2 , :3 , :4 , :5 )",而且sql_bind只记录了批量执行的最后一个参数,即50的倍数。从awr报告中也能看出的确是只执行了200次(限于篇幅,awr截图省略)。那么oracle是怎么做到只执行200次但插入1万条记录的呢?我们来看看oracle中使用存储过程的批量插入。
三、存储过程
准备数据:
首先将t表清空 truncate table t;
用java往t表灌10万数据 exec("oracle", 100000, 1000);
创建t1表 create table t1 as select * from t where 1 = 0;
以下两个procudure的目的相同,都是将t表的数据灌到t1表中。nobatch是单次执行,usebatch是批量执行。
create or replace procedure nobatch is
begin
for x in (select * from t)
loop
insert into t1 (id, name1, name2, name3, name4)
values (x.id, x.name1, x.name2, x.name3, x.name4);
end loop;
commit;
end nobatch;
/
create or replace procedure usebatch (p_array_size in pls_integer)
is
type array is table of t%rowtype;
l_data array;
cursor c is select * from t;
begin
open c;
loop
fetch c bulk collect into l_data limit p_array_size;
forall i in 1..l_data.count insert into t1 values l_data(i);
exit when c%notfound;
end loop;
commit;
close c;
end usebatch;
/
执行上述存储过程
SQL> exec nobatch;
Elapsed: 00:00:32.92
SQL> exec usebatch(50);
Elapsed: 00:00:00.77
SQL> exec usebatch(100);
Elapsed: 00:00:00.47
SQL> exec usebatch(1000);
Elapsed: 00:00:00.19
SQL> exec usebatch(100000);
Elapsed: 00:00:00.26
存储过程批量执行效率也远远高于单条执行。查看usebatch(50)执行时的审计日志,sql_bind也只记录了批量执行的最后一个参数,即50的倍数。跟前面jdbc使用executeBatch批量执行时的记录内容一样。由此可知jdbc的executeBatch跟存储过程的批量执行应该是采用的同样的方法。
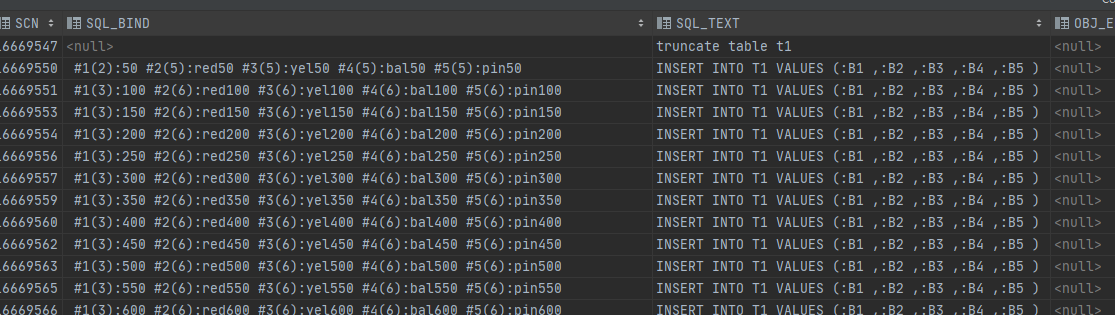
存储过程的这个关键点就是forall。查阅相关文档。
The FORALL statement runs one DML statement multiple times, with different values in the VALUES and WHERE clauses.
The different values come from existing, populated collections or host arrays. The FORALL statement is usually much faster than an equivalent FOR LOOP statement.
The FORALL syntax allows us to bind the contents of a collection to a single DML statement, allowing the DML to be run for each row in the collection without requiring a context switch each time.
翻译过来就是forall很快,原因就是不需要每次执行的时候等待参数。
四、总结
- mysql的批量执行就是改写sql。
- oracle的批量执行就是用的forall。
- 选择一个合适批量值。
参考:
https://docs.oracle.com/en/database/oracle/oracle-database/19/lnpls/FORALL-statement.html#GUID-C45B8241-F9DF-4C93-8577-C840A25963DB
https://oracle-base.com/articles/9i/bulk-binds-and-record-processing-9i
https://www.akadia.com/services/ora_bulk_insert.html
Java - JDBC批量插入原理的更多相关文章
- Mybatis与JDBC批量插入MySQL数据库性能测试及解决方案
转自http://www.cnblogs.com/fnz0/p/5713102.html 不知道自己什么时候才有这种钻研精神- -. 1 背景 系统中需要批量生成单据数据到数据库表,所以采用 ...
- 三种JDBC批量插入编程方法的比较
JDBC批量插入主要用于数据导入和日志记录因为日志一般都是先写在文件下的等. 我用Mysql 5.1.5的JDBC driver 分别对三种比较常用的方法做了测试 方法一,使用PreparedStat ...
- jdbc批量插入
分享牛,分享牛原创.有这样一个需求,文本文件中的数据批量的插入mysql,怎么用jdbc方式批量插入呢? jdbc默认提供了批量插入的方法,可能用一次就忘记了,这里做笔记记录一下jdbc批量插入吧. ...
- JDBC批量插入数据优化,使用addBatch和executeBatch
JDBC批量插入数据优化,使用addBatch和executeBatch SQL的批量插入的问题,如果来个for循环,执行上万次,肯定会很慢,那么,如何去优化呢? 解决方案:用 preparedSta ...
- Java JDBC批处理插入数据操作
在此笔记里,我们将看到我们如何可以使用像Statement和PreparedStatement JDBC API来批量在任何数据库中插入数据.此外,我们将努力探索一些场景,如在内存不足时正常运行,以及 ...
- Java JDBC批处理插入数据操作(转)
在此笔记里,我们将看到我们如何可以使用像Statement和PreparedStatement JDBC API来批量在任何数据库中插入数据.此外,我们将努力探索一些场景,如在内存不足时正常运行,以及 ...
- JDBC批量插入数据效率分析
对于需要批量插入数据库操作JDBC有多重方式,本利从三个角度对Statement和PreparedStatement两种执行方式进行分析,总结较优的方案. 当前实现由如下条件: 执行数据库:Mysql ...
- JDBC批量插入优化addbatch
// 获取要设置的Arp基准的List后,插入Arp基准表中 public boolean insertArpStandardList(List<ArpTable> list) { Con ...
- JDBC批量插入blob数据
图片从接口读取后是base64的字符串,所以转成byte数组进行保存. 我们一般保存数据的话,都是基本数据,对于这些图片数据大部分会将图片保存成Blob,Clob等. Blob存储的是二进制对象数据( ...
- MySQL:JDBC批量插入数据的效率
平时使用mysql插入.查询数据都没有注意过效率,今天在for循环中使用JDBC插入1000条数据居然等待了一会儿 就来探索一下JDBC的批量插入语句对效率的提高 首先进行建表 create tabl ...
随机推荐
- mybati之sql集合
mybatis 详解(五)------动态SQL - YSOcean - 博客园 (cnblogs.com) mybatis参数注入: 根据参数名称 使用#{} 注入参数 <insert id= ...
- 【SSO单点系列】(2):CAS4.0 之 跨域 Ajax 登录实践
CAS4.0 之 跨域 Ajax 登录实践 一.问题描述 CAS实现单点 实现一处登录 可访问多个应用 . 但是原登录是CAS默认登录页面和登出页面是无法重定向到自定义页面的 此处使用Ajax+I ...
- 最简单明了的yield from解释
def one(): print('one start') res = yield from two() print('function get res: ', res) return 'one' + ...
- Python编码转换图
- 运行代码后出现Process finished with exit code 0
pycharm_运行不出结果,也不报错_Process finished with exit code 0用pycharm运行程序的时候,运行不出结果 ,也不报错,且正常退出解决1:将 run → e ...
- Dom,Bom的用法
DOM DOM 全称document object model 文档对象模型 操作HTML HTML文档有HTML+css组成 DOM 利用js操作HTML+css的 操作元素节点 element E ...
- git log 查看分支图
操作: 在git config文件里面设置别名. git config --global alias.lg "log --graph --all --pretty=format:'%Cred ...
- CORS预检
CORS是一种常见的跨域机制,一般由服务端提供一个Access-Control-Allow-Origin头来解决问题,但是这仅对一些"简单请求"有效.那么何谓"简单请求& ...
- SpringBoot(概述、起步依赖原理分析、SpringBoot配置(配置文件分类、YAML))
SpringBoot概述 Spring Boot 是由 Pivotal 团队提供用来简化 Spring 的搭建和开发过程的全新框架.随着近些年来微服务技术的流行,Spring Boot 也成了时下炙手 ...
- 解决CentOS 7.x虚拟机无法上网的问题
参考地址:https://blog.csdn.net/weixin_43317914/article/details/124770393 1.关闭虚拟机 2.打开cmd,查看本机dns 3.打开虚拟机 ...