sparkStreaming 读kafka的数据
目标:sparkStreaming每2s中读取一次kafka中的数据,进行单词计数。
topic:topic1
broker list:192.168.1.126:9092,192.168.1.127:9092,192.168.1.128:9092
1、首先往一个topic中实时生产数据。
代码如下: 代码功能:每秒向topic1发送一条消息,一条消息里包含4个单词,单词之间用空格隔开。
package kafkaProducer
import java.util.HashMap
import org.apache.kafka.clients.producer._
object KafkaProducer {
def main(args: Array[String]) {
val topic="topic1"
val brokers="192.168.1.126:9092,192.168.1.127:9092,192.168.1.128:9092"
val messagesPerSec=1 //每秒发送几条信息
val wordsPerMessage =4 //一条信息包括多少个单词
// Zookeeper connection properties
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](props)
// Send some messages
while(true) {
(1 to messagesPerSec.toInt).foreach { messageNum =>
val str = (1 to wordsPerMessage.toInt).map(x => scala.util.Random.nextInt(10).toString)
.mkString(" ")
val message = new ProducerRecord[String, String](topic, null, str)
producer.send(message)
println(message)
}
Thread.sleep(1000)
}
}
}
打包运行命令:hadoop jar jar包 (注意jar包是可运行的jar包)
消费者消费命令: ./kafka-console-consumer.sh --zookeeper zk01:2181,zk02:2181 --topic topic1 --from-beginning
可以正常消费。
2、编写SparkStreaming代码读kafka中的数据,每2s读一次
代码如下:
package kafkaSparkStream import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.kafka.KafkaUtils
import kafka.serializer.StringDecoder
/**
* sparkStreaming读取kafka中topic的数据
*/
object KafkaToSpark {
def main(args: Array[String]) {
if (args.length<2) {
System.err.println("Usage: <brokers> <topics>");
System.exit(1)
}
val Array(brokers,topics)=args
//2s从kafka中读取一次
val conf=new SparkConf().setAppName("KafkaToSpark");
val scc=new StreamingContext(conf,Seconds(2))
// Create direct kafka stream with brokers and topics
val topicSet=topics.split(",").toSet
val kafkaParams=Map[String,String]("metadata.broker.list"->brokers)
//获取信息
val messages=KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
scc,kafkaParams,topicSet)
// Get the lines, split them into words, count the words and print
val lines= messages.map(_._2)
val words=lines.flatMap(_.split(" "))
val wordCouts=words.map(x =>(x,1L)).reduceByKey(_+_)
wordCouts.print
//开启计算
scc.start()
scc.awaitTermination()
} }
打包运行命令:./spark-submit --class kafkaSparkStream.KafkaToSpark --master yarn-client /home/hadoop/sparkJar/kafkaToSpark.jar 192.168.1.126:9092,192.168.1.127:9092,192.168.1.128:9092 topic1
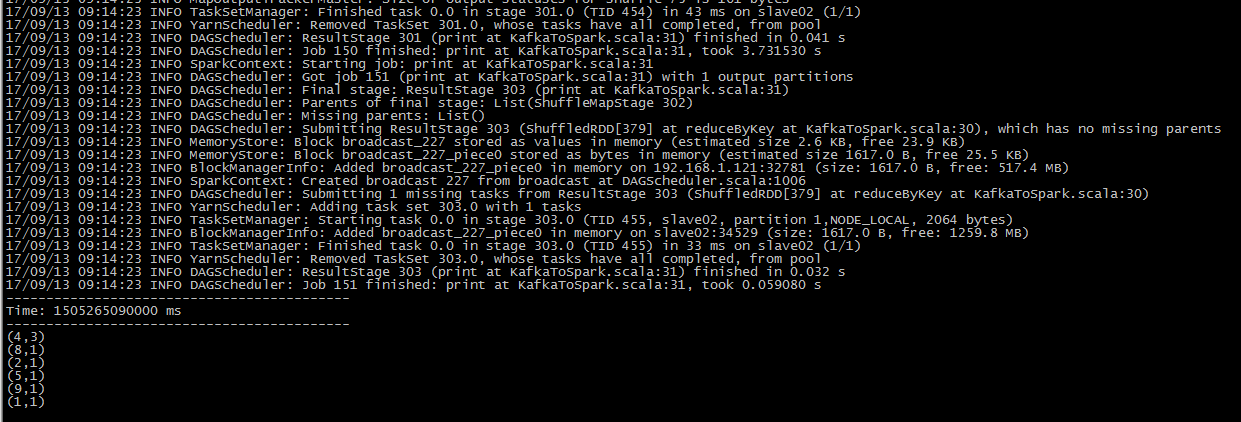
运行成功!
sparkStreaming 读kafka的数据的更多相关文章
- SparkStreaming消费kafka中数据的方式
有两种:Direct直连方式.Receiver方式 1.Receiver方式: 使用kafka高层次的consumer API来实现,receiver从kafka中获取的数据都保存在spark exc ...
- spark-streaming读kafka数据到hive遇到的问题
在项目中使用spark-stream读取kafka数据源的数据,然后转成dataframe,再后通过sql方式来进行处理,然后放到hive表中, 遇到问题如下,hive-metastor在没有做高可用 ...
- Spark Streaming使用Kafka保证数据零丢失
来自: https://community.qingcloud.com/topic/344/spark-streaming使用kafka保证数据零丢失 spark streaming从1.2开始提供了 ...
- 大数据学习day32-----spark12-----1. sparkstreaming(1.1简介,1.2 sparkstreaming入门程序(统计单词个数,updateStageByKey的用法,1.3 SparkStreaming整合Kafka,1.4 SparkStreaming获取KafkaRDD的偏移量,并将偏移量写入kafka中)
1. Spark Streaming 1.1 简介(来源:spark官网介绍) Spark Streaming是Spark Core API的扩展,其是支持可伸缩.高吞吐量.容错的实时数据流处理.Sp ...
- spark-streaming集成Kafka处理实时数据
在这篇文章里,我们模拟了一个场景,实时分析订单数据,统计实时收益. 场景模拟 我试图覆盖工程上最为常用的一个场景: 1)首先,向Kafka里实时的写入订单数据,JSON格式,包含订单ID-订单类型-订 ...
- SparkStreaming获取kafka数据的两种方式:Receiver与Direct
简介: Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以简单理解成: Receiver方式是通过zookeeper来连接kafka队列, Dire ...
- SparkStreaming与Kafka,SparkStreaming接收Kafka数据的两种方式
SparkStreaming接收Kafka数据的两种方式 SparkStreaming接收数据原理 一.SparkStreaming + Kafka Receiver模式 二.SparkStreami ...
- 图解SparkStreaming与Kafka的整合,这些细节大家要注意!
前言 老刘是一名即将找工作的研二学生,写博客一方面是复习总结大数据开发的知识点,一方面是希望帮助更多自学的小伙伴.由于老刘是自学大数据开发,肯定会存在一些不足,还希望大家能够批评指正,让我们一起进步! ...
- 读Kafka Consumer源码
最近一直在关注阿里的一个开源项目:OpenMessaging OpenMessaging, which includes the establishment of industry guideline ...
随机推荐
- 1.IO的演进
1.Java IO 演进之路 本文围绕着一下几个问题 1.Java 中 BIO.NIO.AIO 之间的区别及应用场景. 2.阻塞(Block)与非阻塞(Non-Block)区别. 3.同步(Syn ...
- Java基础IO类之打印流
package IODemo; import java.io.*; /* 打印流 : 很方便的进行输出 字节打印流 增强输出功能 字符打印流 */ public class PrintStreamDe ...
- Liar CodeForces - 822E (dp,后缀数组)
大意: 给定串$s,t$, 给定整数$x$, 求判断$t$是否能划分为至多$x$段, 使这些段在$s$中按顺序,不交叉的出现. 设$dp_{i,j}$表示$s$匹配到$i$位, 划分了$j$段, 匹配 ...
- 天梯赛 L2-024. 部落
题解:并查集,这里要用路径压缩来优化 代码:// 这里范围理错了, 浪费20分钟debug #include <set> #include <iostream> #includ ...
- SSH安全加固
SSH安全加固 配置文件: /etc/ssh/sshd_config # This file is automatically generated at startup KexAlgorithms c ...
- 原生js实现ajax封装
一.什么是ajax? 定义:Ajax(Asynchronous Java and XML的缩写)是一种异步请求数据的web开发技术,在不需要重新刷新页面的情况下,Ajax 通过异步请求加载后台数据,并 ...
- var img = new Image()
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Java 之 字符输入流[Reader]
一.字符输入流 java.io.Reader 抽象类是表示用于读取字符流的所有类的超类,可以读取字符信息到内存中. 它定义了字符输入流的基本共性功能方法. public void close() :关 ...
- 论文阅读:Deformable ConvNets v2
论文地址:http://arxiv.org/abs/1811.11168 作者:pprp 时间:2019年5月11日 0. 摘要 DCNv1引入了可变形卷积,能更好的适应目标的几何变换.但是v1可视化 ...
- 自动构建的deploy.sh
#!/usr/bin/env sh # 当发生错误时中止脚本 set -e # 构建 npm run build # cd 到构建输出的目录下 cd dist # 部署到自定义域域名 # echo ' ...