图解SparkStreaming与Kafka的整合,这些细节大家要注意!
前言

老刘是一名即将找工作的研二学生,写博客一方面是复习总结大数据开发的知识点,一方面是希望帮助更多自学的小伙伴。由于老刘是自学大数据开发,肯定会存在一些不足,还希望大家能够批评指正,让我们一起进步!
今天讲述的是SparkStreaming与Kafka的整合,这篇文章非常适合刚入门的小伙伴,也欢迎大家前来发表意见,老刘这次会用图片的形式讲述别人技术博客没有的一些细节,这些细节对刚入门的小伙伴是非常有用的!!!
正文
为什么有SparkStreaming与Kafka的整合?
首先我们要知道为什么会有SparkStreaming与Kafka的整合,任何事情的出现都不是无缘无故的!
我们要知道Spark作为实时计算框架,它仅仅涉及到计算,并没有涉及到数据的存储,所以我们后期需要使用spark对接外部的数据源。SparkStreaming作为Spark的一个子模块,它有4个类型的数据源:
- socket数据源(测试的时候使用)
- HDFS数据源(会用到,但是用得不多)
- 自定义数据源(不重要,没怎么见过别人会自定义数据源)
- 扩展的数据源(比如kafka数据源,它非常重要,面试中也会问到)
下面老刘图解SparkStreaming与Kafka的整合,但只讲原理,代码就不贴了,网上太多了,老刘写一些自己理解的东西!

SparkStreaming整合Kafka-0.8
SparkStreaming与Kafka的整合要看Kafka的版本,首先要讲的是SparkStreaming整合Kafka-0.8。
在SparkStreaming整合kafka-0.8中,要想保证数据不丢失,最简单的就是靠checkpoint的机制,但是checkpoint机制有一个毛病,对代码进行升级后,checkpoint机制就失效了。所以如果想实现数据不丢失,那么就需要自己管理offset。
大家对代码升级会不会感到陌生,老刘对它好好解释一下!
我们在日常开发中常常会遇到两个情况,代码一开始有问题,改一下,然后重新打包,重新提交;业务逻辑发生改变,我们也需要重新修改代码!
而我们checkpoint第一次持久化的时候会整个相关的jar给序列化成一个二进制文件,这是一个独一无二的值做目录,如果SparkStreaming想通过checkpoint恢复数据,但如果代码发生改变,哪怕一点点,就找不到之前打包的目录,就会导致数据丢失!
所以我们需要自己管理偏移量!
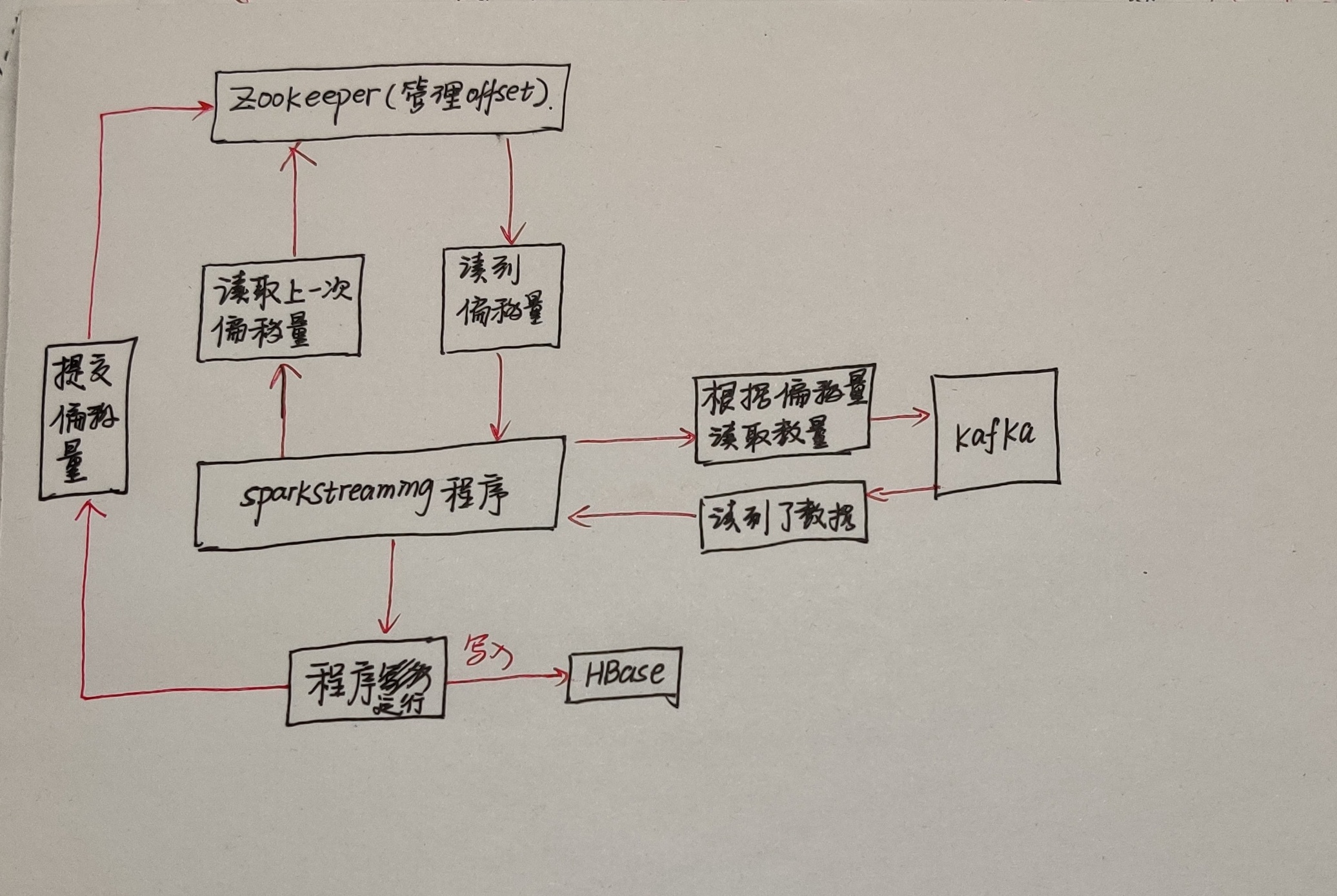
用ZooKeeper集群管理偏移量,程序启动后,就会读取上一次的偏移量,读取到数据后,SparkStreaming就会根据偏移量从kafka中读取数据,读到数据后,程序会运行。运行完后,就会提交偏移量到ZooKeeper集群,但有一个小问题,程序运行挂了,但偏移量未提交,结果已经部分到HBase,再次重新读取的时候,会有数据重复,但只影响一批次,对大数据来说,影响太小!
但是有个非常严重的问题,当有特别多消费者消费数据的时候,需要读取偏移量,但ZooKeeper作为分布式协调框架,它不适合大量的读写操作,尤其是写操作。所以高并发的请求ZooKeeper是不适合的,它只能作为轻量级的元数据存储,不能负责高并发读写作为数据存储。
根据上述内容,就引出了SparkStreaming整合Kafka-1.0。
SparkStreaming整合Kafka-1.0
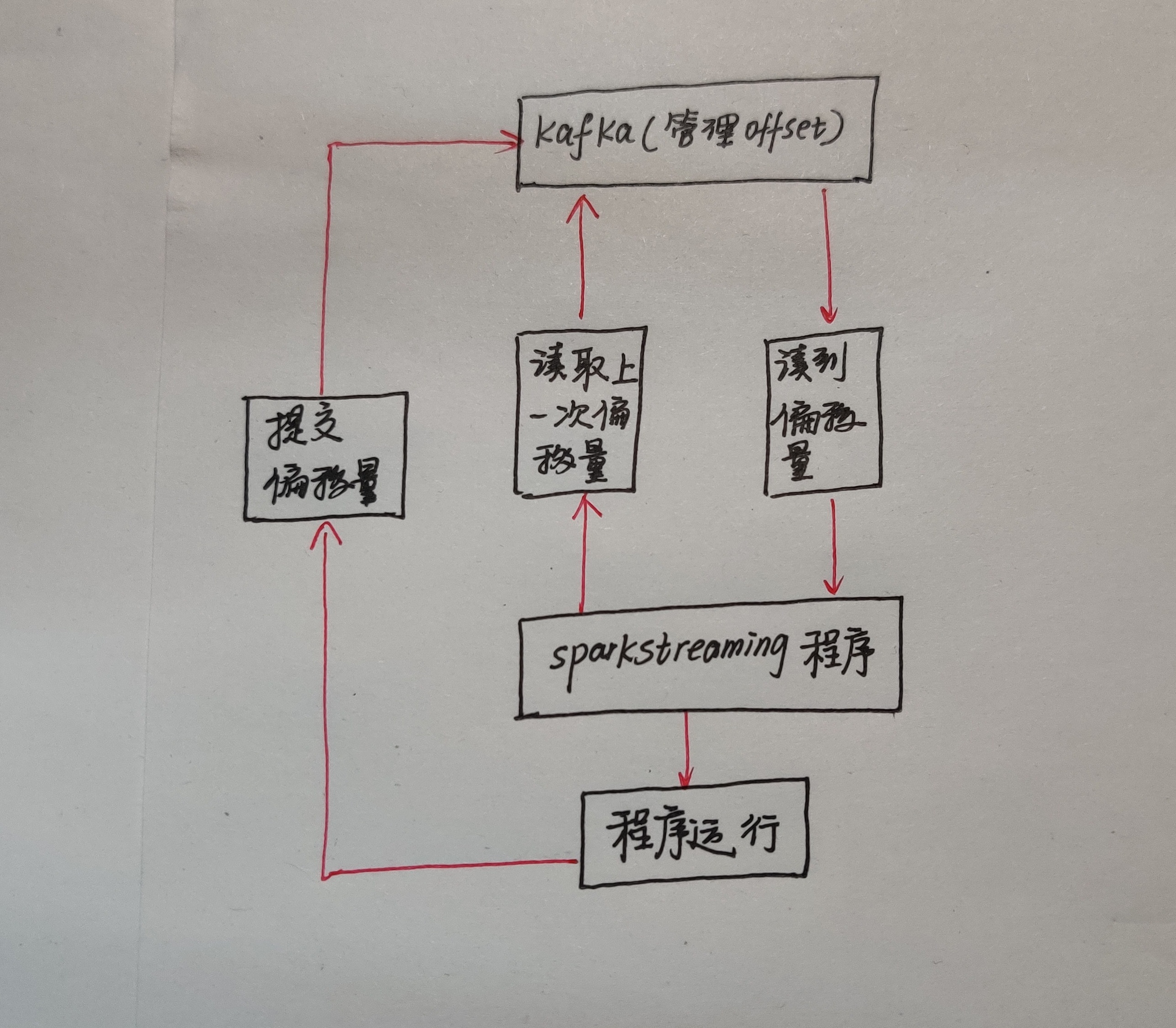
直接利用kafka保存offset偏移量,可以避免利用ZooKeeper存储offset偏移量带来的风险,这里也有一个注意的地方,kafka有一个自动提交偏移量的功能,但会导致数据丢失。
因为设置自动提交就会按照一定的频率,比如每隔2秒自动提交一次偏移量。但我截获一个数据后,还没来得及处理,刚好到达2秒就把偏移量提交了,于是就导致数据丢失,所以我们一般手动提交偏移量!
如何设计监控告警方案?
在日常开发工作中,我们需要对实时任务设计一个监控方案,因为实时任务没有监控,程序就在裸奔,任务是否有延迟等情况无法获取,这是非常可怕的情况!
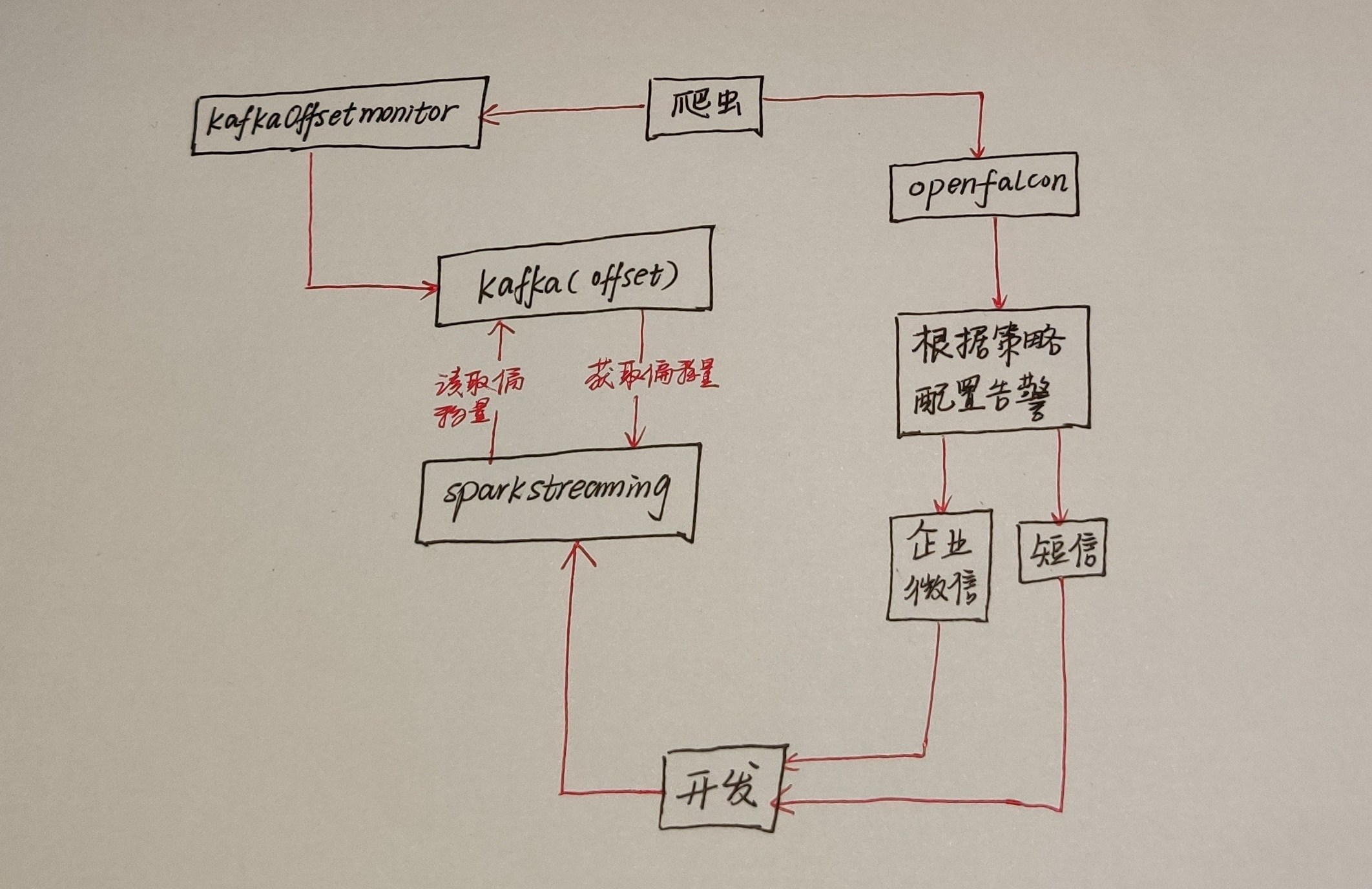
这个只是利用KafkaOffsetmonitor设计的一个方案,利用它对任务进行监控,接着利用爬虫技术获取监控的信息,再把数据导入到openfalcon里面,在openfalcon里根据策略配置告警或者自己研发告警系统,最后把信息利用企业微信或者短信发送给开发人员!
总结
好啦!本篇主要讲解了SparkStreaming和Kafka的整合过程,老刘花了很多心思讲了很多细节,对大数据感兴趣的伙伴记得给老刘点赞关注。最后,如果有疑问联系公众号:努力的老刘,进行愉快的交流!
图解SparkStreaming与Kafka的整合,这些细节大家要注意!的更多相关文章
- 【Spark】SparkStreaming和Kafka的整合
文章目录 Streaming和Kafka整合 概述 使用0.8版本下Receiver DStream接收数据进行消费 步骤 一.启动Kafka集群 二.创建maven工程,导入jar包 三.创建一个k ...
- SparkStreaming和Kafka的整合
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制.需要满足以下几个先决条件: 1.输入的数据来自可靠的数据源和可靠的接收器: 2.应用 ...
- SparkStreaming和Kafka基于Direct Approach如何管理offset实现exactly once
在之前的文章<解析SparkStreaming和Kafka集成的两种方式>中已详细介绍SparkStreaming和Kafka集成主要有Receiver based Approach和Di ...
- SparkStreaming与Kafka,SparkStreaming接收Kafka数据的两种方式
SparkStreaming接收Kafka数据的两种方式 SparkStreaming接收数据原理 一.SparkStreaming + Kafka Receiver模式 二.SparkStreami ...
- Flume+Kafka+Storm整合
Flume+Kafka+Storm整合 1. 需求: 有一个客户端Client可以产生日志信息,我们需要通过Flume获取日志信息,再把该日志信息放入到Kafka的一个Topic:flume-to-k ...
- spark-streaming集成Kafka处理实时数据
在这篇文章里,我们模拟了一个场景,实时分析订单数据,统计实时收益. 场景模拟 我试图覆盖工程上最为常用的一个场景: 1)首先,向Kafka里实时的写入订单数据,JSON格式,包含订单ID-订单类型-订 ...
- sparkStreaming 读kafka的数据
目标:sparkStreaming每2s中读取一次kafka中的数据,进行单词计数. topic:topic1 broker list:192.168.1.126:9092,192.168.1.127 ...
- SparkStreaming获取kafka数据的两种方式:Receiver与Direct
简介: Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以简单理解成: Receiver方式是通过zookeeper来连接kafka队列, Dire ...
- 第1节 kafka消息队列:10、flume与kafka的整合使用
11.flume与kafka的整合 实现flume监控某个目录下面的所有文件,然后将文件收集发送到kafka消息系统中 第一步:flume下载地址 http://archive.cloudera.co ...
随机推荐
- PyQt(Python+Qt)学习随笔:QListView的flow属性
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 QListView的flow属性用于控制视图中的数据排列方向,其类型为枚举类型QListView.F ...
- 从Excel获取整列内容进行批量扫描
实习工作原因,需要测试excel表里面ip地址是否存在漏洞,扫了一眼,呕,四五百个IP,光是挨个进行访问,都是一个浩大的工程,所以准备开始摸鱼认真工作 思路是:excel按列提取->将IP按行存 ...
- CTF流量分析题大全(掘安攻防平台)
突然想做一下流量分析题,记得掘安攻防实验室上面有很多的流量分析题目,故做之 流量分析题一般使用的都是wireshark,(流量分析工具中的王牌 夺取阿富汗 说了分析http头,所以直接过滤http协议 ...
- Hadoop 中HDFS、MapReduce体系结构
在网络环境方面,作为分布式系统,Hadoop基于TCP/IP进行节点间的通信和传输. 在数据传输方面,广泛应用HTTP实现. 在监控.通知方面,Hadoop等分布式大数据软件则广泛使用异步消息队列等机 ...
- centos7 yum搭建lamp
环境 系统:centos7 安装apache #yum 安装apache [root@localhost ~]# yum install httpd httpd-devel #启动httpd服务 [r ...
- Linq to SQL 语法整理(子查询 & in操作 & join )
子查询 描述:查询订单数超过5的顾客信息 查询句法: var 子查询 = from c in ctx.Customers where (from o in ctx.Orders group o by ...
- 【题解】P6329 【模板】点分树 | 震波
题外话 (其实模板题没必要在这里水题解的--主要是想说这个qwq) 小常数的快乐.jpg 我也不知道我为啥常数特别小跑得飞快--不加快读就能在 luogu 的最优解上跑到 rank5 ( 说不定深夜提 ...
- ado.net使用sqlparameter的方式
使用sqlparameter的方式,最终执行的sql语句 exec sp_executesql N'select top 1 ID,ZhangHu,MiMa,RID,ShiJian,EndTime,I ...
- vue+ springboot 分页(两种方式:sql分页 & PageHelper 分页)
方法一:sql分页 思路:使用数据库进行分页 前端使用element-ui的分页组件,往后台传第几页的起始行offest 以及每页多少行pageSize,后台根据起始行数和每页的行数可以算出该页的 ...
- git+pycharm结合使用
Pycharm + git 进行结合使用 第一步:Pycharm配置本地安装的Git 测试框架的负责人: 编写好一套能用的基础框架代码 --- > 上传到公司远程仓库 --- 设置团队协作成员 ...