hadoop yarn日志分离
根据hdfs的auditlog以及fsimage分析,yarn的日志文件占用了10%-20%的rpc请求以及文件量,这对namenode的性能有比较大的影响,特别是当集群规模越来越大,会影响生产业务。故下面的方案对yarn日志进行拆分,将日志写入一个独立的hdfs集群
运行yarn的集群(pascdev),日志写入集群(pasc)
一、 配置
hdfs-site.xml
//添加日志写入集群的nameservice
<property>
<name>dfs.nameservices</name>
<value>pascdev,pasc</value>
</property>
//添加日志写入集群的rpc端口
<property>
<name>dfs.ha.namenodes.pasc</name>
<value>CDM01,CDM02</value>
</property>
<property>
<name>dfs.namenode.rpc-address.pasc.CDM01</name>
<value>CDM01.qa.pab.com.cn:8020</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.pasc.CDM01</name>
<value>CDM01.qa.pab.com.cn:8021</value>
</property>
<property>
<name>dfs.namenode.rpc-address.pasc.CDM02</name>
<value>CDM02.qa.pab.com.cn:8020</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.pasc.CDM02</name>
<value>CDM02.qa.pab.com.cn:8021</value>
</property>
//添加日志集群的client.failover.proxy
<property>
<name>dfs.client.failover.proxy.provider.pasc</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
//为防止datanode向日志集群的namenode执行块汇报,添加以下配置
<property>
<name>dfs.internal.nameservices</name>
<value>pascdev</value>
</property>
yarn-site.xml
//修改Yarn日志路径
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>hdfs://pasc/metadata/logs/remoteyarn</value>
</property>
二、 部署相关Patch
(1)修改以上配置,重启hadoop服务后,报以下错误

原因是现有的版本不支持跨ns的日志聚合操作,部署Patch Yarn-3269
(2)解决跨ns问题后,再次重启服务,报以下错误,提示rpc认证错误

查看源码发现是在logaggragationservice的initappaggregator方法中获取用户的credential
通过打印日志,获取了Nodemananger在进行日志聚合操作时所持有的tokens,发现并没有集群pasc的HDFS_DELEGATION_TOKEN

通过添加代码修改这个问题:
credentials = new Credentials();
FileSystem remoteFs = getFileSystem(getconfig());
remoteFs.addDelegationTokens(UserGroupInformation.getLoginUser().getshortname(),credentials)
可以看到已经获取集群pasc的HDFS_DELEGATION_TOKEN

三、测试
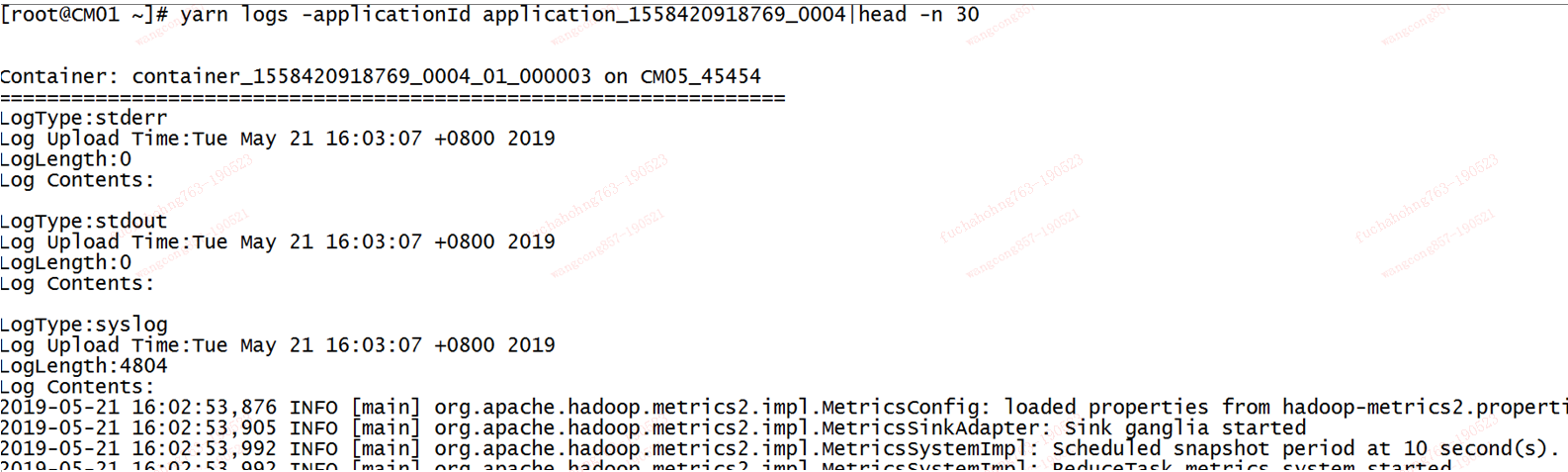
可以看到pasc集群上已经有该app执行的日志

同时可以在pascdev集群上通过yarn logs命令查看日志
hadoop yarn日志分离的更多相关文章
- Hadoop基础-完全分布式模式部署yarn日志聚集功能
Hadoop基础-完全分布式模式部署yarn日志聚集功能 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 其实我们不用配置也可以在服务器后台通过命令行的形式查看相应的日志,但为了更方 ...
- hadoop yarn
简介: 本文介绍了 Hadoop 自 0.23.0 版本后新的 map-reduce 框架(Yarn) 原理,优势,运作机制和配置方法等:着重介绍新的 yarn 框架相对于原框架的差异及改进:并通过 ...
- Hadoop - YARN 概述
一 概述 Apache Hadoop YARN (Yet Another Resource Negotiator,还有一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源 ...
- Hive分析hadoop进程日志
想把hadoop的进程日志导入hive表进行分析,遂做了以下的尝试. 关于hadoop进程日志的解析 使用正则表达式获取四个字段,一个是日期时间,一个是日志级别,一个是类,最后一个是详细信息, 然后在 ...
- Hadoop YARN配置参数剖析—RM与NM相关参数
注意,配置这些参数前,应充分理解这几个参数的含义,以防止误配给集群带来的隐患.另外,这些参数均需要在yarn-site.xml中配置. 1. ResourceManager相关配置参数 (1) ...
- Hadoop yarn配置参数
参照site:http://hadoop.apache.org/docs/r2.6.0/hadoop-yarn/hadoop-yarn-common/yarn-default.xml 我们在配置yar ...
- Hadoop YARN ERROR 1/1 local-dirs are bad *, 1/1 log-dirs are bad *
转 http://blog.csdn.net/u012303571/article/details/46913471 查看 nodemanager 日志发下 如下信息 2015-07-16 1 ...
- Hadoop Yarn 安装
环境:Linux, 8G 内存.60G 硬盘 , Hadoop 2.2.0 为了构建基于Yarn体系的Spark集群.先要安装Hadoop集群,为了以后查阅方便记录了我本次安装的详细步骤. 事前准备 ...
- [BigData - Hadoop - YARN] YARN:下一代 Hadoop 计算平台
Apache Hadoop 是最流行的大数据处理工具之一.它多年来被许多公司成功部署在生产中.尽管 Hadoop 被视为可靠的.可扩展的.富有成本效益的解决方案,但大型开发人员社区仍在不断改进它.最终 ...
随机推荐
- vue中watch深度监听
监听基本类型的都是浅度监听 watch的深度监听,监听复杂类型都是深度监听(funciton ,arrat ,object) // 监听对象 data(){ return { a:{ b:, c: } ...
- .NET中跨线程访问winform控件的方法
1 第一种方式 MethodInvoker invoker = () => { richTextBox1.AppendText(_ClientSocketModelConnectedEvent. ...
- linux常用命令(4)
linux常用命令(4) --- Vim编辑器与Shell命令脚本 如何使用vim编辑器来编写文档.配置主机名称.网卡参数以及yum仓库: 通过vim编辑器将Linux命令放入合适的逻辑测试语句(if ...
- iptables防火墙操作-查看、配置、重启、关闭
查看iptables端口配置 iptables -L -n --line-number iptables端口配置(不开通3389无法远程连接,不开通icmp无法ping) iptables -A IN ...
- 【2017-05-04】winfrom进程、线程、用户控件
一.进程 一个进程就是一个程序,利用进程可以在一个程序中打开另一个程序. 1.开启某个进程Process.Start("文件缩写名"); 注意:Process要解析命名空间. 2. ...
- AlertDialog 对话框 5种
MainActivity.class public class MainActivity extends AppCompatActivity implements View.OnClickListen ...
- C++第三次作业:作用域
作用域的定义 作用域是一个标识符在程序正文中有效的区域. 1.函数原型作用域 在函数原型声明时形式参数的作用范围就是函数原型作用域. 它是C++程序中最小的作用域. 例: double area(do ...
- 配置LANMP环境(7)-- 配置nginx反向代理,与配置apache虚拟主机
一.配置nginx反向代理 1.修改配置文件 vim /etc/nginx/nginx.conf 在35行http下添加一下内容: include /data/nginx/vhosts/*.conf; ...
- [angular2/4/8]用ng new创建项目卡住的解决办法
官方文档 英文版:https://angular.io/guide/quickstart 中文版:https://angular.cn/guide/quickstart Installing pack ...
- 洛谷P3690 Link Cut Tree (动态树)
干脆整个LCT模板吧. 缺个链上修改和子树操作,链上修改的话join(u,v)然后把v splay到树根再打个标记就好. 至于子树操作...以后有空的话再学(咕咕咕警告) #include<bi ...