sparkRDD:第4节 RDD的依赖关系;第5节 RDD的缓存机制;第6节 DAG的生成
4. RDD的依赖关系
6.1 RDD的依赖
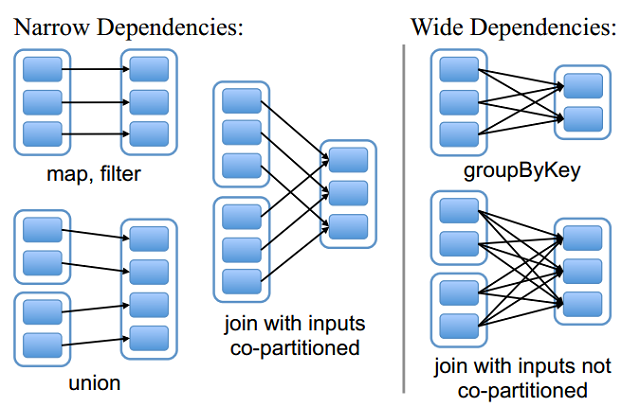
RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
6.2 窄依赖
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用
总结:窄依赖我们形象的比喻为独生子女。窄依赖不会产生shuffle,比如说:flatMap/map/filter....
6.3 宽依赖
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition
总结:宽依赖我们形象的比喻为超生。宽依赖会产生shuffle,比如说:reduceByKey/groupByKey...
6.4 Lineage(血统)
RDD只支持粗粒度转换,即只记录单个块上执行的单个操作。将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
7. RDD的缓存
Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或者缓存数据集。当持久化某个RDD后,每一个节点都将把计算分区结果保存在内存中,对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。
7.1 RDD缓存方式
RDD通过persist方法或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
rdd1.cache
rdd2.persist(org.apache.spark.storage.StorageLevel.DISK_ONLY)
cache和persist区别:
cache:默认是把数据缓存在内存中,其本质是调用了persist方法
eg. rdd1.cache
persist:它可以把数据缓存在磁盘中,它可以有很多丰富的缓存级别,这些缓存级别都被封装在一个object StorageLevel
eg. rdd3.persist(org.apache.spark.storage.StorageLevel.DISK_ONLY)

通过查看源码发现cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的。

缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
清除缓存数据:
(1)自动清除
整个应用程序结束之后,缓存中的所有数据自动清除
(2)手动清除
手动调用rdd的unpersist(true) //参数true,表示阻塞整个程序,知道所有缓存都清除后,才执行后面的逻辑;false,表示边清除缓存边执行后面的逻辑。
什么时候设置缓存:
(1)某个rdd后期被使用了多次
val rdd2=rdd1.flatMap(_.split(" "))
val rdd3=rdd1.map((_,1))
上面rdd1被使用了多次,后期可以对rdd1的结果数据进行缓存,缓存之后后面用到了它,可以直接从缓存中获取得到。避免重新计算,浪费时间。
(2)一个rdd的结果数据计算逻辑比较复杂或者是计算时间比较长-------> 总之 它的数据来之不易
val rdd1=sc.textFile("/words.txt").flatMap(_.split(" ")).xxxx .xxxxx..............
8. DAG的生成
8.1 什么是DAG
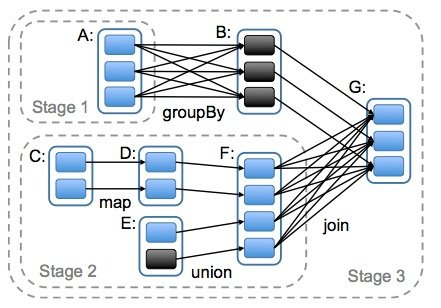
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间依赖关系的不同将DAG划分成不同的Stage(调度阶段)。对于窄依赖,partition的转换处理在一个Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
9. Spark任务调度
9.1 任务调度流程图
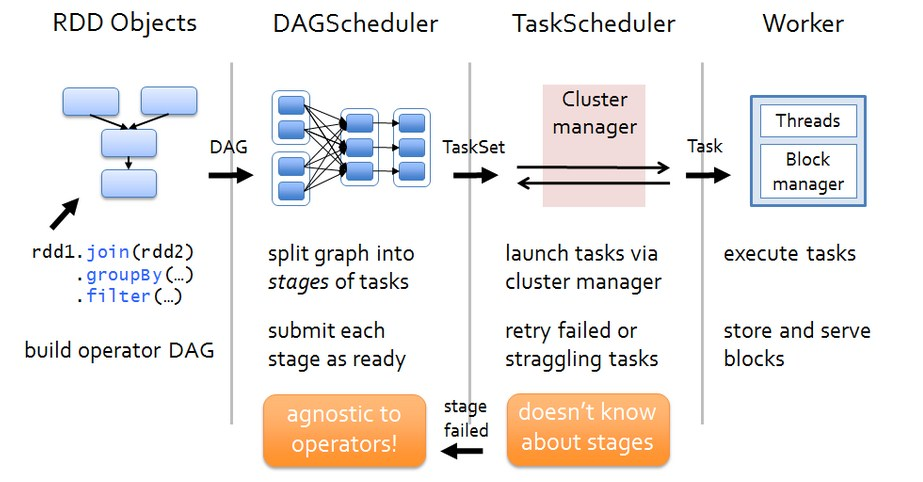
各个RDD之间存在着依赖关系,这些依赖关系就形成有向无环图DAG,DAGScheduler对这些依赖关系形成的DAG进行Stage划分,划分的规则很简单,从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。完成了Stage的划分。DAGScheduler基于每个Stage生成TaskSet,并将TaskSet提交给TaskScheduler。TaskScheduler 负责具体的task调度,最后在Worker节点上启动task。
任务调度的步骤详细说明:
(1)Driver会运行客户端main方法中的代码,代码就会构建SparkContext对象,在构建SparkContext对象中,会创建DAGScheduler和TaskScheduler,然后按照rdd一系列的操作生成DAG有向无环图。最后把DAG有向无环图提交给DAGScheduler。
(2)DAGScheduler拿到DAG有向无环图后,按照宽依赖进行stage的划分,这个时候会产生很多个stage,每一个stage中都有很多可以并行运行的task,把每一个stage中这些task封装在一个taskSet集合中,最后提交给TaskScheduler。
(3)TaskScheduler拿到taskSet集合后,依次遍历每一个task,最后提交给worker节点的exectuor进程中。task就以线程的方式运行在worker节点的executor进程中。
9.2 DAGScheduler
(1)DAGScheduler对DAG有向无环图进行Stage划分。
(2)记录哪个RDD或者 Stage 输出被物化(缓存),通常在一个复杂的shuffle之后,通常物化一下(cache、persist),方便之后的计算。
(3)重新提交shuffle输出丢失的stage(stage内部计算出错)给TaskScheduler
(4)将 Taskset 传给底层调度器
a)– spark-cluster TaskScheduler
b)– yarn-cluster YarnClusterScheduler
c)– yarn-client YarnClientClusterScheduler
9.3 TaskScheduler
(1)为每一个TaskSet构建一个TaskSetManager 实例管理这个TaskSet 的生命周期
(2)数据本地性决定每个Task最佳位置
(3)提交 taskset( 一组task) 到集群运行并监控
(4)推测执行,碰到计算缓慢任务需要放到别的节点上重试
(5)重新提交Shuffle输出丢失的Stage给DAGScheduler
sparkRDD:第4节 RDD的依赖关系;第5节 RDD的缓存机制;第6节 DAG的生成的更多相关文章
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- RDD的依赖关系
RDD的依赖关系 Rdd之间的依赖关系通过rdd中的getDependencies来进行表示, 在提交job后,会通过在DAGShuduler.submitStage-->getMissingP ...
- 021 RDD的依赖关系,以及造成的stage的划分
一:RDD的依赖关系 1.在代码中观察 val data = Array(1, 2, 3, 4, 5) val distData = sc.parallelize(data) val resultRD ...
- 【Spark】RDD的依赖关系和缓存相关知识点
文章目录 RDD的依赖关系 宽依赖 窄依赖 血统 RDD缓存 概述 缓存方式 RDD的依赖关系 RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency) 和宽依赖 ...
- 大数据学习day23-----spark06--------1. Spark执行流程(知识补充:RDD的依赖关系)2. Repartition和coalesce算子的区别 3.触发多次actions时,速度不一样 4. RDD的深入理解(错误例子,RDD数据是如何获取的)5 购物的相关计算
1. Spark执行流程 知识补充:RDD的依赖关系 RDD的依赖关系分为两类:窄依赖(Narrow Dependency)和宽依赖(Shuffle Dependency) (1)窄依赖 窄依赖指的是 ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark核心RDD、什么是RDD、RDD的属性、创建RDD、RDD的依赖以及缓存、
1:什么是Spark的RDD??? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
- Spark之RDD依赖关系及DAG逻辑视图
RDD依赖关系为成两种:窄依赖(Narrow Dependency).宽依赖(Shuffle Dependency).窄依赖表示每个父RDD中的Partition最多被子RDD的一个Partition ...
- Spark-Core RDD依赖关系
scala> var rdd1 = sc.textFile("./words.txt") rdd1: org.apache.spark.rdd.RDD[String] = . ...
随机推荐
- AtCoder AGC038 C-LCMs 题解
题目链接:https://agc038.contest.atcoder.jp/tasks/agc038_c?lang=en 题意:给定一个数组,求这个数组中所有数对的LCM之和. 分析:网上看到了很多 ...
- Servlt入门
Servlt入门 java的两种体系结构 C/S (客户端/服务器)体系结构 通讯效率高且安全,但系统占用多 B/S (浏览器/服务器)体系结构 节约开发成本 C/S (客户端/服务器)体系结 ...
- 放眼全球,关注游戏质量变化:腾讯WeTest发布《2019中国移动游戏质量白皮书》
2019是中国游戏市场,尤其是手游市场称得上是跌宕起伏的一年,同时也是各大厂商推陈出新突破过去的一年.面对竞争激烈的市场,手游厂商们不仅着眼于游戏质量的提升,更是将一众优秀的国产游戏带入到了海外市场, ...
- Jmeter-ServerAgent
You can specify the listening ports as arguments (0 disables listening), default is 4444: $ ./star ...
- django之关系及查询,数据类型,约束,分页
目录 关系 数据列类型 数据类型的约束 分页 关系 1. 一对一(水平分表) 母表: UserInfo id name age 子表: private id salary sp 创建模型语句: cla ...
- 树莓派安装中文输入法Fcitx及Google拼音输入法
本来是想给树莓派安装搜狗输入法的, 搜狗输入法Linux版:https://pinyin.sogou.com/linux/?r=pinyin 但是一直安装不成功,后面发现原来是系统架构不同导致的,搜狗 ...
- 新建maven工程运行出现Intellij idea 报错:Error : java 不支持发行版本5
Step1点击: 点击 保持一致: Step2点击 这样就可以了. 主要是运行时jdk版本不一致的问题
- JPA中实现双向多对多的关联关系(附代码下载)
场景 JPA入门简介与搭建HelloWorld(附代码下载): https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/103473937 ...
- Vim:Vim入门级配置
转:https://vimjc.com/vimrc-config.html Vim配置文件.vimrc Vim编辑器相关的所有功能开关都可以通过.vimrc文件进行设置. .vimrc配置文件分系统配 ...
- JavaSE复习~基本数据类型
数据类型 java有两大类数据类型:基本数据类型 和 引用数据类型 基本数据类型 整数型:byte.short.int.long 浮点型:float.double 字符型:char 布尔型:boole ...