使用nodejs的puppeteer库爬取瓜子二手车网站
const puppeteer = require('puppeteer');
(async () => {
const fs = require("fs");
const rootUrl = 'https://www.guazi.com'
const workPath = './contents';
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
const browser = await (puppeteer.launch({ headless: false }));
const page = await browser.newPage()
await page.setViewport({ width: 1128, height: 736 });
await page.setRequestInterception(true); // 拦截器
page.on('request', request => { //拦截图片
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto("https://www.guazi.com/fuzhou/buy")
const m_cityList = await page.evaluate(() => { // 获取所有城市
const elements = Array.from(document.querySelectorAll('.all-city dl'))
return elements.map(s => {
let dd = s.getElementsByTagName("dd").item(0)
let ddList = []
for (let i = 0; i < dd.getElementsByTagName("a").length; i++) {
ddList.push({
"cityName": dd.getElementsByTagName("a").item(i).innerHTML,
"url": dd.getElementsByTagName("a").item(i).getAttribute("href")
})
}
return ddList
})
})
//数组扁平化
const flattenNew = arr => arr.reduce((prev, next) => Object.prototype.toString.call(next) == '[object Array]' ? prev.concat(flattenNew(next)) : prev.concat(next), [])
const cityList = flattenNew(m_cityList)
console.log("城市列表爬取完毕")
await page.waitFor(2000 + Math.round(Math.random() * 100))
for (let i = 0; i < cityList.length; i++) {
await page.waitFor(1000 + Math.round(Math.random() * 100))
await page.goto(rootUrl + cityList[i].url)
console.log("跳转到" + cityList[i].cityName)
console.log("开始爬取" + cityList[i].cityName + "的所有二手车品牌")
try {
let brandList = await page.evaluate(() => { //品牌
let Array = []
const dl = document.querySelectorAll('.screen').item(0).getElementsByTagName("dl")
const div = dl.item(0).getElementsByTagName("dd").item(0).getElementsByTagName("div").item(1)
const ul = div.getElementsByTagName("ul")
for (let i = 0; i < ul.length; i++) {
let li = ul.item(i).getElementsByTagName("li")
for (let j = 0; j < li.length; j++) {
let a = li.item(j).getElementsByTagName("p").item(0).getElementsByTagName("a")
for (let k = 0; k < a.length; k++) {
Array.push({
"brand": a.item(k).innerHTML,
"url": a.item(k).getAttribute("href")
})
}
}
}
return Array
})
console.log(cityList[i].cityName + "的所有二手车品牌爬取完毕")
for (let j = 0; j < brandList.length; j++) {
console.log("开始爬取" + cityList[i].cityName + "-" + brandList[j].brand + "的所有车系")
await page.waitFor(1000 + Math.round(Math.random() * 100))
await page.goto(rootUrl + brandList[j].url)
try {
const carTypeList = await page.evaluate(() => { //车型
let Array = []
const dl = document.querySelectorAll('.screen').item(0).getElementsByTagName("dl")
const div = dl.item(1).getElementsByTagName("dd").item(0).getElementsByTagName("div").item(1)
const li = div.getElementsByTagName("ul").item(0).getElementsByTagName("li")
for (let j = 0; j < li.length; j++) {
let a = li.item(j).getElementsByTagName("p").item(0).getElementsByTagName("a")
for (let k = 0; k < a.length; k++) {
Array.push({
"carType": a.item(k).innerHTML.replace(/\s*/g, ""),
"url": a.item(k).getAttribute("href")
})
}
}
return Array
})
console.log(cityList[i].cityName + "-" + brandList[j].brand + "的所有车系爬取完毕")
for (let k = 0; k < carTypeList.length; k++) {
await page.waitFor(1000 + Math.round(Math.random() * 100))
console.log("开始爬取" + cityList[i].cityName + "-" + brandList[j].brand + "-" + carTypeList[k].carType + "的所有二手车")
let newUrl = rootUrl + carTypeList[k].url
pathArray = newUrl.split("/") //拿到第一页url,得到后面的页面的url
let urlArray = []
try {
await page.goto(newUrl)
const pageNum = await page.evaluate(() => { //获取总页数
let li = document.querySelectorAll("ul.pageLink").item(0).getElementsByTagName("li")
let liNum = li.length
return li.item(li.length - 2).getElementsByTagName("a").item(0).getElementsByTagName("span").item(0).innerHTML
})
for (let i = 1; i <= pageNum; i++) { //将所有的页面存入数组中
urlArray.push(newUrl.replace(new RegExp("/" + pathArray[pathArray.length - 1], 'g'), "/o" + i + "/" + pathArray[pathArray.length - 1]))
}
} catch (error) {
console.log(cityList[i].cityName + "-" + brandList[j].brand + "-" + carTypeList[k].carType + "的所有二手车列表爬取失败,该车型可能只有少量或者没有")
}
if (urlArray.length != 0) {
for (let i = 0; i < urlArray.length; i++) {
await page.goto(urlArray[i]);
const list = await page.evaluate(() => {
let carArray = []
let li = document.querySelectorAll("ul.carlist").item(0).getElementsByTagName("li")
for (let i = 0; i < li.length; i++) {
a = li.item(i).getElementsByTagName("a").item(0)
carArray.push({
"url": a.getAttribute("href"),
"imgUrl": a.getElementsByTagName("img").item(0).getAttribute("src"),
"carName": a.getElementsByTagName("h2").item(0).innerHTML,
"carData": (a.getElementsByTagName("div").item(0).innerHTML).replace(new RegExp('<span class="icon-pad">', 'g'), "").replace(new RegExp('</span>', 'g'), ""),
"price": a.getElementsByTagName("div").item(1).getElementsByTagName("p").item(0).innerHTML.replace(new RegExp('<span>', 'g'), "").replace(new RegExp('</span>', 'g'), "").replace(/\s*/g, "")
})
}
return carArray
})
await page.waitFor(500 + Math.round(Math.random() * 100))
console.log(list)
}
}else{
try {
const list = await page.evaluate(() => {
let carArray = []
let li = document.querySelectorAll("ul.carlist").item(0).getElementsByTagName("li")
console.log("该车型少量")
for (let i = 0; i < li.length; i++) {
a = li.item(i).getElementsByTagName("a").item(0)
carArray.push({
"url": a.getAttribute("href"),
"imgUrl": a.getElementsByTagName("img").item(0).getAttribute("src"),
"carName": a.getElementsByTagName("h2").item(0).innerHTML,
"carData": (a.getElementsByTagName("div").item(0).innerHTML).replace(new RegExp('<span class="icon-pad">', 'g'), "").replace(new RegExp('</span>', 'g'), ""),
"price": a.getElementsByTagName("div").item(1).getElementsByTagName("p").item(0).innerHTML.replace(new RegExp('<span>', 'g'), "").replace(new RegExp('</span>', 'g'), "").replace(/\s*/g, "")
})
}
return carArray
})
await page.waitFor(500 + Math.round(Math.random() * 100))
console.log(list)
} catch (error) {
console.log("该车型没有")
}
}
}
} catch (error) {
console.log(cityList[i].cityName + "-" + brandList[i].brand + "的所有车系爬取失败")
}
}
} catch (error) {
console.log(cityList[i].cityName + "二手车品牌爬取失败")
}
await page.waitFor(1000 + Math.round(Math.random() * 100))
}
})();
时间比较赶,先附上代码和运行截图
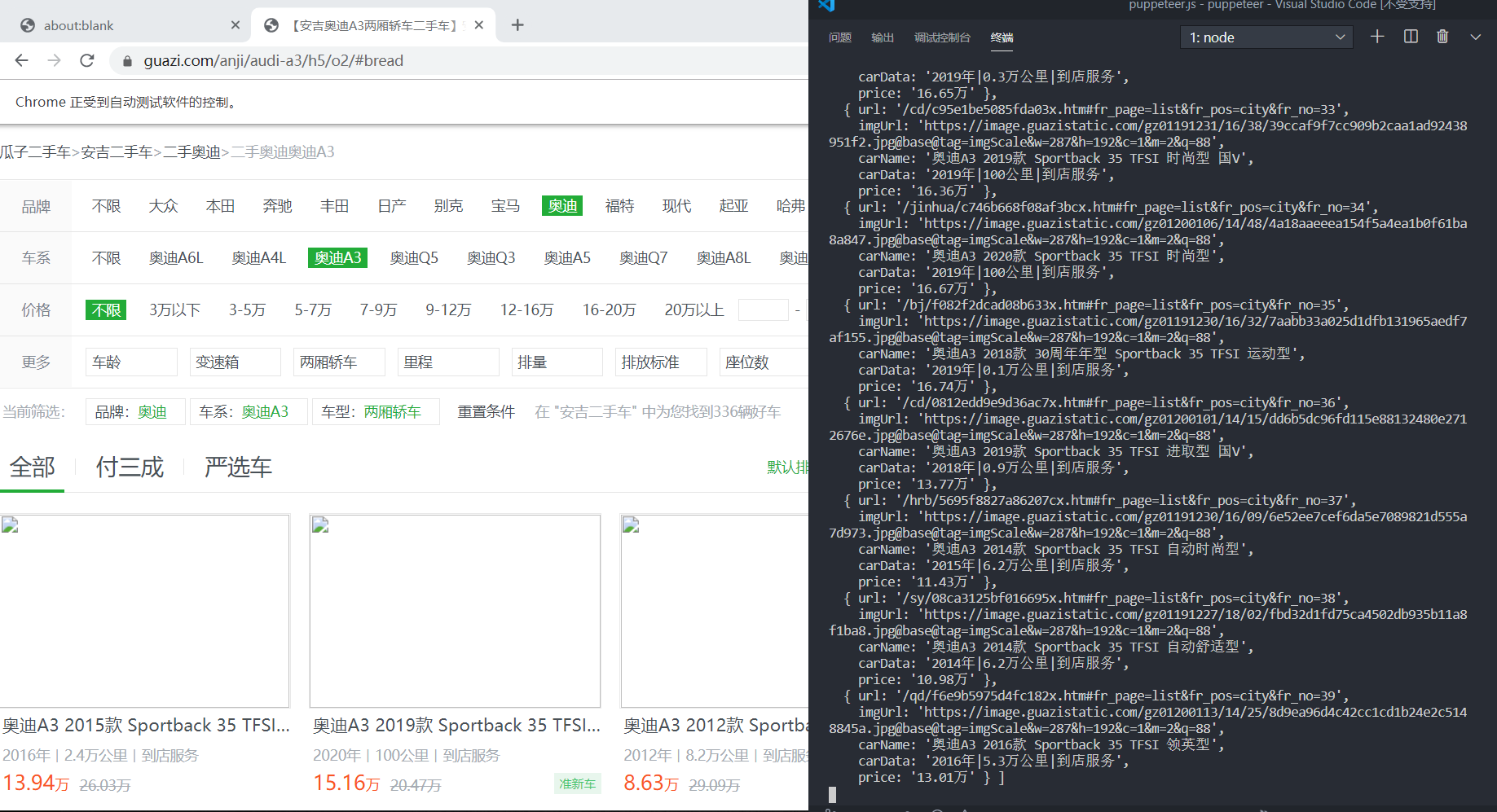
有兴趣的可以 看一下项目地址
https://gitee.com/xu_hui_hong/nodejs_puppeteer_guazi2
使用nodejs的puppeteer库爬取瓜子二手车网站的更多相关文章
- Python——爬取瓜子二手车
# coding:utf8 # author:Jery # datetime:2019/5/1 5:16 # software:PyCharm # function:爬取瓜子二手车 import re ...
- python爬虫学习之使用BeautifulSoup库爬取开奖网站信息-模块化
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件. 实 ...
- Python scrapy框架爬取瓜子二手车信息数据
项目实施依赖: python,scrapy ,fiddler scrapy安装依赖的包: 可以到https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载 pywi ...
- nodejs中使用cheerio爬取并解析html网页
nodejs中使用cheerio爬取并解析html网页 转 https://www.jianshu.com/p/8e4a83e7c376 cheerio用于node环境,用法与语法都类似于jquery ...
- 一起学爬虫——使用xpath库爬取猫眼电影国内票房榜
之前分享了一篇使用requests库爬取豆瓣电影250的文章,今天继续分享使用xpath爬取猫眼电影热播口碑榜 XPATH语法 XPATH(XML Path Language)是一门用于从XML文件中 ...
- python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件
第二个例子是使用requests库+re库爬取淘宝搜索商品页面的商品信息 (1)分析网页源码 打开淘宝,输入关键字“python”,然后搜索,显示如下搜索结果 从url连接中可以得到搜索商品的关键字是 ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- scrapy爬取西刺网站ip
# scrapy爬取西刺网站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem class Xicispi ...
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
随机推荐
- Lowest Common Multiple Plus(hdu2028)
思考: 乘法爆咋数据.把int换成unsigned就过了,同时%d换成%u.求最大公约数和最小公倍数. #include<stdio.h> int gcd(unsigned x, unsi ...
- python遍历
实现遍历: #coding=utf-8 #遍历的2种方式 import os #1.使用os.listdir(f) def traverse(f): fs = os.listdir(f) for f1 ...
- Kubernetes学习笔记(六):使用ConfigMap和Secret配置应用程序
概述 本文的核心是:如何处理应用程序的数据配置. 配置应用程序可以使用以下几种途径: 向容器传递命令行参数 为每个容器配置环境变量 通过特殊的卷将配置文件挂载到容器中 向容器传递命令行参数 在Kube ...
- Unity 游戏框架搭建 2019 (四十八/四十九) MonoBehaviourSimplify 中的消息策略完善&关于发送事件的简单封装
MonoBehaviourSimplify 中的消息策略完善 在上一篇,笔者说,MonoBehaviourSimplify 中的消息策略还有一些小问题.我们在这篇试着解决一下. 先贴出来代码: usi ...
- 人机协同与AI能力训练
我们进行<中台战略>一书的第三期分享. “人机融合是解决aI机器人冷启动的绝佳解决方案,我们这里引入了一个应答满意度的指标,每一个咨询应答都对应一个应答满意度.当消费者应该回答选择转入人工 ...
- Java——MVC模式
MVC:Model View Controller 一般用于动态程序设计,实现了业务逻辑和表示层分离 Model:掌控数据源-->程序员编写程序或者实现算法,数据库人员进行数据库操作等:响应用户 ...
- eatwhatApp开发实战(十二)
上次我们介绍了跳转activity并且实现传值的功能,今天我们来实现双击返回键退出app的功能,上代码: 这里我们有两种方式去实现点击事件: 第一种方式: /** * 返回键的监听(系统提供的) */ ...
- [安卓基础] 008.Android中的显示单位
*:first-child { margin-top: 0 !important; } body > *:last-child { margin-bottom: 0 !important; } ...
- Java并没有衰落.大家对它的认识才刚刚开始 Java8全新出发
Java并没有衰落.大家对它的认识才刚刚开始 很高兴能在此给大家分享Java8的新特性.这篇文章将一步一步带你了解Java8的所有新特性.我将通过简单的实例代码向大家展示接口中默认方法,lambda ...
- (易忘篇)java基本语法难点1
switch后面使用的表达式可以是哪些数据类型 byte.short.char.int.枚举类型变量.String类型. 如何从控制台获取String和int型的变量,并输出 // 以下只关注重要点的 ...