NLP-BM25算法理解
Okapi BM25:一个非二值的模型
bm25 是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法。
举个例子:我们查询关键词red apple ,将其分词为red 和apple,我们在我们的1000个文档中分别索引这两个词,但是我们发现red的似乎经常出现,然而apple出现频率不高,那我们将这一千个文档进行得分排序,如果某个文档中red出现的次数很高,而apple出现次数很少,安装普通的得分排序的话(出现一次算一分)那我们red出现越多,它的分数就会越高,但是这却违背了我们所需要,因为我们检索的是red apple,所以,BM25就是来消除这种相关性不高的问题,即为我们所查询的词有一个权值比重,即为idf(这里我们后面会讲解)。
**1.BM25模型**
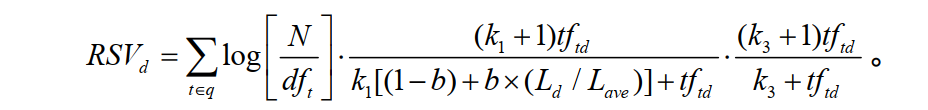
其实,这个公式不难理解,他只有三个部分
1.计算单词权重:
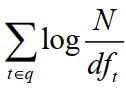
2.单词和文档的相关度:
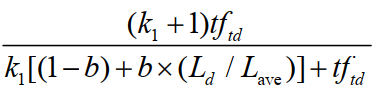
3.单词和query(关键词)的相关性:
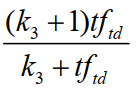
在上面我们已经看到了公式,但是还不是很理解是什么意思,所以这里我们慢慢理解体会:
N:是所有的文档数目.
dft:是我们的关键词通过倒排算法得出的包含t的文档数目(即为上述例子中,red 在1000个文档中出现的文档次数)
例如,我们在1000个文档中出现red的次数为10,那么**N/dft**=100,即可算出他的权重。
**3.tf解释(单词和文档相关度)**
其实,BM25最主要的方面在于 idf*tf,就是查询词的权重*查询词和文档的相关性。
tftd:tftd 是词项 t 在文档 d 中的权重。
Ld 和 Lave :分别是文档 d 的长度及整个文档集中文档的平均长度。
k1:是一个取正值的调优参数,用于对文档中的词项频率进行缩放控制。如果 k 1 取 0,则相当于不考虑词频,如果 k 1取较大的值,那么对应于使用原始词项频率。
b :是另外一个调节参数 (0≤ b≤ 1),决定文档长度的缩放程度:b = 1 表示基于文档长度对词项权重进行完全的缩放,b = 0 表示归一化时不考虑文档长度因素。
**4.单词和query(关键词)的相关性解释**
tftq:是词项t在查询q中的权重。
k3: 是另一个取正值的调优参数,用于对查询中的词项tq 频率进行缩放控制。

NLP-BM25算法理解的更多相关文章
- Okapi BM25算法
引言 Okapi BM25,一般简称 BM25 算法,在 20 世纪 70 年代到 80 年代,由英国一批信息检索领域的计算机科学家发明.这里的 BM 是"最佳匹配"(Best M ...
- 文本相似度-BM25算法
BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms app ...
- 关于KMP算法理解(快速字符串匹配)
参考:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html 2016-08- ...
- 文本相似度 — TF-IDF和BM25算法
1,$TF-IDF$算法 $TF$是指归一化后的词频,$IDF$是指逆文档频率.给定一个文档集合$D$,有$d_1, d_2, d_3, ......, d_n \in D$.文档集合总共包含$m$个 ...
- Project2--Lucene的Ranking算法修改:BM25算法
原文出自:http://blog.csdn.net/wbia2010lkl/article/details/6046661 1. BM25算法 BM25是二元独立模型的扩展,其得分函数有很 ...
- FFT算法理解与c语言的实现
完整内容迁移至 http://www.face2ai.com/DIP-2-3-FFT算法理解与c语言的实现/ http://www.tony4ai.com/DIP-2-3-FFT算法理解与c语言的实现 ...
- EM算法理解的九层境界
EM算法理解的九层境界 EM 就是 E + M EM 是一种局部下限构造 K-Means是一种Hard EM算法 从EM 到 广义EM 广义EM的一个特例是VBEM 广义EM的另一个特例是WS算法 广 ...
- HMM-前向后向算法理解与实现(python)
目录 基本要素 HMM三大问题 概率计算问题 前向算法 后向算法 前向-后向算法 基本要素 状态 \(N\)个 状态序列 \(S = s_1,s_2,...\) 观测序列 \(O=O_1,O_2,.. ...
- HMM-维特比算法理解与实现(python)
HMM-前向后向算法理解与实现(python) HMM-维特比算法理解与实现(python) 解码问题 给定观测序列 \(O=O_1O_2...O_T\),模型 \(\lambda (A,B,\pi) ...
随机推荐
- HTML5存储--离线存储
离线存储技术 HTML5提出了两大离线存储技术:localstorage与Application Cache,两者各有应用场景:传统还有离线存储技术为Cookie. 经过实践我们认为localstor ...
- C# 获取pdf长宽,反推pdf图纸类型
业务需求:读取pdf每页的长宽,然后根据国际标准,反推出pdf图纸类型 第一步:下载类库,并引入到项目中 链接:https://pan.baidu.com/s/1ud4-xhfDvi9OKolEBPw ...
- 路由器静态IP的配置及其备份静态路由缺省路由
静态路由时管理员手动配置并维护的路由.静态路由配置简单,被广泛应用于网络中.静态路由还可以实现负载均衡和路由备份.学习掌握好静态路由的配置是很重要的. 如下图, 首先进入路由器的命令视图,(sys) ...
- comparator接口实现时,只需要实现 int compare(T o1, T o2)方法?
从Comparator接口的源码,可以看到Comparator接口中的方法有三类: 1 普通接口方法 2 default方法 3 static方法 其中default方法和static方法 是java ...
- pytest3-命令行选项
1.pytest -h 查看pytest常用命令 E:\myproj\pytest_demo>pytest -h usage: pytest [options] [file_or_dir] [f ...
- 介绍Webflux
介绍Webflux 关于WebFlux 我们知道传统的Web框架,比如说:struts2,springmvc等都是基于Servlet API与Servlet容器基础之上运行的,在Servlet3.1之 ...
- java类对象的初始化顺序
在下面这个例子中,我们分别在父类和子类中测试了静态代码块.普通代码块.静态成员变量.普通成员变量.构造器.静态内部类. 一:代码块及变量测试 class Field{ public static St ...
- 关于举办【福州】《K8S社区线下技术交流会》的问卷调查
近年来,容器.Kubernetes.DevOps.微服务.Serverless等一系列云原生技术受到越来越多的关注,云原生为企业数字化转型提供了创新源动力,基于云原生技术构建企业技术中台在各行业也 ...
- 解析 Microsoft.Extensions.DependencyInjection 2.x 版本实现
项目使用了 Microsoft.Extensions.DependencyInjection 2.x 版本,遇到第2次请求时非常高的内存占用情况,于是作了调查,本文对 3.0 版本仍然适用. 先说结论 ...
- scrollWidth、clientWidth 和 offsetWidth
scrollWidth:对象的实际内容宽度,不包括边线宽度,会随对象中内容超过可视区而变大. clientWidth:对象内容的可视区的宽度,不包括边线宽度,会随对象显示大小的变化而变化. offse ...