Web Scraper 高级用法——抓取属性信息 | 简易数据分析 16

这是简易数据分析系列的第 16 篇文章。
这期课程我们讲一个用的较少的 Web Scraper 功能——抓取属性信息。
网页在展示信息的时候,除了我们看到的内容,其实还有很多隐藏的信息。我们拿豆瓣电影250举个例子:
电影图片正常显示的时候是这个样子:

如果网络异常,图片加载失败,就会显示图片的默认文案,这个文案其实就是这个图片的属性信息:

我们查看一下这个结构的 HTML(查看方法可见 CSS 选择器的使用的第一节内容),就会发现图片的默认文案其实就是这个 <img/> 标签的 alt 属性:

我们可以看一下 HTML 文档里对 alt 属性的描述:
alt 属性是一个必需的属性,它规定在图像无法显示时的替代文本
在 web scraper 里,我们可以利用 Element attribute 属性来抓取这种属性信息。
因为这次的内容比较简单,新建 sitemap 这一步我就先省略了,我们直接上来使用 Element attribute 抓取数据。
我们把 Type 选为 Element attribute,然后用 Selector 选中图片这个元素:
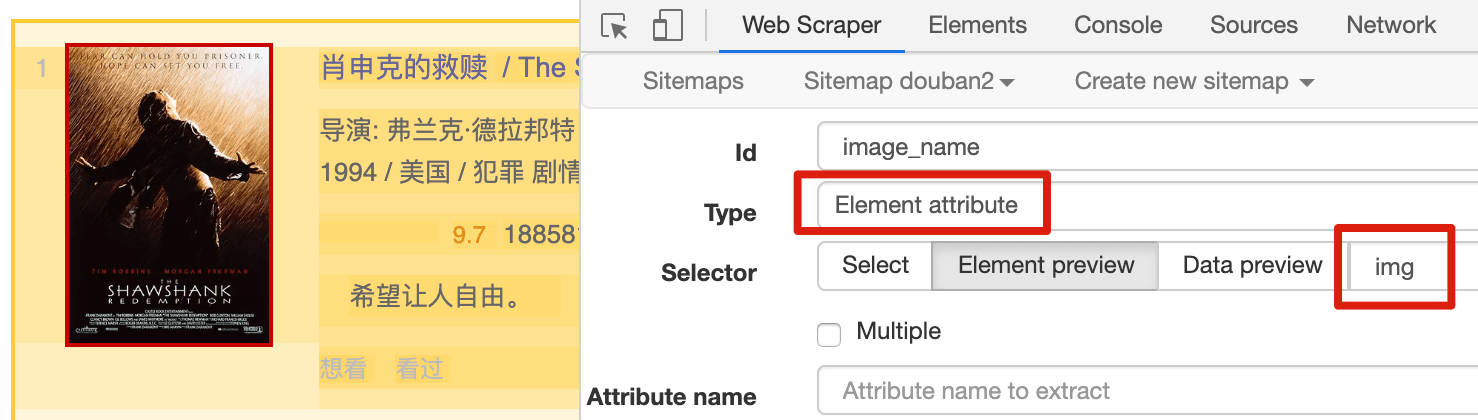
Element attribute 会多一个选项——Attribute name,我们在这个输入框里输入我们要抓取的属性名字。
观察一下这个 img 标签的属性,有 alt(替换文本)、width(图片宽度)和 src(图片链接)3 种:

这里我先输入 alt,表示抓取图片的替代文本:

还可以输入 src,表示抓取图片的链接:

也可以输入 width,抓取图片宽度:

通过 Element attribute 这个选择器,我们就可以抓取一些网页没有直接展示出来的数据信息,非常的方便。
sitemap 分享
{"_id":"douban2","startUrl":["https://movie.douban.com/top250?start=0&filter="],"selectors":[{"id":"ele","type":"SelectorElement","parentSelectors":["_root"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"image_name","type":"SelectorElementAttribute","parentSelectors":["ele"],"selector":"img","multiple":false,"extractAttribute":"alt","delay":0}]}
推荐阅读
Web Scraper 高级用法——CSS 选择器的使用 | 简易数据分析 15
联系我
因为文章发在各大平台上,账号较多不能及时回复评论和私信,有问题可关注公众号 ——「卤蛋实验室」,(或 wx 搜索 egglabs)关注上车防失联。

Web Scraper 高级用法——抓取属性信息 | 简易数据分析 16的更多相关文章
- Web Scraper 高级用法——使用 CouchDB 存储数据 | 简易数据分析 18
这是简易数据分析系列的第 18 篇文章. 利用 web scraper 抓取数据的时候,大家一定会遇到一个问题:数据是乱序的.在之前的教程里,我建议大家利用 Excel 等工具对数据二次加工排序,但还 ...
- Web Scraper 翻页——控制链接批量抓取数据(Web Scraper 高级用法)| 简易数据分析 05
这是简易数据分析系列的第 5 篇文章. 上篇文章我们爬取了豆瓣电影 TOP250 前 25 个电影的数据,今天我们就要在原来的 Web Scraper 配置上做一些小改动,让爬虫把 250 条电影数据 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
- Web Scraper 高级用法——利用正则表达式筛选文本信息 | 简易数据分析 17
这是简易数据分析系列的第 17 篇文章. 学习了这么多课,我想大家已经发现了,web scraper 主要是用来爬取文本信息的. 在爬取的过程中,我们经常会遇到一个问题:网页上的数据比较脏,我们只需要 ...
- 简易数据分析 15 | Web Scraper 高级用法——CSS 选择器的使用
这是简易数据分析系列的第 15 篇文章. 年末事情比较忙,很久不更新了,后台一直有读者催更,我看了一些读者给我的私信,发现一些通用的问题,所以单独写篇文章,介绍一些 Web Scraper 的进阶用法 ...
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- Fiddler高级用法-抓取手机app数据包
在上一篇中介绍了Fiddler的基本使用方法.通过上一篇的操作我们可以直接抓取浏览器的数据包.但在APP测试中,我们需要抓取手机APP上的数据包,应该怎么操作呢? Andriod配置方法 1)确保手机 ...
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格
通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码.(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息 ...
随机推荐
- 前端-HTLM
前端简介: 什么是前端? 任何与用户直接打交道的操作界面都可以被称为前端,如:网页界面,手机界面.... 前端的学习历程和内容: 要学习的内容: 三大重点: 1.Web服务的本质: 浏览器中敲入网址回 ...
- redis day02 下
位图:是二进制数据(0101101010)2^32 强势点: 01_login :101110(比如:第一天登录,二天没登录) 传统的字符串解决方案中 记录用户登录日期 统计堪忧 01_login_ ...
- VS编译release版本的出现的LNK1104 无法打开文件“libboost_filesystem-vc140-mt-1_58.lib
最近在用restbed和vs2015做一个项目,debug编译的没问题,但是编译release就有问题,困扰了一天,说下我的出坑过程. 1.我用到了外部的库 restbed ,首先要想正确编译过,你的 ...
- 如何回收VCSA 6自带的vPostgres数据库空间
最近有学生连续反应由于VCSA磁盘空间满了,导致服务无法正常启动,寻求压缩数据库空间的问题.首先说下,VCSA的数据库是没办法图形界面管理的, 它的内置vPostgres数据库的管理只能通过命令行来完 ...
- Spring Security Config : 注解 EnableWebSecurity 启用Web安全
https://blog.csdn.net/andy_zhang2007/article/details/90023901
- [Linux] Windows 下通过SecureCRT 访问 Linux
不愿意装双系统的,可以借助虚拟机(Vmware, Virtual PC等) 安装linux 进行使用. 至于如何使用虚拟机安装Linux 这部分,很简单: 下载好需要安装的Linux ISO 镜像文件 ...
- mysql配置白名单
1. 测试是否允许远程连接 $ telnet 192.168.1.8 3306 host 192.168.1.4 is not allowed to connect to this mysql ser ...
- FPGA浮点数定点数的处理
http://blog.chinaaet.com/justlxy/p/5100053166大佬博客,讲的非常有条理的 1,基础知识 (1)定点数的基础认知: 首先例如一个16位的数表示的定点数的范围是 ...
- git本地仓库目录问题
git安装后修改默认的路径:每次打开git bash后都会进入这个目录 https://blog.csdn.net/weixin_39634961/article/details/79881140 在 ...
- 安装VSCODE和typora黑屏
工欲善其事必先利其器,本来是为了学git为了保存代码,然后网上一顿搜索研究之后发现,用git来保存笔记也不错,因为现在用的onenote搜索实在在在在是太不方便了,除了搜索不行,其他方面她还是很好的, ...