【Python3爬虫】微博用户爬虫
此次爬虫要实现的是爬取某个微博用户的关注和粉丝的用户公开基本信息,包括用户昵称、id、性别、所在地和其粉丝数量,然后将爬取下来的数据保存在MongoDB数据库中,最后再生成几个图表来简单分析一下我们得到的数据。
一、具体步骤:
这里我们选取的爬取站点是https://m.weibo.cn,此站点是微博移动端的站点,我们可以直接查看某个用户的微博,比如https://m.weibo.cn/profile/5720474518。
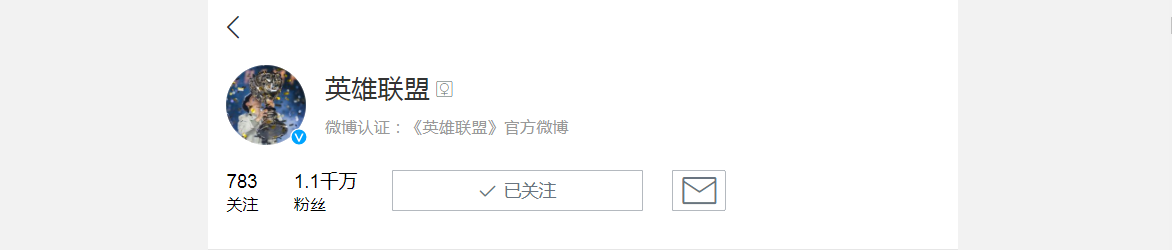
然后查看其关注的用户,打开开发者工具,切换到XHR过滤器,一直下拉列表,就会看到有很多的Ajax请求。这些请求的类型是Get类型,返回结果是Json格式,展开之后就能看到有很多用户的信息。
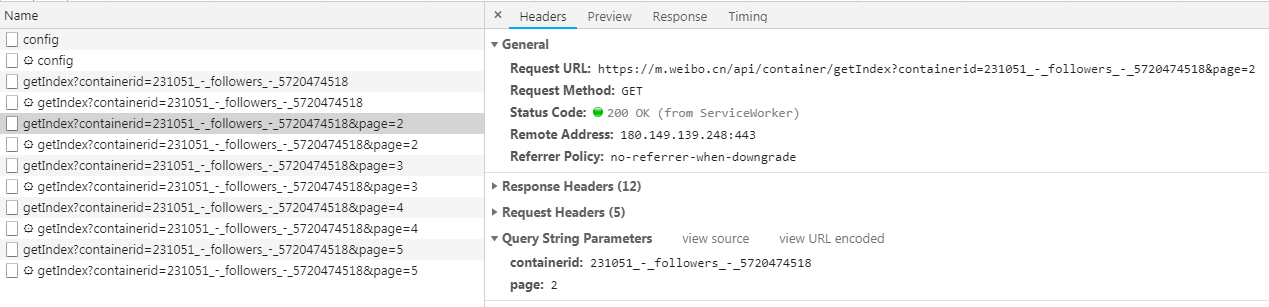
这些请求有两个参数,containerid和page,通过改变page的数值,我们就能得到更多的请求了。获取其粉丝的用户信息的步骤是一样的,除了请求的链接不同之外,参数也不同,修改一下就可以了。
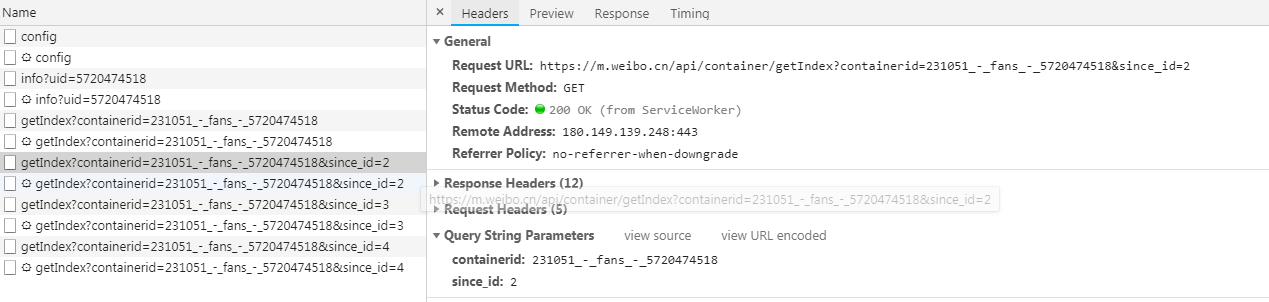
由于这些请求返回的结果里只有用户的名称和id等信息,并没有包含用户的性别等基本资料,所以我们点进某个人的微博,然后查看其基本资料,比如这个,打开开发者工具,可以找到下面这个请求:
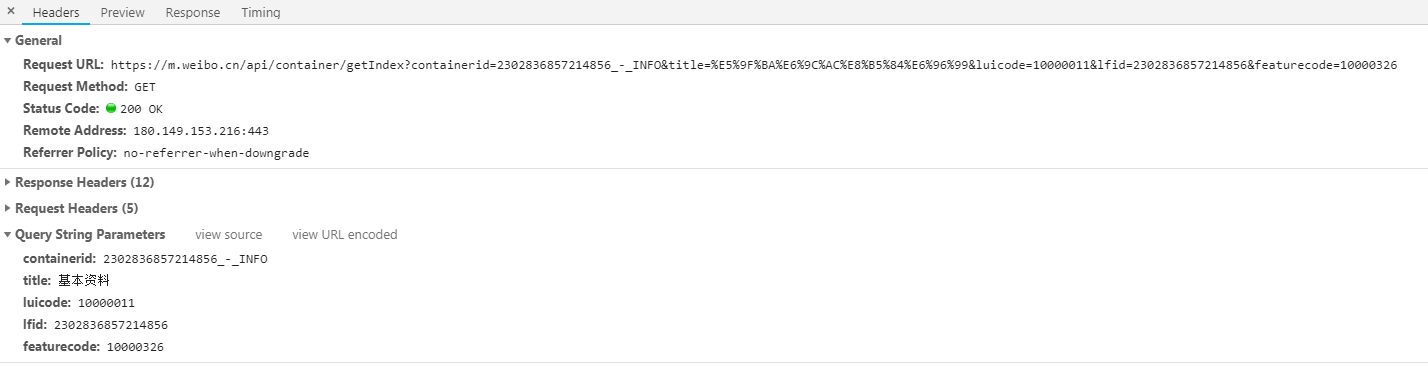
由于这个人的id是6857214856,因此我们可以发现当我们得到一个人的id的时候,就可以构造获取基本资料的链接和参数了,相关代码如下(uid就是用户的id):
uid_str = "" + str(uid)
url = "https://m.weibo.cn/api/container/getIndex?containerid={}_-_INFO&title=%E5%9F%BA%E6%9C%AC%E8%B5%84%E6%96%99&luicode=10000011&lfid={}&featurecode=10000326".format(uid_str, uid_str)
data = {
"containerid": "{}_-_INFO".format(uid_str),
"title": "基本资料",
"luicode": 10000011,
"lfid": int(uid_str),
"featurecode": 10000326
9 }
然后这个返回的结果也是Json格式,提取起来就很方便,因为很多人的基本资料都不怎么全,所以我提取了用户昵称、性别、所在地和其粉丝数量。而且因为一些账号并非个人账号,就没有性别信息,对于这些账号,我选择将其性别设置为男性。不过在爬取的时候,我发现一个问题,就是当页数超过250的时候,返回的结果就已经没有内容了,也就是说这个方法最多只能爬250页。对于爬取下来的用户信息,全都保存在MongoDB数据库中,然后在爬取结束之后,读取这些信息并绘制了几个图表,分别绘制了男女比例扇形图、用户所在地分布图和用户的粉丝数量柱状图。
二、主要代码:
由于第一页返回的结果和其他页返回的结果格式是不同的,所以要分别进行解析,而且因为部分结果的json格式不同,所以可能报错,因此采用了try...except...把出错原因打印出来。
爬取第一页并解析的代码如下:
def get_and_parse1(url):
res = requests.get(url)
cards = res.json()['data']['cards']
info_list = []
try:
for i in cards:
if "title" not in i:
for j in i['card_group'][1]['users']:
user_name = j['screen_name'] # 用户名
user_id = j['id'] # 用户id
fans_count = j['followers_count'] # 粉丝数量
sex, add = get_user_info(user_id)
info = {
"用户名": user_name,
"性别": sex,
"所在地": add,
"粉丝数": fans_count,
}
info_list.append(info)
else:
for j in i['card_group']:
user_name = j['user']['screen_name'] # 用户名
user_id = j['user']['id'] # 用户id
fans_count = j['user']['followers_count'] # 粉丝数量
sex, add = get_user_info(user_id)
info = {
"用户名": user_name,
"性别": sex,
"所在地": add,
"粉丝数": fans_count,
}
info_list.append(info)
if "followers" in url:
print("第1页关注信息爬取完毕...")
else:
print("第1页粉丝信息爬取完毕...")
save_info(info_list)
except Exception as e:
print(e)
爬取其他页并解析的代码如下:
def get_and_parse2(url, data):
res = requests.get(url, headers=get_random_ua(), data=data)
sleep(3)
info_list = []
try:
if 'cards' in res.json()['data']:
card_group = res.json()['data']['cards'][0]['card_group']
else:
card_group = res.json()['data']['cardlistInfo']['cards'][0]['card_group']
for card in card_group:
user_name = card['user']['screen_name'] # 用户名
user_id = card['user']['id'] # 用户id
fans_count = card['user']['followers_count'] # 粉丝数量
sex, add = get_user_info(user_id)
info = {
"用户名": user_name,
"性别": sex,
"所在地": add,
"粉丝数": fans_count,
}
info_list.append(info)
if "page" in data:
print("第{}页关注信息爬取完毕...".format(data['page']))
else:
print("第{}页粉丝信息爬取完毕...".format(data['since_id']))
save_info(info_list)
except Exception as e:
print(e)
三、运行结果:
在运行的时候可能会出现各种各样的错误,有的时候返回结果为空,有的时候解析出错,不过还是能成功爬取大部分数据的,这里就放一下最后生成的三张图片吧。
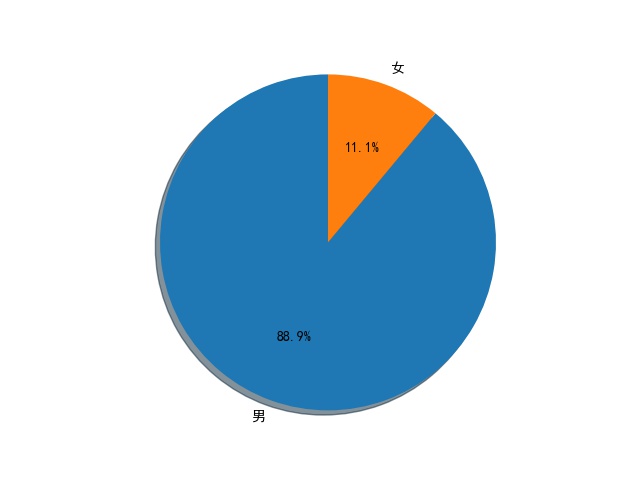
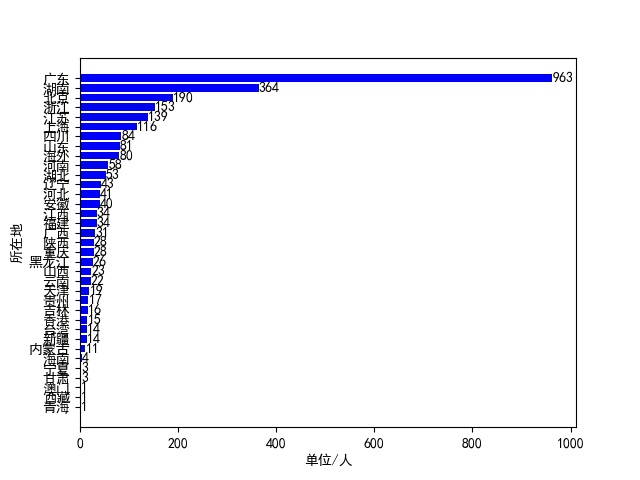

完整代码已上传到GitHub!



【Python3爬虫】微博用户爬虫的更多相关文章
- 微博爬虫,python微博用户主页小姐姐图片内容采集爬虫
python爬虫,微博爬虫,需要知晓微博用户id号,能够通过抓取微博用户主页内容来获取用户发表的内容,时间,点赞数,转发数等数据,当然以上都是本渣渣结合网上代码抄抄改改获取的! 要抓取的微博地址:ht ...
- Python 微博搜索爬虫
微博搜索爬虫 网页分析 由于网页端反爬虫机制比较完善所以才去移动端进行爬虫. url地址:https://m.weibo.cn/ 搜索框,输入关键词进行搜索 对网页进行抓包,找到相关数据 查看数据是否 ...
- Python爬虫入门教程 34-100 掘金网全站用户爬虫 scrapy
爬前叨叨 已经编写了33篇爬虫文章了,如果你按着一个个的实现,你的爬虫技术已经入门,从今天开始慢慢的就要写一些有分析价值的数据了,今天我选了一个<掘金网>,我们去爬取一下他的全站用户数据. ...
- 【收藏】收集的各种Python爬虫、暗网爬虫、豆瓣爬虫、抖音爬虫 Github1万+星
收集的各种Python爬虫.暗网爬虫.豆瓣爬虫 Github 1万+星 磁力搜索网站2020/01/07更新 https://www.cnblogs.com/cilisousuo/p/1209954 ...
- 【Python网络爬虫一】爬虫原理和URL基本构成
1.爬虫定义 网络爬虫,即Web Spider,是一个很形象的名字.把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛.网络蜘蛛是通过网页的链接地址来寻找网页的.从网站某一个页面(通常 ...
- crawler_爬虫_反爬虫策略
关于反爬虫和恶意攻击的一些策略和思路 有时网站经常受到恶意spider攻击,疯狂抓取网站内容,对网站性能有较大影响. 下面我说说一些反恶意spider和spam的策略和思路. 1. 通过日志分析来 ...
- Python爬虫从入门到放弃(二十二)之 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- python爬虫(一)_爬虫原理和数据抓取
本篇将开始介绍Python原理,更多内容请参考:Python学习指南 为什么要做爬虫 著名的革命家.思想家.政治家.战略家.社会改革的主要领导人物马云曾经在2015年提到由IT转到DT,何谓DT,DT ...
- Python爬虫-01:爬虫的概念及分类
目录 # 1. 为什么要爬虫? 2. 什么是爬虫? 3. 爬虫如何抓取网页数据? # 4. Python爬虫的优势? 5. 学习路线 6. 爬虫的分类 6.1 通用爬虫: 6.2 聚焦爬虫: # 1. ...
随机推荐
- P2733 家的范围 Home on the Range-弱DP
P2733 家的范围 Home on the Range 思路 :转化为以每个点为右下角的 最大正方形的边长 #include<bits/stdc++.h> using namespace ...
- Vue使用过程中常见问题
目录 一.vue监听不到state数组/json对象内的元素的值的变化,要手动通知触发 二.vue用splice删除多维数组元素导致视图更新失败情况 三.vue项目如何部署到php或者java环境的服 ...
- 学习随笔:Vue.js与Django交互以及Ajax和axios
1. Vue.js地址 Staticfile CDN(国内): https://cdn.staticfile.org/vue/2.2.2/vue.min.js unpkg:会保持和npm发布的最新的版 ...
- 第n次搭建 SSM 框架
什么说第 N 次搭建SSM框架呢? 刚学习java的时候,搭建 SSM 框架想做一个个人项目之类的,后来没搭起来,也就拖延了,进入公司之后,接触的第一个项目就是SSM的,模仿了一下,也能搭个简简单单的 ...
- fidderl 录制导出 jmeter格式文件
总共需要五步 1.下载扩展脚本 2.将下载后的文件剪切到 fiddler 安装目录下 3.重新启动fillder 4.设置筛选条件 5.录制完成后导出文件 1.下载扩展脚本 首先需要下载支持jmete ...
- tensorflow 使用 1 常量,变量
import tensorflow as tf #创建一个常量 op 一行二列 m1 = tf.constant([[3, 3]]) #创建一个常量 op 二行一列 m2 = tf.constant( ...
- angular.lowercase()
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- HTML入门11
在网页中添加矢量图形, 使用矢量图形在很多情况下,效果较好,拥有较小的文件尺寸,高度缩放,下面具体讲解如何在网页中添加矢量图形 位图和矢量图 位图文件包含了每个像素的位置和色彩信息,流行的位图格式包括 ...
- matlab安装 macos
http://pan.baidu.com/s/1o6qKdxo内附安装说明Matlab R2014A Mac & Linux 破解版 readme文件有流程!可以安装
- SpringAop注解实现日志的存储
一.介绍 1.AOP的作用 在OOP中,正是这种分散在各处且与对象核心功能无关的代码(横切代码)的存在,使得模块复用难度增加.AOP则将封装好的对象剖开,找出其中对多个对象产生影响的公共行为,并将其封 ...