第三篇:R语言数据可视化之条形图
条形图简介
数据可视化中,最常用的图非条形图莫属,它主要用来展示不同分类(横轴)下某个数值型变量(纵轴)的取值。其中有两点要重点注意:
1. 条形图横轴上的数据是离散而非连续的。比如想展示两商品的价格随时间变化的走势,则不能用条形图,因为时间变量是连续的;
2. 有时条形图的值表示数值本身,但也有时是表示数据集中的频数,不要引起混淆;
绘制基本条形图
本例选用测试数据集如下:
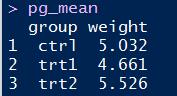
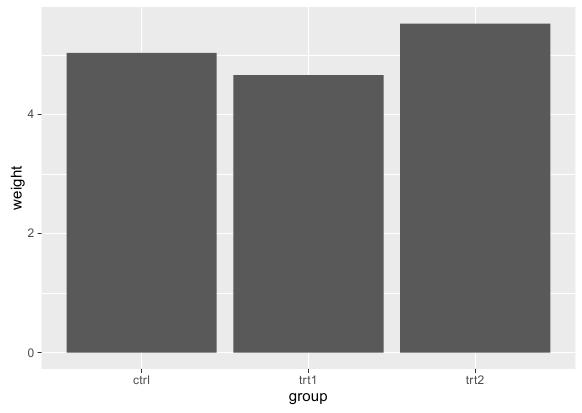
绘制方法是首先调用ggplot函数选定数据集,并在aes参数中指明横轴纵轴。然后调用条形图函数geom_bar(stat="identity")便可绘制出基本条形图。其中stat="identity"表明取用样本点对应纵轴值,R语言实现代码如下:
# 基函数:aes绑定条形图横轴纵轴
ggplot(pg_mean, aes(x = group, y = weight)) +
# 条形图函数:stat表明取用样本点对应纵轴值
geom_bar(stat = "identity")
运行效果:
如果觉得灰色调比较难看,可以在条形图函数中指定条形图需要填充的颜色以及条形图的边框颜色。R语言实现代码如下:
# 基函数
ggplot(pg_mean, aes(x = group, y = weight)) +
# 条形图函数:fill设置条形图填充色,colour设置条形图边界颜色
geom_bar(stat = "identity", fill = "lightblue", colour = "black")
运行效果:

要强调的是如果横轴对应数据非离散型,则须先将其转为因子类型,否则结果会出现"空条"。
绘制(簇状)条形图
本例选用测试集如下:
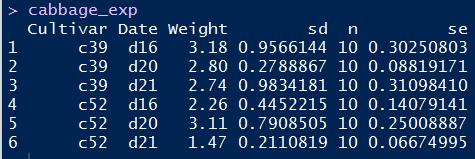
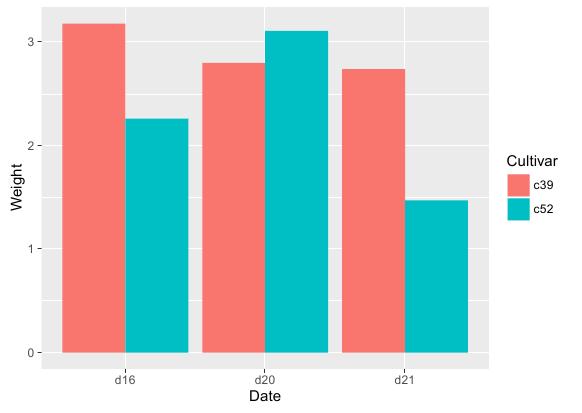
绘制方法是在条形图函数中设置fill参数,将数据集中表示分类的列赋值给它。R语言实现代码如下:
# 基函数:fill绑定"美学特征"
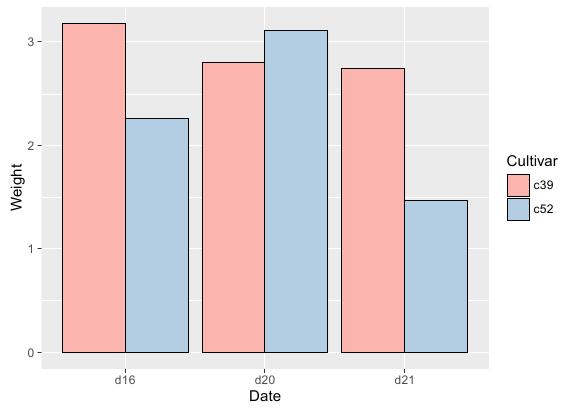
ggplot(cabbage_exp, aes(x = Date, y = Weight, fill = Cultivar)) +
# 条形图函数:position设置条形图类型为簇状
geom_bar(position = "dodge", stat = "identity")
运行效果:
可使用填充标尺函数scale_fill_brewer(palette)重新选择配色,并为条状加上黑色边框。R语言实现代码如下:
# 基函数
ggplot(cabbage_exp, aes(x = Date, y = Weight, fill = Cultivar)) +
# 条形图函数
geom_bar(position = "dodge", stat = "identity", colour = "black") +
# 调色标尺:设置调色板为Pastel1
scale_fill_brewer(palette="Pastel1")
运行效果:
绘制频数条形图
选用测试数据集如下:
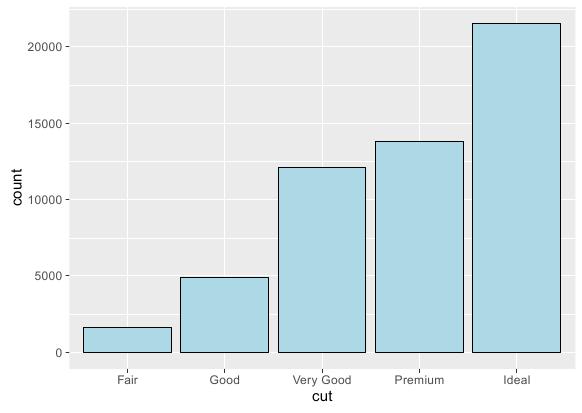
本例需要展示的是不同cut类型变量的样本个数,要实现这点关键在于将stat参数设置为bin。之前将stat设置为identity是直接展示样本点绑定的纵轴值,而设置为bin则会统计样本点落到横轴上各离散值的个数,这种情况下ggplot的aes参数只需绑定横轴。R语言实现代码如下:
# 基函数
ggplot(diamonds, aes(x = cut)) +
# 条形图函数:stat参数默认为bin
geom_bar(fill = "lightblue", colour = "black")
执行效果:
如果横轴是连续变量,那么这张图就会变成直方图。和将来要讲的geom_histogram()函数效果是一样的。
对正负条形图分别着色
本例测试数据集如下:

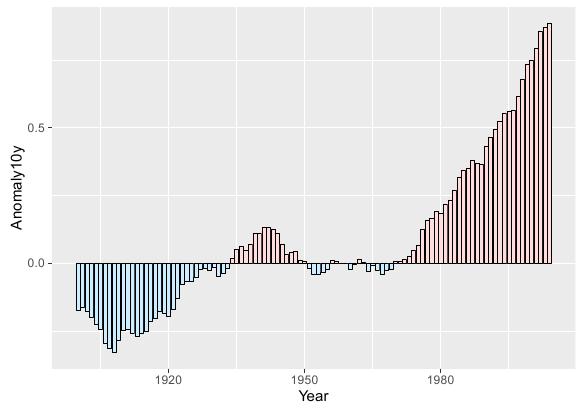
如若现在需要绘制出数据集中Anomaly10y列随时间的变化,同时可视化方面要求做到小于0的用蓝色表示,大于0的用红色表示。
对于这种情况可为数据集创建一个辅助列pos,该列为布尔类型:TRUE表示Anomaly10y属性大于0,而FALSE表示Anomaly10y列小于0。之后原数据集便多了一个pos列,表征Anomaly10y列值大于等于/小于0。然后将这个字段fiil到ggplot函数,再调用标尺函数对配色进行自定义并令guide=FALSE取消图例。R语言实现代码如下:
# 增加辅助列,表示当前记录Anomaly10y值大于/小于0。
csub$pos = csub$Anomaly10y >= 0 # 基函数
ggplot(csub, aes(x = Year, y = Anomaly10y, fill = pos)) +
# 条形图函数:position设置为"identity"是为了避免系统因绘制负值条形而引发的警告
geom_bar(stat = "identity", position = "identity", colour = "black", size = 0.1) +
# 手动调色标尺:大于0为红,小于0为蓝
scale_fill_manual(values = c("#CCEEFF", "#FFDDDD"), guide = FALSE)
运行效果:
绘制(百分比)堆积型条形图
本例测试数据集如下:
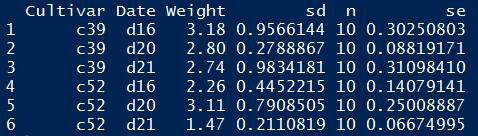
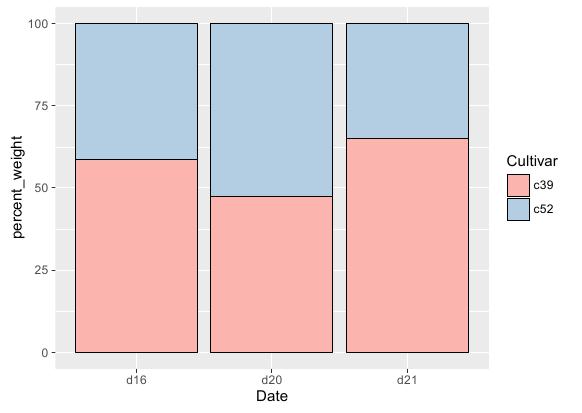
使用ggplot2绘制条形图时,只要不修改geom_bar()函数的position参数,所得条形图便为堆积型。但堆积条形图纵轴大都采用百分比形式,故在具体绘制前,需要对原数据集进行预处理,将纵轴数据转换为分类百分比格式。
本例要统计c39和c52两个品种在不同日期下的重量对比,则需首先将各记录的Weight值除以该记录所在类目的Weight和,然后再将新的百分比列绑定到纵轴。R语言实现代码如下:
# 计算Weight列的分类百分比列
library(plyr)
ce = ddply(cabbage_exp, "Date", transform, percent_weight = Weight / sum(Weight) * 100) # 基函数
ggplot(ce, aes(x = Date, y = percent_weight, fill = Cultivar)) +
# 条形图函数:未将position参数显示设置为dodge,则绘制出的条形图为堆积型
geom_bar(stat = "identity", colour = "black") +
# 调色标尺
scale_fill_brewer(palette = "Pastel1")
运行效果:
添加数据标签
本例测试数据集如下:
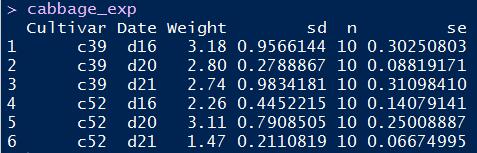
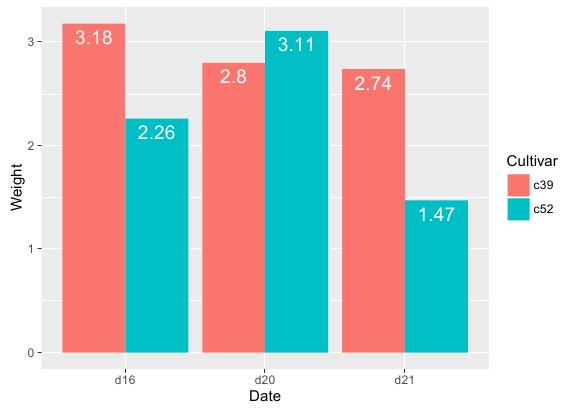
为了给条形图添加标签显示纵轴值,关键在于gemo_text()函数。使用这个函数时,需要在它的aes参数里绑定各样本的横纵坐标,以及要展示的值。
下面首先来展示不同Cultivar分类在不同日期下Weight的对比簇状条形图。R语言实现代码如下:
# 基函数
ggplot(cabbage_exp, aes(x = Date, y = Weight, fill = Cultivar)) +
# 条形图函数
geom_bar(stat = "identity", position = "dodge") +
# 标签函数:label设置展示标签,vjust设置标签偏移(正上负下),position设置各标签的间距
geom_text(aes(label = Weight), vjust = 1.5, colour = "white", position = position_dodge(.9), size = 5)
运行结果:
特别要注意的是geom_text()函数的position参数,绘制簇状图必须通过该参数指定各标签的间距。否则一个簇的所有标签都会堆到同一横轴坐标上,像下面这样:

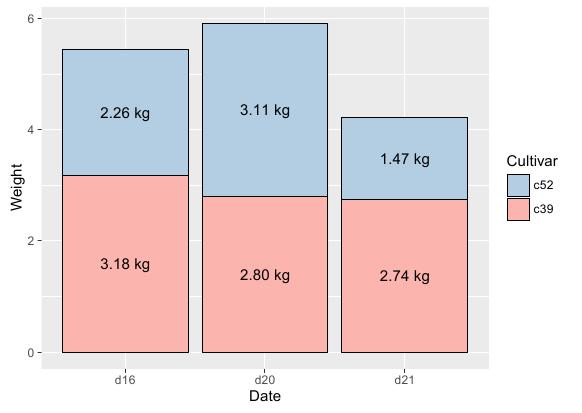
如果要在堆积状的条形图上打标签,则稍微复杂一点。因为要对每组数据进行求和及居中化处理,才能更好的展示出结果。其中关键点在于使用ggplot库提供的ddply方法对分组变量进行汇总求和。具体R语言实现代码如下:
# 根据日期和性别对数据进行排序
ce = arrange(cabbage_exp, Date, Cultivar)
# 对不同Date分组内的数据进行累加求和
ce = ddply(ce, "Date", transform, label_y = cumsum(Weight) - 0.5*Weight) # 基函数
ggplot(ce, aes(x = Date, y = Weight, fill = Cultivar)) +
# 条形图函数
geom_bar(stat = "identity", colour = "black") +
# 标签函数:paste和format方法对标签进行格式化
geom_text(aes(y=label_y, label = paste(format(Weight, nsmall=2), "kg")), size = 4) +
# 图例函数:反转图例
guides(fill = guide_legend(reverse = TRUE)) +
# 调色标尺
scale_fill_brewer(palette = "Pastel1")
运行结果:
第三篇:R语言数据可视化之条形图的更多相关文章
- 最棒的7种R语言数据可视化
最棒的7种R语言数据可视化 随着数据量不断增加,抛开可视化技术讲故事是不可能的.数据可视化是一门将数字转化为有用知识的艺术. R语言编程提供一套建立可视化和展现数据的内置函数和库,让你学习这门艺术.在 ...
- 第四篇:R语言数据可视化之折线图、堆积图、堆积面积图
折线图简介 折线图通常用来对两个连续变量的依存关系进行可视化,其中横轴很多时候是时间轴. 但横轴也不一定是连续型变量,可以是有序的离散型变量. 绘制基本折线图 本例选用如下测试数据集: 绘制方法是首先 ...
- 第一篇:R语言数据可视化概述(基于ggplot2)
前言 ggplot2是R语言最为强大的作图软件包,强于其自成一派的数据可视化理念.当熟悉了ggplot2的基本套路后,数据可视化工作将变得非常轻松而有条理. 本文主要对ggplot2的可视化理念及开发 ...
- 第六篇:R语言数据可视化之数据分布图(直方图、密度曲线、箱线图、等高线、2D密度图)
数据分布图简介 中医上讲看病四诊法为:望闻问切.而数据分析师分析数据的过程也有点相似,我们需要望:看看数据长什么样:闻:仔细分析数据是否合理:问:针对前两步工作搜集到的问题与业务方交流:切:结合业务方 ...
- 第五篇:R语言数据可视化之散点图
散点图简介 散点图通常是用来表述两个连续变量之间的关系,图中的每个点表示目标数据集中的每个样本. 同时散点图中常常还会拟合一些直线,以用来表示某些模型. 绘制基本散点图 本例选用如下测试数据集: 绘制 ...
- 第二篇:R语言数据可视化之数据塑形技术
前言 绘制统计图形时,半数以上的时间会花在调用绘图命令之前的数据塑型操作上.因为在把数据送进绘图函数前,还得将数据框转换为适当格式才行. 本文将给出使用R语言进行数据塑型的一些基本的技巧,更多技术细节 ...
- 吴裕雄--天生自然 R语言数据可视化绘图(3)
par(ask=TRUE) opar <- par(no.readonly=TRUE) # record current settings # Listing 11.1 - A scatter ...
- 吴裕雄--天生自然 R语言数据可视化绘图(4)
par(ask=TRUE) # Basic scatterplot library(ggplot2) ggplot(data=mtcars, aes(x=wt, y=mpg)) + geom_poin ...
- 吴裕雄--天生自然 R语言数据可视化绘图(2)
par(ask=TRUE) opar <- par(no.readonly=TRUE) # save original parameter settings library(vcd) count ...
随机推荐
- Winform控件Enable=false显示优化
在B/S开发中(ASP.NET),往往可以css样式表来让页面控件更加美观,但是在C/S中(Winform)里面,我们则需要通过其他取巧的 方式来实现.例如:当你因为某个需求需要将控件设置为Reado ...
- Unity3d脚本的生命周期
接下来,做出一下讲解:最先执行的方法是Awake,这是生命周期的开始,用于进行激活时的初始化代码,一般可以在这个地方将当前脚本禁用:this.enable=false,如果这样做了,则会直接跳转到On ...
- php基础知识【函数】(8)xml和变量函数
一.XML函数 参数类型 data --string,需要解析的数据集. parser --resource,一个指向要取得字节索引的 XML 解析器的引用. 1.创建和释放XMl解析器 ...
- discuz二次开发技巧
discuz二次开发技巧 二次开发大多时候知识设置和处理,如果能够获知模板文件获得的变量数组将大大提高我们的开发效率 获取页面已经定义的变量 <--{eval printf_r(get_defi ...
- 练习2 C - 成绩转换
Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u Description 输入一个百 ...
- bzoj3541: Spoj59 Bytelandian Information Agency
Description BIA机构内部使用一个包含N台计算机的网络.每台计算机被标号为1..N,并且1号机是服务器.计算机被一些单向传输线连接着,每条数据线连接两台计算机.服务器可以向任 ...
- 转:.NET 环境中使用RabbitMQ
原文来自于:http://blog.jobbole.com/83819/ 原文出处: 寒江独钓 欢迎分享原创到伯乐头条 在企业应用系统领域,会面对不同系统之间的通信.集成与整合,尤其当面临异构系统 ...
- [POJ 1742] Coins 【DP】
题目链接:POJ - 1742 题目大意 现有 n 种不同的硬币,每种的面值为 Vi ,数量为 Ni ,问使用这些硬币共能凑出 [1,m] 范围内的多少种面值. 题目分析 使用一种 O(nm) 的 D ...
- 在InnoDB,记录在 non-clustered indexes(也被称为secondary indexes) 包含了主键值
In InnoDB, the records in non-clustered indexes (also called secondary indexes) contain the primary ...
- 「Poetize4」上帝造题的七分钟2
描述 Description "第一分钟,X说,要有数列,于是便给定了一个正整数数列.第二分钟,L说,要能修改,于是便有了对一段数中每个数都开平方(下取整)的操作.第三分钟,k说,要能查询, ...