自然语言推理:微调BERT
自然语言推理:微调BERT
Natural Language Inference: Fine-Tuning BERT
SNLI数据集上的自然语言推理任务设计了一个基于注意力的体系结构。现在通过微调BERT来重新讨论这个任务。自然语言推理是一个序列级文本对分类问题,而微调BERT只需要额外的基于MLP的架构,如图1所示。
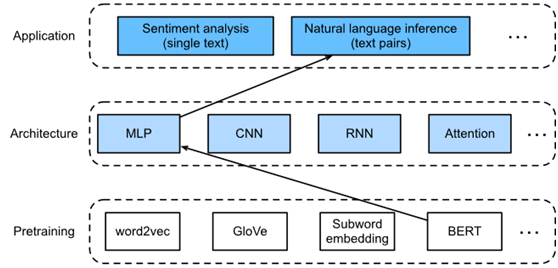
Fig. 1. This section feeds pretrained BERT to an MLP-based architecture for natural language inference.
下载一个经过预训练的小版本BERT,然后对其进行微调,以便在SNLI数据集上进行自然语言推理。
from d2l import mxnet as d2l
import json
import multiprocessing
from mxnet import autograd, gluon, init, np, npx
from mxnet.gluon import nn
import os
npx.set_np()
1. Loading Pretrained BERT
解释了如何在WikiText-2数据集上预训练BERT(注意,原始的BERT模型是在更大的语料库上预训练的)。最初的BERT模型有上亿个参数。提供两个版本的预训练BERT:“bert.base “大约和原始的BERT基模型一样大,需要大量的计算资源进行微调,而“bert.small”是一个小版本,便于演示。
d2l.DATA_HUB['bert.base'] = (d2l.DATA_URL + 'bert.base.zip',
'7b3820b35da691042e5d34c0971ac3edbd80d3f4')
d2l.DATA_HUB['bert.small'] = (d2l.DATA_URL + 'bert.small.zip',
'a4e718a47137ccd1809c9107ab4f5edd317bae2c')
任何一个预训练的BERT模型都包含一个“vocab.json”定义词汇集和“pretrained.params”预训练参数的文件。实现了如下加载预训练模型函数来load_pretrained_model加载预训练的BERT参数。
def load_pretrained_model(pretrained_model, num_hiddens, ffn_num_hiddens,
num_heads, num_layers, dropout, max_len, ctx):
data_dir = d2l.download_extract(pretrained_model)
# Define an empty vocabulary to load the predefined vocabulary
vocab = d2l.Vocab([])
vocab.idx_to_token = json.load(open(os.path.join(data_dir, 'vocab.json')))
vocab.token_to_idx = {token: idx for idx, token in enumerate(
vocab.idx_to_token)}
bert = d2l.BERTModel(len(vocab), num_hiddens, ffn_num_hiddens, num_heads,
num_layers, dropout, max_len)
# Load pretrained BERT parameters
bert.load_parameters(os.path.join(data_dir, 'pretrained.params'), ctx=ctx)
return bert, vocab
为了便于在大多数机器上演示,将加载并微调小版本(“bert.small”)的名称。在练习中,将演示如何微调更大的“bert.base”以显著提高测试精度。
ctx = d2l.try_all_gpus()
bert, vocab = load_pretrained_model(
'bert.small', num_hiddens=256, ffn_num_hiddens=512, num_heads=4,
num_layers=2, dropout=0.1, max_len=512, ctx=ctx)
Downloading ../data/bert.small.zip from http://d2l-data.s3-accelerate.amazonaws.com/bert.small.zip...
2. The Dataset for Fine-Tuning BERT
对于SNLI数据集上的下游任务自然语言推理,定义了一个自定义的数据集类SNLIBERTDataset。在每个例子中,前提和假设形成一对文本序列,并被打包成一个BERT输入序列,如图2所示。段IDs用于区分BERT输入序列中的前提和假设。使用预定义的BERT输入序列的最大长度(max_len),输入文本对中较长的最后一个标记会一直被删除,直到满足max_len。为了加速生成用于微调BERT的SNLI数据集,使用4个worker进程并行地生成训练或测试示例。
class SNLIBERTDataset(gluon.data.Dataset):
def __init__(self, dataset, max_len, vocab=None):
all_premise_hypothesis_tokens = [[
p_tokens, h_tokens] for p_tokens, h_tokens in zip(
*[d2l.tokenize([s.lower() for s in sentences])
for sentences in dataset[:2]])]
self.labels = np.array(dataset[2])
self.vocab = vocab
self.max_len = max_len
(self.all_token_ids, self.all_segments,
self.valid_lens) = self._preprocess(all_premise_hypothesis_tokens)
print('read ' + str(len(self.all_token_ids)) + ' examples')
def _preprocess(self, all_premise_hypothesis_tokens):
pool = multiprocessing.Pool(4) # Use 4 worker processes
out = pool.map(self._mp_worker, all_premise_hypothesis_tokens)
all_token_ids = [
token_ids for token_ids, segments, valid_len in out]
all_segments = [segments for token_ids, segments, valid_len in out]
valid_lens = [valid_len for token_ids, segments, valid_len in out]
return (np.array(all_token_ids, dtype='int32'),
np.array(all_segments, dtype='int32'),
np.array(valid_lens))
def _mp_worker(self, premise_hypothesis_tokens):
p_tokens, h_tokens = premise_hypothesis_tokens
self._truncate_pair_of_tokens(p_tokens, h_tokens)
tokens, segments = d2l.get_tokens_and_segments(p_tokens, h_tokens)
token_ids = self.vocab[tokens] + [self.vocab['<pad>']] \
* (self.max_len - len(tokens))
segments = segments + [0] * (self.max_len - len(segments))
valid_len = len(tokens)
return token_ids, segments, valid_len
def _truncate_pair_of_tokens(self, p_tokens, h_tokens):
# Reserve slots for '<CLS>', '<SEP>', and '<SEP>' tokens for the BERT
# input
while len(p_tokens) + len(h_tokens) > self.max_len - 3:
if len(p_tokens) > len(h_tokens):
p_tokens.pop()
else:
h_tokens.pop()
def __getitem__(self, idx):
return (self.all_token_ids[idx], self.all_segments[idx],
self.valid_lens[idx]), self.labels[idx]
def __len__(self):
return len(self.all_token_ids)
在下载SNLI数据集之后,通过实例化SNLIBERTDataset类来生成训练和测试示例。这些例子将在自然语言推理的训练和测试中分批阅读。
# Reduce `batch_size` if there is an out of memory error. In the original BERT
# model, `max_len` = 512
batch_size, max_len, num_workers = 512, 128, d2l.get_dataloader_workers()
data_dir = d2l.download_extract('SNLI')
train_set = SNLIBERTDataset(d2l.read_snli(data_dir, True), max_len, vocab)
test_set = SNLIBERTDataset(d2l.read_snli(data_dir, False), max_len, vocab)
train_iter = gluon.data.DataLoader(train_set, batch_size, shuffle=True,
num_workers=num_workers)
test_iter = gluon.data.DataLoader(test_set, batch_size,
num_workers=num_workers)
read 549367 examples
read 9824 examples
3. Fine-Tuning BERT
如图2所示,用于自然语言推理的微调BERT只需要由两个完全连接的层组成的额外MLP(参见自隐藏以及自输出在下面的BERTClassifier类中)。这种MLP将编码前提和假设信息的特殊“<cls>”标记的BERT表示转化为自然语言推理的三种输出:蕴涵、矛盾和中性。
class BERTClassifier(nn.Block):
def __init__(self, bert):
super(BERTClassifier, self).__init__()
self.encoder = bert.encoder
self.hidden = bert.hidden
self.output = nn.Dense(3)
def forward(self, inputs):
tokens_X, segments_X, valid_lens_x = inputs
encoded_X = self.encoder(tokens_X, segments_X, valid_lens_x)
return self.output(self.hidden(encoded_X[:, 0, :]))
接下来,将预训练的BERT模型BERT输入BERT分类器实例网络,供下游应用程序使用。在一般的BERT微调实现中,只有输出层的参数附加MLP(net.output)从零开始学习。预训练BERT编码器的所有参数(net.encoder)以及附加MLP的隐藏层(net.hidden)将进行微调。
net = BERTClassifier(bert)
net.output.initialize(ctx=ctx)
MaskLM类和NextSentencePred类在使用的mlp中都有参数。这些参数是预训练BERT模型BERT的一部分,因此也是网络中的一部分。然而,这些参数仅用于计算预训练过程中的隐含语言建模损失和下一句预测损失。这两个损失函数与下游应用的微调无关,因此当对BERT进行微调时,MaskLM和NextSentencePred中使用的MLPs的参数不会更新(过期)。
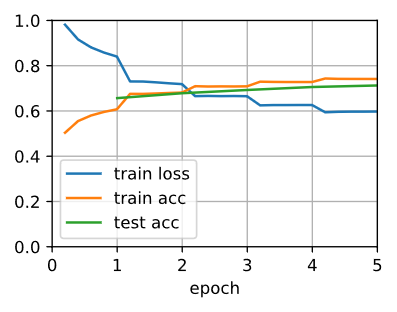
为了允许参数具有过时渐变,在d2l.train_batch_ch13的步进函数中设置标志ignore_stale_grad=True。利用SNLI的训练集(train_iter)和测试集(test_iter)来训练和评估模型网络。由于计算资源有限,训练和测试的准确性还有待进一步提高:将其讨论留在练习中。
lr, num_epochs = 1e-4, 5
trainer = gluon.Trainer(net.collect_params(), 'adam', {'learning_rate': lr})
loss = gluon.loss.SoftmaxCrossEntropyLoss()
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, ctx,
d2l.split_batch_multi_inputs)
loss 0.597, train acc 0.741, test acc 0.713
8563.9 examples/sec on [gpu(0), gpu(1)]
4. Summary
- We can fine-tune the pretrained BERT model for downstream applications, such as natural language inference on the SNLI dataset.
- During fine-tuning, the BERT model becomes part of the model for the downstream application. Parameters that are only related to pretraining loss will not be updated during fine-tuning.
自然语言推理:微调BERT的更多相关文章
- [NLP自然语言处理]谷歌BERT模型深度解析
我的机器学习教程「美团」算法工程师带你入门机器学习 已经开始更新了,欢迎大家订阅~ 任何关于算法.编程.AI行业知识或博客内容的问题,可以随时扫码关注公众号「图灵的猫」,加入”学习小组“,沙雕博主 ...
- 美团:WSDM Cup 2019自然语言推理任务获奖解题思路
WSDM(Web Search and Data Mining,读音为Wisdom)是业界公认的高质量学术会议,注重前沿技术在工业界的落地应用,与SIGIR一起被称为信息检索领域的Top2. 刚刚在墨 ...
- 微调BERT:序列级和令牌级应用程序
微调BERT:序列级和令牌级应用程序 Fine-Tuning BERT for Sequence-Level and Token-Level Applications 为自然语言处理应用程序设计了不同 ...
- 《Enhanced LSTM for Natural Language Inference》(自然语言推理)
解决的问题 自然语言推理,判断a是否可以推理出b.简单讲就是判断2个句子ab是否有相同的含义. 方法 我们的自然语言推理网络由以下部分组成:输入编码(Input Encoding ),局部推理模型(L ...
- <A Decomposable Attention Model for Natural Language Inference>(自然语言推理)
http://www.xue63.com/toutiaojy/20180327G0DXP000.html 本文提出一种简单的自然语言推理任务下的神经网络结构,利用注意力机制(Attention Mec ...
- Textual Entailment(自然语言推理-文本蕴含) - AllenNLP
自然语言推理是NLP高级别的任务之一,不过自然语言推理包含的内容比较多,机器阅读,问答系统和对话等本质上都属于自然语言推理.最近在看AllenNLP包的时候,里面有个模块:文本蕴含任务(text en ...
- 【学习笔记】B站-2019-NLP(自然语言处理)之 BERT 课程 -- 相关课程笔记
BERT 课程笔记 1. 传统方案遇到的问题 BERT的核心在于Transformer,Transformer就类似seq2seq网络输入输出之间的网络结构. 传统的RNN网络:最大的问题,因为不能并 ...
- 用NVIDIA-NGC对BERT进行训练和微调
用NVIDIA-NGC对BERT进行训练和微调 Training and Fine-tuning BERT Using NVIDIA NGC 想象一下一个比人类更能理解语言的人工智能程序.想象一下为定 ...
- 基于TensorRT的BERT实时自然语言理解(下)
基于TensorRT的BERT实时自然语言理解(下) BERT Inference with TensorRT 请参阅Python脚本bert_inference.py还有详细的Jupyter not ...
随机推荐
- IPS入侵防御系统
目录 IPS入侵防御系统 如何才能更好的防御入侵 IPS与IDS的区别 IDS与IPS的部署 IPS独立部署 IPS分布式部署 IPS入侵防御系统 IPS(Intrusion Prevention S ...
- Linux下抓包命令tcpdump的使用
在linux下,可以使用 tcpdump 命令来抓取数据包. 主要用法如下: 过滤网卡 tcpdump -i eth0 #抓取所有经过网卡eth0数据包 tcpdump -i lo #抓取环回口的数据 ...
- RDPInception攻击手法
在讲RDPInception攻击手段之前,我们先了解一下RDP远程桌面(Remote Desktop Protocol)协议.RDP远程桌面协议(Remote Desktop Protocol)是一个 ...
- HTTP自定义Header-(SOCKET-TCP)
HTTP自定义Header-TCP 前几天弄一些东西,需要在发送http请求的时候自定义http头,找了几个库用着很不爽.有的把Cookie直接干掉了,还自己在头里加了版权,最后终于忍不了了.在网 ...
- android之Tween Animation
android Tween Animation有四种,AlphaAnimation(透明度动画).ScaleAnimation(尺寸伸缩动画).TranslateAnimation(位移动画).Rot ...
- vue 2.9.6升级到最新版本
在看文档https://cli.vuejs.org/zh/guide/installation.html中,按步骤升级vue: 于是就先通过 npm uninstall vue-cli -g卸载vue ...
- 使用花生壳、瑞友天翼远程访问金蝶K3
金蝶版本号 WISE15.1 瑞友6.0系列 花生壳5 金蝶软件无法通过外网直接访问 因此需要使用瑞友天翼来实现远程访问 一般来说 金蝶服务器固定了IP地址以后 通过路由器开房两个外网端口即可实现瑞友 ...
- Docker系列——Grafana+Prometheus+Node-exporter服务器监控平台(一)
在最近的博文中,都是介绍监控平台的搭建,其实并不难,主要是需要自己动手操作,实践一番就会了. 有天在想,云上的服务器,是不是也可以搭建一个监控平台,所以就捣鼓了一下,不过遗憾的是,使用阿里云开源的插件 ...
- Spring Cloud Alibaba Nacos Discovery 实战
Nacos 作为服务注册中心,可以快速简单的将服务自动注册到 Nacos 服务端,并且能够动态无感知的刷新某个服务实例的服务列表,为分布式系统提供服务注册与发现功能 一.创建服务 1.创建项目 pom ...
- 适用于windows10 Linux子系统的安装管理配置 How To Management Windows Subsystem for Linux WSL
什么是WSL Windows Subsystem for Linux 简称WLS,适用于Linux的Windows子系统,可以直接在Windows上运行Linux环境(包括大部分命令行工具) Linu ...