Python+Requests+Re(正则)爬取某糗事百科图片(数据分析一)
1、博客目前在学习爬虫课程,使用正则表达式来爬取网页的图片信息
2、下面我们一起来回归下Python中的正则使用方式/方法
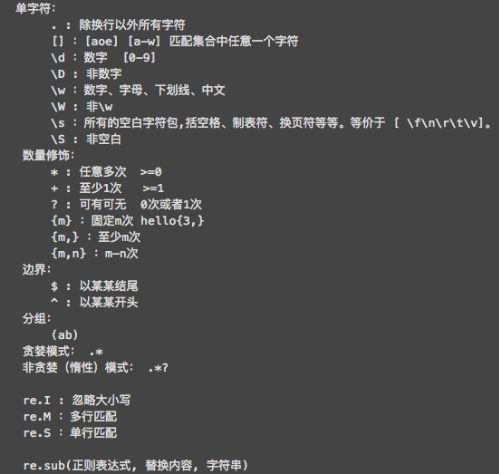
3、糗事百科图片爬取源码如下:
import requests
import re
import os
if __name__ == '__main__':
# headers请求头信息
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
}
# 新建文件夹用来存储糗事图片
if not os.path.exists('./qiushiLibs'):
os.makedirs('./qiushiLibs')
# Url进行封装循环分页爬取
url = 'https://www.qiushibaike.com/imgrank/page/%d/'
for page in range(1,2):
new_url = format(url%page)
# 调用get请求获取text字符串
page_source = requests.get(url=new_url,headers=headers).text
# 正则表达式:使用到非贪婪模式
ER = r'<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
# 返回list数组
img_src_list = re.findall(ER,page_source,re.S)
for src in img_src_list:
# 遍历拼接图片URL
src = 'https:'+src
# 下载图片新建请求
# 以二进制流的方式存储
img_content = requests.get(url=src,headers=headers).content
# print(img_content)
# 生成图片的名称
imgName = src.split('/')[-1]
# 图片路径
imgPath = './qiushiLibs/'+imgName
# 持久化存储
with open(imgPath,'wb') as fp:
fp.write(img_content)
print(imgName,'下载成功!!!')
Python+Requests+Re(正则)爬取某糗事百科图片(数据分析一)的更多相关文章
- 初识python 之 爬虫:爬取某网站的壁纸图片
用到的主要知识点:requests.get 获取网页HTMLetree.HTML 使用lxml解析器解析网页xpath 使用xpath获取网页标签信息.图片地址request.urlretrieve ...
- [Python]网络爬虫(八):糗事百科的网络爬虫(v0.2)源码及解析
转自:http://blog.csdn.net/pleasecallmewhy/article/details/8932310 项目内容: 用Python写的糗事百科的网络爬虫. 使用方法: 新建一个 ...
- python+正则+多进程爬取糗事百科图片
话不多说,直接上代码: # 需要的库 import requests import re import os from multiprocessing import Pool # 请求头 header ...
- python requests库网页爬取小实例:百度/360搜索关键词提交
百度/360搜索关键词提交全代码: #百度/360搜索关键词提交import requestskeyword='Python'try: #百度关键字 # kv={'wd':keyword} #360关 ...
- Python Requests库网络爬取全代码
#爬取京东商品全代码 import requestsurl = "http://item.jd.com/2967929.html"try: r = requests.get(url ...
- python requests库网页爬取小实例:亚马逊商品页面的爬取
由于直接通过requests.get()方法去爬取网页,它的头部信息的user-agent显示的是python-requests/2.21.0,所以亚马逊网站可能会拒绝访问.所以我们要更改访问的头部信 ...
- python Requests库网络爬取IP地址归属地的自动查询
#IP地址查询全代码import requestsurl = "http://m.ip138.com/ip.asp?ip="try: r = requests.get(url + ...
- python+BeautifulSoup+多进程爬取糗事百科图片
用到的库: import requests import os from bs4 import BeautifulSoup import time from multiprocessing impor ...
- 【Python】python3 正则爬取网页输出中文乱码解决
爬取网页时候print输出的时候有中文输出乱码 例如: \\xe4\\xb8\\xad\\xe5\\x8d\\x8e\\xe4\\xb9\\xa6\\xe5\\xb1\\x80 #爬取https:// ...
随机推荐
- PyTorch 图像分类
PyTorch 图像分类 如何定义神经网络,计算损失值和网络里权重的更新. 应该怎么处理数据? 通常来说,处理图像,文本,语音或者视频数据时,可以使用标准 python 包将数据加载成 numpy 数 ...
- 特斯拉Tesla Model 3整体架构解析(上)
特斯拉Tesla Model 3整体架构解析(上) 一辆特斯拉 Model 3型车在硬件改造后解体 Sensors for ADAS applications 特斯拉 Model 3型设计的传感器组件 ...
- CSS 常见问题笔记
CSS 常见问题 布局 一.盒模型宽度计算 问题:div1 的 offsetWidth 是多少? <style> #div1 { width: 100px; padding: 10px; ...
- 1、java数据结构和算法---循环队列
直接上代码: public class CircleArrayQueueLvcai { private int[] array; private int maxSize;//循环队列大小 privat ...
- 1-3. SpringBoot基础,Java配置(全注解配置)取代xml配置
最近突发奇想,整合一下以前一些学习笔记,分享自己这几年爬过的坑,逐步更新文章,谢谢大家的关注和支持. 这节讲一下SpringBoot的学习必须的一些基础,Java配置.其实在Spring2.0时代就已 ...
- 狂神说redis笔记(三)
八.Redis.conf 容量单位不区分大小写,G和GB有区别 可以使用 include 组合多个配置问题 网络配置 日志 # 日志 # Specify the server verbosity le ...
- mybatis学习——properties属性实现引用配置文件
Mybatis核心配置文件中有很多的配置项,配置文档的顶层结构如下: *注意:配置项的顺序不能颠倒,如果颠倒了它们的顺序,在MyBatis的自启动阶段会发生异常,导致程序无法运行. propertie ...
- 【NX二次开发】Block UI 指定轴
属性说明 属性 类型 描述 常规 BlockID String 控件ID Enable Logical 是否可操作 Group ...
- 【NX二次开发】获取指定矩阵标识的矩阵值
函数:UF_CSYS_ask_matrix_values () 函数说明:获取指定矩阵标识的矩阵值. 用法: #include <uf.h> #include <uf_csys.h& ...
- 带你从头到尾捋一遍MySQL索引结构
索性这次把数据库中最核心的也是最难搞懂的内容,也就是索引,分享给大家. 这篇博客我会谈谈对于索引结构我自己的看法,以及分享如何从零开始一层一层向上最终理解索引结构. 从一个简单的表开始 create ...