2017数据科学报告:机器学习工程师年薪最高,Python最常用
2017数据科学报告:机器学习工程师年薪最高,Python最常用

数据平台 Kaggle 近日发布了2017 机器学习及数据科学调查报告,针对最受欢迎的编程语言、不同国家数据科学家的平均年龄、不同国家的平均年薪等进行深度调查。此次调查共收到16000余份回复。
以下「AI脑力波」小编对该报告数据进行了梳理编译,供大家参考。
年龄
从全球范围来看,本次调查对象的平均年龄在30岁左右。在不同的国家,数值会有所差异,加拿大接受问卷调查的平均年龄为34岁,而中国的机器学习从业者年龄的中位数是25岁。
工作状态
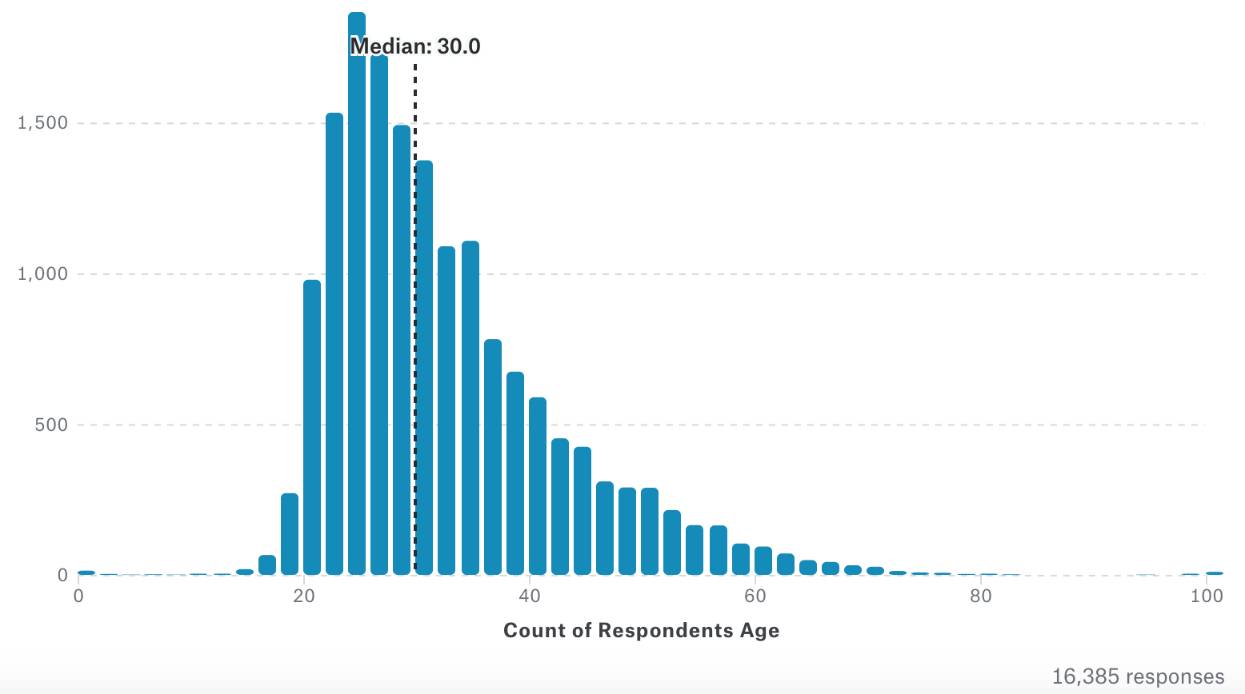
全球全职工作者为 65.7% ,其中中国为 53.% ,美国占比较高,达70.9%。
职位
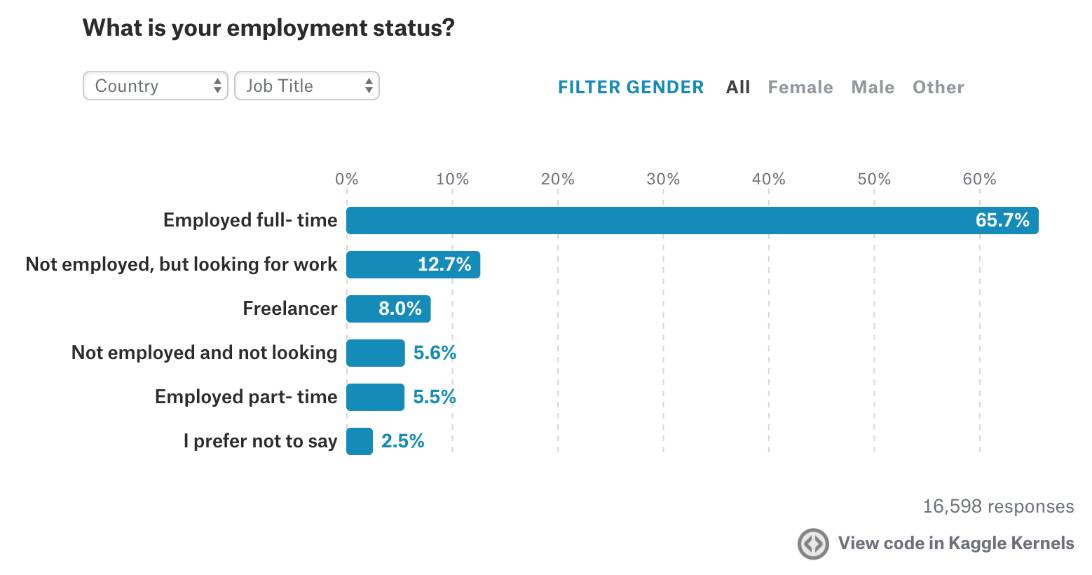
数据科学领域可涵盖的工作非常多,包括机器学习工程师、数据分析师、数据科学家、软件开发人员、数据挖掘人员等。其中,数据科学家人数占比最高,达24.4%。软件开发人员/工程师位居第二,但人数仅占12.3%,数据分析师紧跟其后,以11.3%位列第三。
年薪
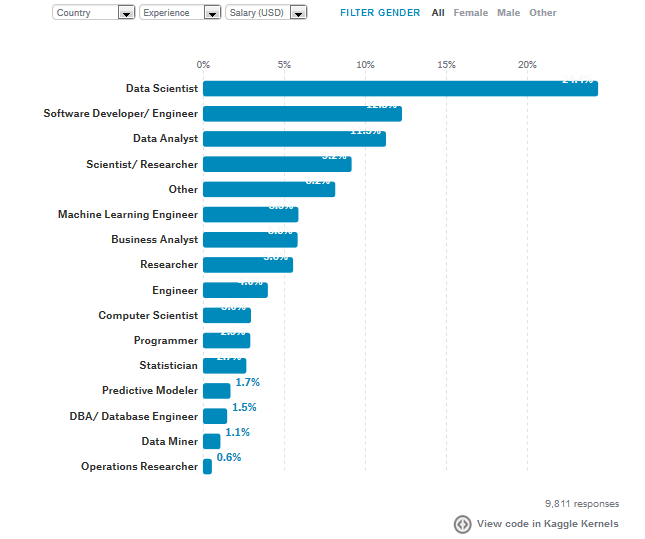
从全球来看,人们普遍认为“职业进修机会”比“薪酬福利”要更重要一些。数据科学人员的年薪中位数为$55,441。在中国,数据科学家的年薪中位数为$29,835。美国则高达$110,000。
最高学历
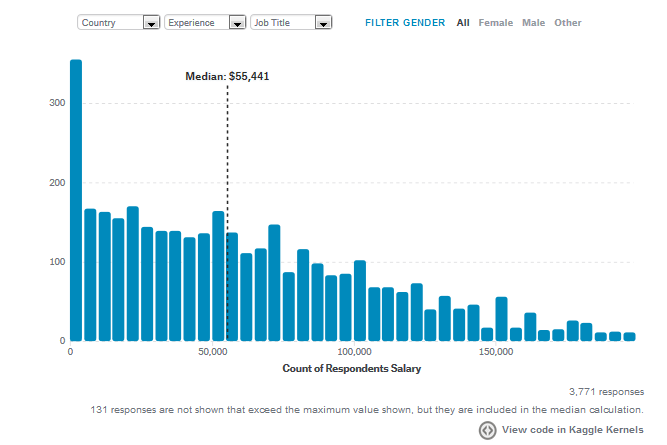
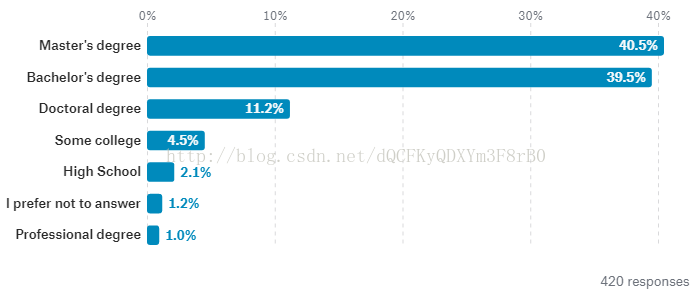
通常来讲,数据科学从业者中最普遍的学历是硕士,但一般来讲,博士学位能拿到($150K - $200K 和 $200k+)高薪。
就中国而言,硕士学位在总体占比为40.5%,博士仅11.2%,本科学位从业人数则高达39.5%,与硕士从业人数持平。
而美国,硕士学位只有44.5%,博士学位高达20.7%,本科从业者占比也高达26.5%。
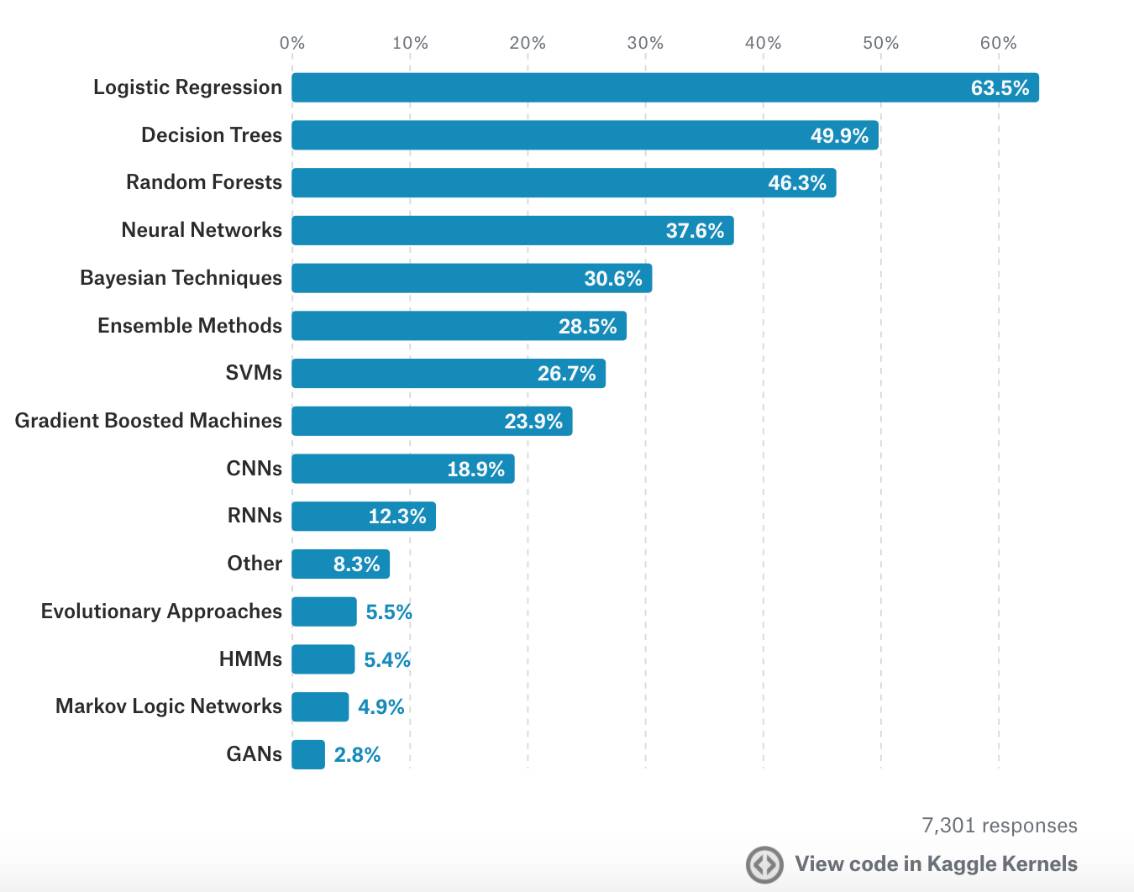
数据科学研究方法
在军事和国安领域外,Logistic回归是最常用的数据科学研究方法。在军事和国防安全领域,神经网络被使用更多。
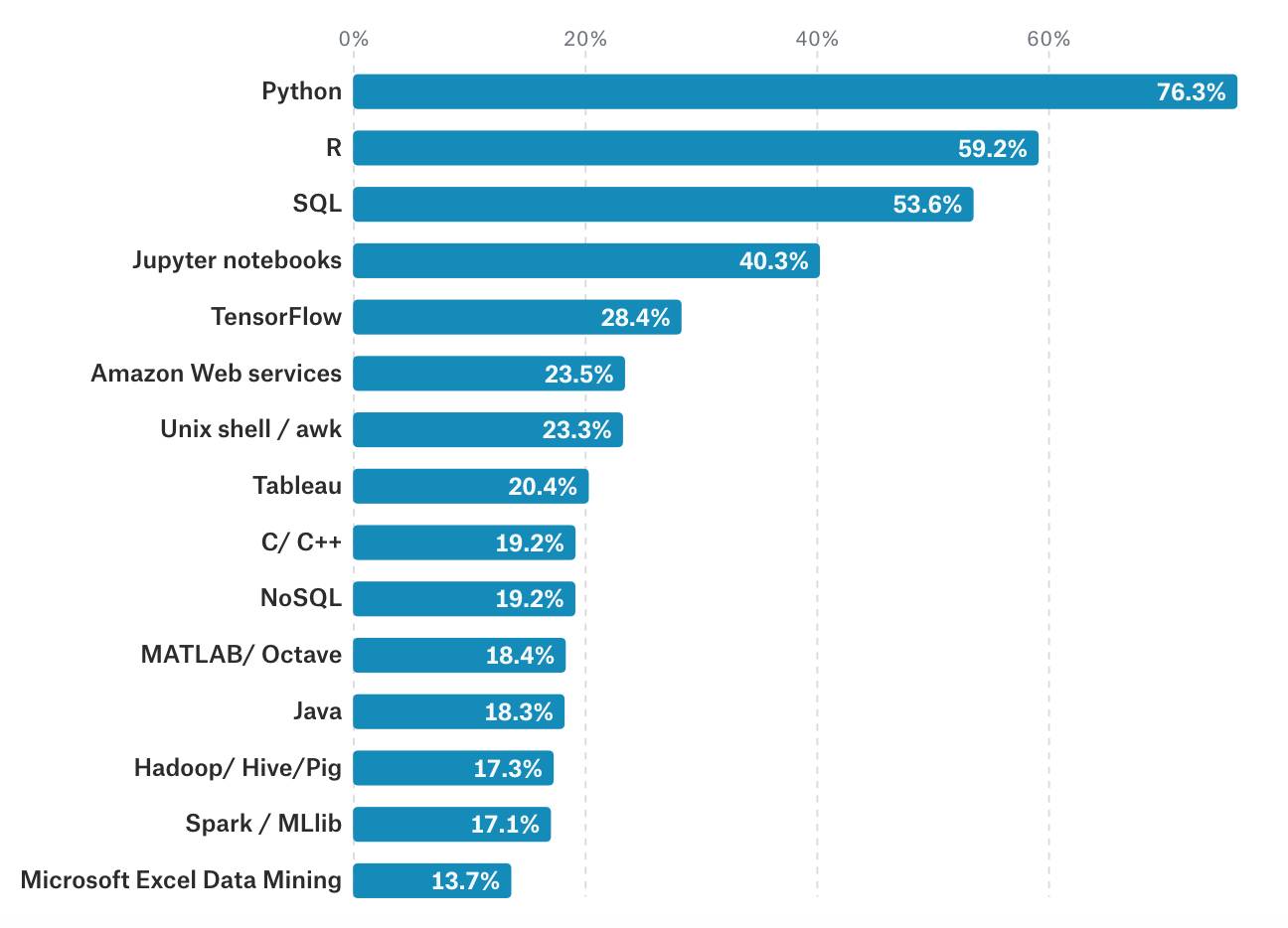
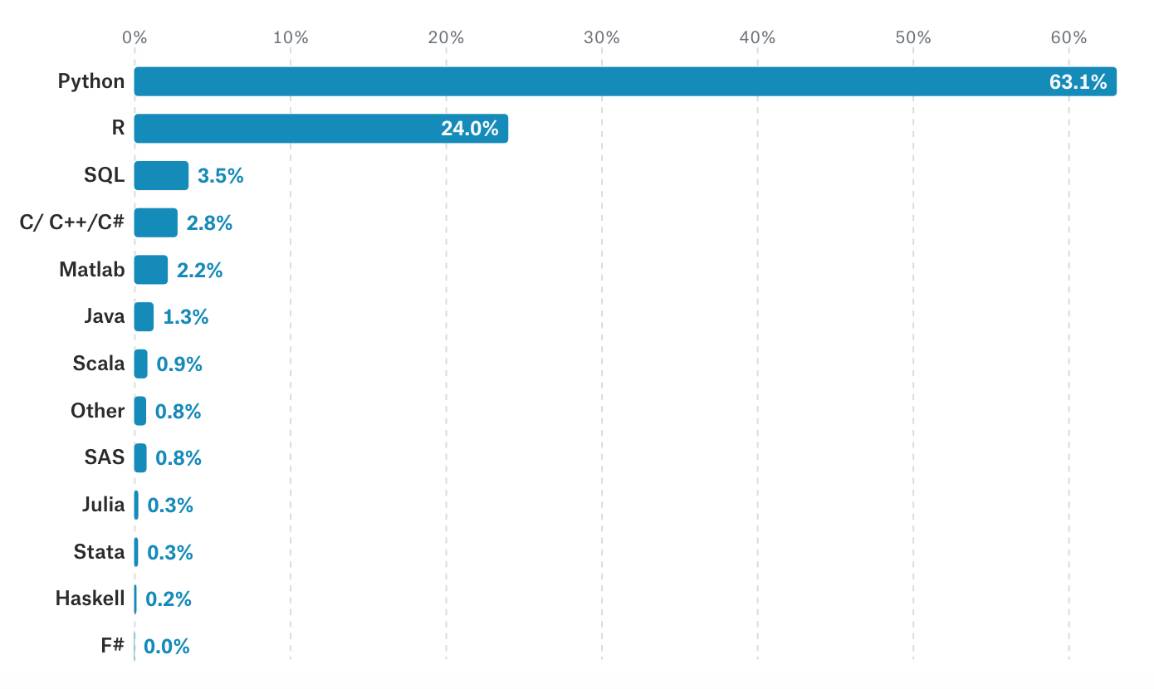
在工具语言使用方面,Python是数据科学家使用最多的语言。同时,统计学家对 R 语言的忠诚度很高。
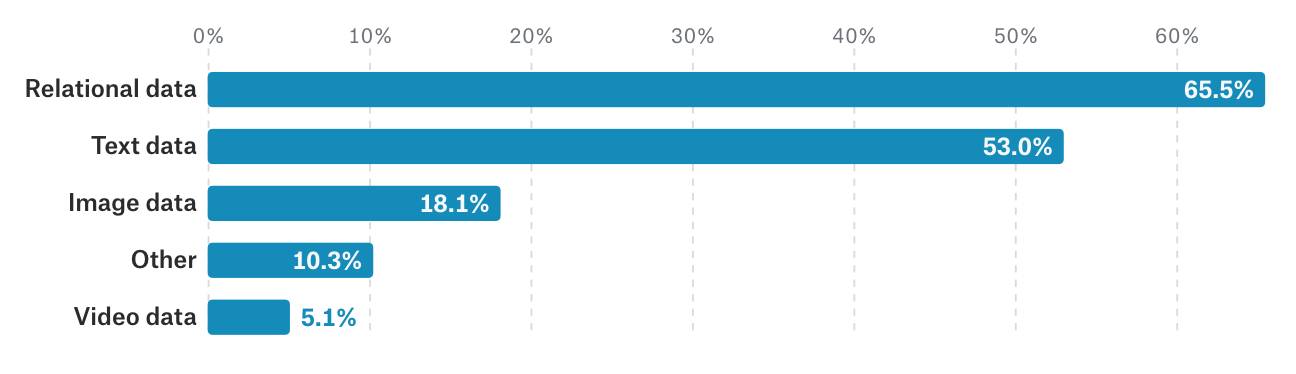
关系型数据是最常用的数据类型,学术研究者和国防安全领域则更亲睐文本和图像。
Git 是他们最常用的代码共享和托管方式。
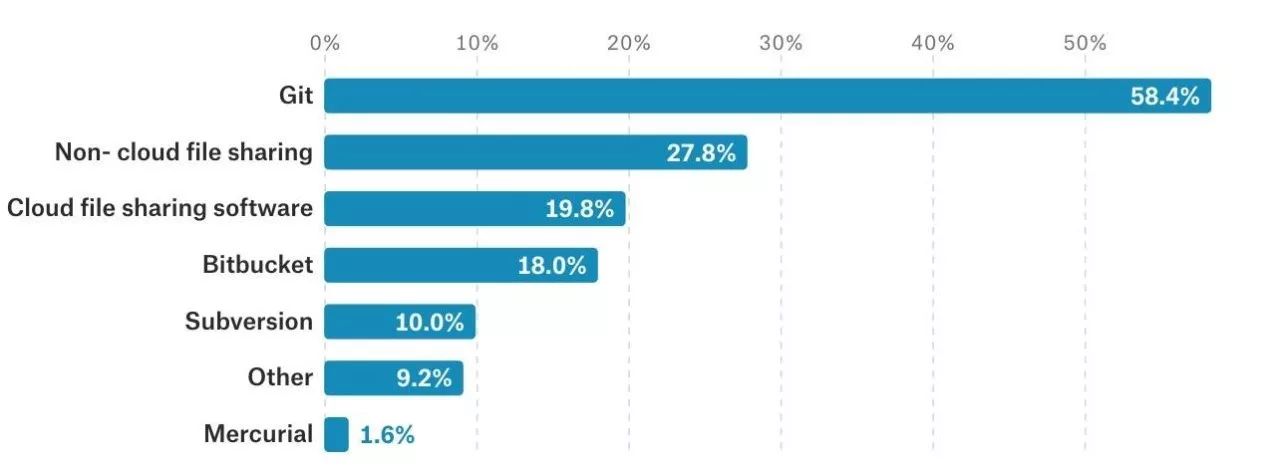
Dirty Data (脏数据)是从业者遇到的最大障碍。此外,理解不同算法的能力不够也是困扰数据工作者的一大障碍。缺乏有效管理和资金支持,是面临的两大外在困境。
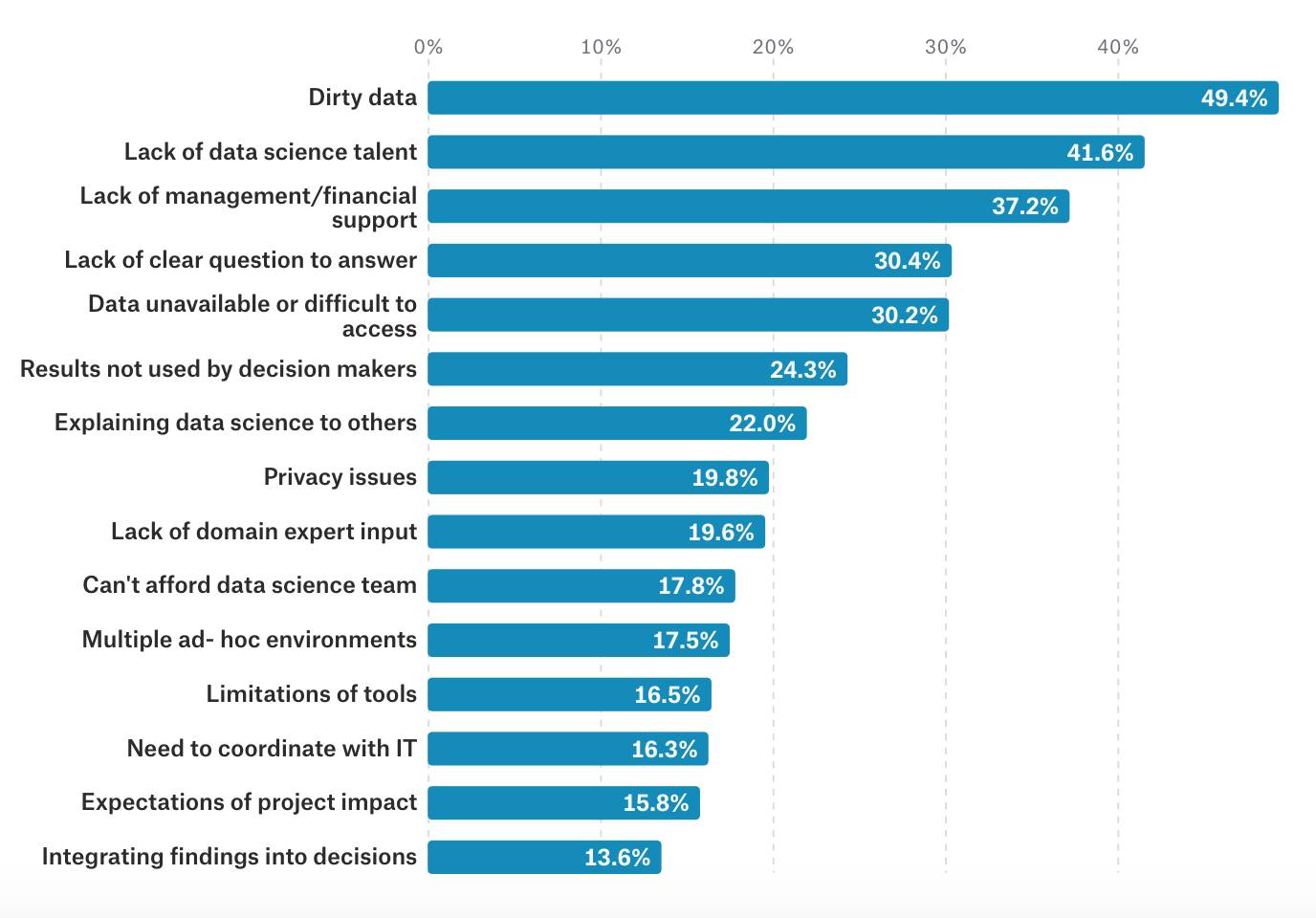
有趣的是,只使用 Python 或只使用 R 的都觉得他们做出了正确的选择。 但是,如果你去询问那些既使用 Python 也使用 R 的人,推荐使用 Python 的可能会是 R 的两倍。
数据科学是个变化极快的领域,业内人员需要不断更新知识体系,才可以在业内保持一定地位,不被时代淘汰。Stack Overflow Q&A、Conferences 和 Podcasts 是已从业者经常使用的学习平台。

开放型数据源
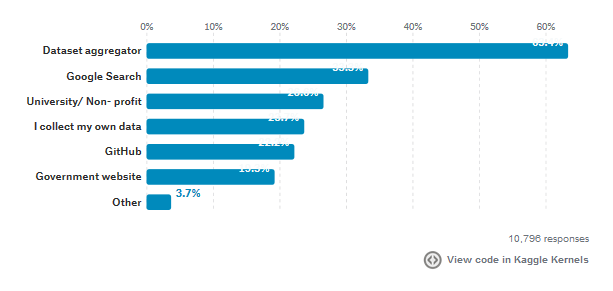
没有数据就没有数据科学。因此,数据科学家了解如何才能找到干净的开放型数据,用于实践和项目十分重要。据调查显示,数据聚合平台是人们最常用获取数据的途径,其次是谷歌。
(以上图片全部来自:https://www.kaggle.com/surveys/2017)
2017数据科学报告:机器学习工程师年薪最高,Python最常用的更多相关文章
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札80)用Python编写小工具下载OSM路网数据
本文对应脚本已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们平时在数据可视化或空间数据分析的过程中经常会 ...
- 数据科学VS机器学习
数据科学是一个范围很广的学科.机器学习和统计学都是数据科学的一部分.机器学习中的学习一词表示算法依赖于一些数据(被用作训练集)来调整模型或算法的参数.这包含了许多的技术,比如回归.朴素贝叶斯或监督聚类 ...
- Python数据科学手册-机器学习:朴素贝叶斯分类
朴素贝叶斯模型 朴素贝叶斯模型是一组非常简单快速的分类方法,通常适用于维度非常高的数据集.因为运行速度快,可调参数少.是一个快速粗糙的分类基本方案. naive Bayes classifiers 贝 ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- Python数据科学手册-机器学习介绍
机器学习分为俩类: 有监督学习 supervised learning 和 无监督学习 unsupervised learning 有监督学习: 对数据的若干特征与若干标签之间 的关联性 进行建模的过 ...
- Python数据科学手册-机器学习: k-means聚类/高斯混合模型
前面学习的无监督学习模型:降维 另一种无监督学习模型:聚类算法. 聚类算法直接冲数据的内在性质中学习最优的划分结果或者确定离散标签类型. 最简单最容易理解的聚类算法可能是 k-means聚类算法了. ...
- Python数据科学手册-机器学习: 流形学习
PCA对非线性的数据集处理效果不太好. 另一种方法 流形学习 manifold learning 是一种无监督评估器,试图将一个低维度流形嵌入到一个高纬度 空间来描述数据集 . 类似 一张纸 (二维) ...
随机推荐
- 【ABAP系列】SAP ABAP 生成随机数的函数
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[MM系列]SAP ABAP 生成随机数的函数 ...
- oracle--表空间处理
CREATE TABLESPACE命令详解(转) 表空间理解 https://www.cnblogs.com/kerrycode/p/3418694.html 常用操作 https://www.cnb ...
- Hibernate异常:MappingException
异常信息: org.hibernate.MappingException: Unknown entity: com.geore.pojo.customer.Customer 造成原因: Mapping ...
- python程序daemon化
1 直接空格加& python flask_server.py & 最简单的方式 这样还不行,不知道为什么flask server会自动退出. $ nohup python flask ...
- HDFS中DataNode工作机制
1.DataNode工作机制 1)一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据(包括数据块的长度,块数据的校验和,以及时间戳). 2)DataNod ...
- [HNOI2016]树(可持久化线段树+树上倍增)
[HNOI2016]树(可持久化线段树+树上倍增) 题面 给出一棵n个点的模板树和大树,根为1,初始的时候大树和模板树相同.接下来操作m次,每次从模板树里取出一棵子树,把它作为新树里节点y的儿子.操作 ...
- Codeforces 979D (STL set)(不用Trie简单AC)
题面: 传送门 题目大意: 给定一个空集合,有两种操作: 一种是往集合中插入一个元素x,一种是给三个数x,k,s,问集合中是否存在v,使得gcd(x,v)%k==0,且x+v<=s若存在多个满足 ...
- django 开发中数据库做过什么优化??
1.设计表时,尽量少使用外键,因为外键约束会影响插入和删除性能: 2.使用缓存,减少对数据库的访问: 3.在 orm 框架下设置表时,能用 varchar 确定字段长度时,就别用 text: 4.可以 ...
- python学习第五十天shutil模块的用法
什么shutil模块,就是对高级的文件,文件夹,压缩包进行处理的模块,下面简单讲述其用法. 文件和文件夹的操作 拷贝文件内容 import shutil shutil.copyfileobj(open ...
- 从0构建webpack开发环境(一) 一个简单webpack.config.js
本文基于webpack4.X,使用的包管理工具是yarn 概念相关就不搬运了,直接开始 首先项目初始化 mkdir webpack-demo && cd webpack-demo ya ...