[CVPR2017] Visual Translation Embedding Network for Visual Relation Detection 论文笔记
http://www.ee.columbia.edu/ln/dvmm/publications/17/zhang2017visual.pdf
Visual Translation Embedding Network for Visual Relation Detection Hanwang Zhang† , Zawlin Kyaw‡ , Shih-Fu Chang† , Tat-Seng Chua‡ †Columbia University, ‡National University of Singapore
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 15.0px Arial; color: #323333 }
p.p2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px Arial; color: #323333 }
p.p3 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px Arial; color: #323333; min-height: 15.0px }
li.li2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px Arial; color: #323333 }
span.s1 { }
ul.ul1 { list-style-type: disc }
ul.ul2 { list-style-type: circle }
ul.ul3 { list-style-type: square }
亮点
- 视觉关系预测问题的分析与化简:把一种视觉关系理解为在特征空间从主语到宾语的一种变换,很有效、很直白
- 实验设计的很棒,从多角度进行了分析对比:语言空间划分,多任务对物体检测的提升,零次学习等。
现有工作
- Mature visual detection [16, 35]
- Burgeoning visual captioning and question answering [2, 4]
- directly bridge the visual model (e.g., CNN) and the language model (e.g., RNN), but fall short in modeling and understanding the relationships between objects.
- poor generalization ability
- Visual Relation Detection: a visual relation as a subject-predicate-object triplet
- joint models, a relation triplet is considered as a unique class [3, 9, 33, 37].
- the long-tailed distribution is an inherent defect for scalability.
- separate model
- modeling the large visual variance of predicates is challenging.
- language priors to boost relation detection
主要思想
Translation Embedding 视觉关系预测的难点主要是:对于N个物体和R种谓语,有N^2R种关系,是一个组合爆炸问题。解决这个问题常用的办法是:
- 估计谓语,不估计关系,缺点:对于不同的主语、宾语,图像视觉差异巨大
受Translation Embedding (TransE) 启发,文章中将视觉关系看作在特征空间上从主语到宾语的一种映射,在低维空间上关系元组可看作向量变换,例如person+ride ≈ bike.
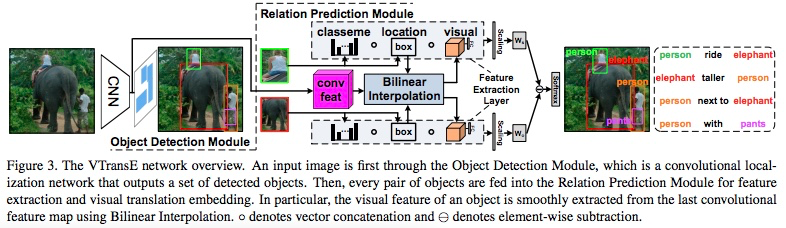
Knowledge Transfer in Relation 物体的识别和谓语的识别是互惠的。通过使用类别名、位置、视觉特征三种特征和端对端训练网络,使物体和谓语之前的隐含关系在网络中能够学习到。
算法
Visual Translation Embedding

p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px Arial; color: #323333 }
span.s1 { }
Loss function

p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px Arial; color: #323333 }
p.p2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px Arial; color: #323333; min-height: 16.0px }
span.s1 { }
Feature Extraction Layer
classname + location + visual feature 不同的特征对不同的谓语(动词、介词、空间位置、对比)都有不一样的作用
Bilinear Interpolation
In order to achieve object-relation knowledge transfer, the relation error should be back-propagated to the object detection network and thus refines the objects. We replace the RoI pooling layer with bilinear interpolation [18]. It is a smooth function of two inputs:

p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 16.0px Arial; color: #323333 }
p.p2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px Arial; color: #323333 }
li.li2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px Arial; color: #323333 }
span.s1 { }
ul.ul1 { list-style-type: disc }
结果
Translation embeding: +18%
object detection +0.6% ~ 0.3%
State-of-art:
- Phrase Det. +3% ~ 6%
- Relation Det. +1%
- Retrieval -1% ~ 2%
- Zero-shot phrase detection
- Phrase Det. -0.7% (without language prior)
- Relation Det. -1.4%
- Retrieval +0.2%
问题
- 两个物体之间可能有多种关系,比如person ride elephant,同时也存在person short elephant但是文章中的方法无法表示多样化的关系
- 没有使用语言先验知识,使用多模态信息可能会有所提升
[CVPR2017] Visual Translation Embedding Network for Visual Relation Detection 论文笔记的更多相关文章
- [CVPR2017] Deep Self-Taught Learning for Weakly Supervised Object Localization 论文笔记
http://openaccess.thecvf.com/content_cvpr_2017/papers/Jie_Deep_Self-Taught_Learning_CVPR_2017_paper. ...
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
- 谣言检测()《Data Fusion Oriented Graph Convolution Network Model for Rumor Detection》
论文信息 论文标题:Data Fusion Oriented Graph Convolution Network Model for Rumor Detection论文作者:Erxue Min, Yu ...
- 论文笔记: Dual Deep Network for Visual Tracking
论文笔记: Dual Deep Network for Visual Tracking 2017-10-17 21:57:08 先来看文章的流程吧 ... 可以看到,作者所总结的三个点在于: 1. ...
- 论文笔记:Visual Semantic Navigation Using Scene Priors
Visual Semantic Navigation Using Scene Priors 2018-10-21 19:39:26 Paper: https://arxiv.org/pdf/1810 ...
- Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记 arXiv 摘要:本文提出了一种 DRL 算法进行单目标跟踪 ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- 论文速读(Jiaming Liu——【2019】Detecting Text in the Wild with Deep Character Embedding Network )
Jiaming Liu--[2019]Detecting Text in the Wild with Deep Character Embedding Network 论文 Jiaming Liu-- ...
- 论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning 2017-06-06 21: ...
随机推荐
- unity shaderlab Blend操作
原文链接: http://www.tiankengblog.com/?p=84 Blend混合操作是作用于在所有计算之后,是Shader渲染的最后一步,进行Blend操作后就可以显示在屏幕上.shad ...
- 【翻译】在Ext JS 5应用程序中如何使用路由
原文:How to Use Routing in Your Ext JS 5 Apps 简介 Ext JS 5是一个重要的发布版本,它提供了许多新特性来创建丰富的.企业级的Web应用程序.MVVM和双 ...
- 使用MD5加密的登陆demo
最近接手了之前的一个项目,在看里面登陆模块的时候,遇到了一堆问题.现在记录下来. 这个登陆模块的逻辑是这样的 1 首先在登陆之前,调用后台的UserLoginAction类的getRandomKey方 ...
- react-native-android之初次相识
作为一名Android开发者,我的感觉就是,一步一卡,卡的潇洒. 但是我还是要学react-native,不要问我为什么,因为我相信一门解决了原生app,开发周期长,开发成本高,升级代价大的语言一定会 ...
- FFmpeg 2.1 试用(新版支持HEVC,VP9)
前两天帮一位老师转码图像的时候,无意间发现新版FFmpeg竟然支持了下一代编码标准HEVC,以及Google提出的下一代编码标准VP9.真心没想到FFmpeg对下一代的编码标准支持的是如此之快.我还以 ...
- adb shell后出现error解决方案
解决办法: 解决办法: 1.adb kill-server 2.adb start-server 3.adb remount 4.adb shell 一般情况下都可以在此启动adb相关
- Android特效专辑(十)——点击水波纹效果实现,逻辑清晰实现简单
Android特效专辑(十)--点击水波纹效果实现,逻辑清晰实现简单 这次做的东西呢,和上篇有点类似,就是用比较简单的逻辑思路去实现一些比较好玩的特效,最近也是比较忙,所以博客更新的速度还得看时间去推 ...
- OpenCV鼠标画图例程,鼠标绘制矩形
鼠标画矩形: // An example program in which the // user can draw boxes on the screen. // /* License: Oct. ...
- Python可视化TVTK库初使用
本周学习了初步的TVTK库的安装及使用方法,第一次通过tvtk.CubeSource方法建立了一个长方体对象.对TVTK的接触有了新的体会. 首先,在网上下载了以下五个库并按顺序通过pip指令在cmd ...
- Ubuntu18.04教程
pre.ctl { font-family: "Liberation Mono", monospace } h1 { margin-bottom: 0.21cm } h1.west ...