MindSpore 初探, 使用LeNet训练minist数据集
如题所述,官网地址:
https://www.mindspore.cn/tutorial/zh-CN/r1.2/quick_start.html
数据集下载:
mkdir -p ./datasets/MNIST_Data/train ./datasets/MNIST_Data/test
wget -NP ./datasets/MNIST_Data/train https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-labels-idx1-ubyte
wget -NP ./datasets/MNIST_Data/train https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-images-idx3-ubyte
wget -NP ./datasets/MNIST_Data/test https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-labels-idx1-ubyte
wget -NP ./datasets/MNIST_Data/test https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-images-idx3-ubyte
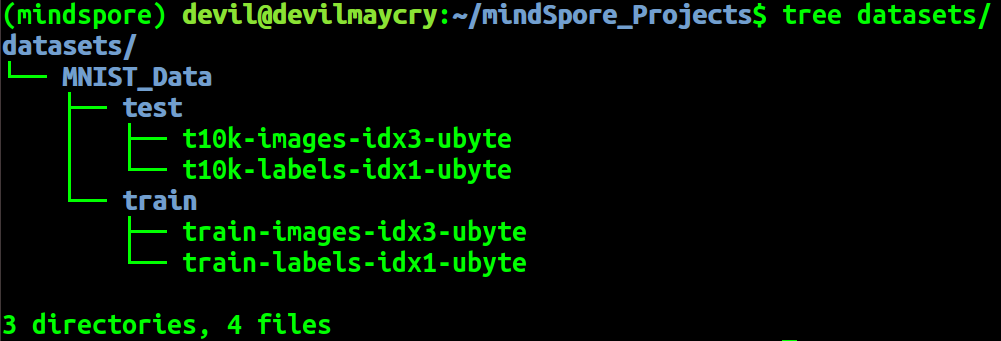
tree ./datasets/MNIST_Data
个人整合后的代码:
#!/usr/bin python
# encoding:UTF-8 """" 对输入的超参数进行处理 """
import os
import argparse """ 设置运行的背景context """
from mindspore import context """ 对数据集进行预处理 """
import mindspore.dataset as ds
import mindspore.dataset.transforms.c_transforms as C
import mindspore.dataset.vision.c_transforms as CV
from mindspore.dataset.vision import Inter
from mindspore import dtype as mstype """ 构建神经网络 """
import mindspore.nn as nn
from mindspore.common.initializer import Normal """ 训练时对模型参数的保存 """
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig """ 导入模型训练需要的库 """
from mindspore.nn import Accuracy
from mindspore.train.callback import LossMonitor
from mindspore import Model parser = argparse.ArgumentParser(description='MindSpore LeNet Example')
parser.add_argument('--device_target', type=str, default="CPU", choices=['Ascend', 'GPU', 'CPU']) args = parser.parse_known_args()[0] # 为mindspore设置运行背景context
context.set_context(mode=context.GRAPH_MODE, device_target=args.device_target) def create_dataset(data_path, batch_size=32, repeat_size=1,
num_parallel_workers=1):
# 定义数据集
mnist_ds = ds.MnistDataset(data_path)
resize_height, resize_width = 32, 32
rescale = 1.0 / 255.0
shift = 0.0
rescale_nml = 1 / 0.3081
shift_nml = -1 * 0.1307 / 0.3081 # 定义所需要操作的map映射
resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR)
rescale_nml_op = CV.Rescale(rescale_nml, shift_nml)
rescale_op = CV.Rescale(rescale, shift)
hwc2chw_op = CV.HWC2CHW()
type_cast_op = C.TypeCast(mstype.int32) # 使用map映射函数,将数据操作应用到数据集
mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns="label", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=resize_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=rescale_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=rescale_nml_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=num_parallel_workers) # 进行shuffle、batch、repeat操作
buffer_size = 10000
mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size)
mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)
mnist_ds = mnist_ds.repeat(repeat_size) return mnist_ds class LeNet5(nn.Cell):
"""
Lenet网络结构
""" def __init__(self, num_class=10, num_channel=1):
super(LeNet5, self).__init__()
# 定义所需要的运算
self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid')
self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid')
self.fc1 = nn.Dense(16 * 5 * 5, 120, weight_init=Normal(0.02))
self.fc2 = nn.Dense(120, 84, weight_init=Normal(0.02))
self.fc3 = nn.Dense(84, num_class, weight_init=Normal(0.02))
self.relu = nn.ReLU()
self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten() def construct(self, x):
# 使用定义好的运算构建前向网络
x = self.conv1(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.conv2(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x # 实例化网络
net = LeNet5() # 定义损失函数
net_loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean') # 定义优化器
net_opt = nn.Momentum(net.trainable_params(), learning_rate=0.01, momentum=0.9) # 设置模型保存参数
# 每125steps保存一次模型参数,最多保留15个文件
config_ck = CheckpointConfig(save_checkpoint_steps=125, keep_checkpoint_max=15)
# 应用模型保存参数
ckpoint = ModelCheckpoint(prefix="checkpoint_lenet", config=config_ck) def train_net(args, model, epoch_size, data_path, repeat_size, ckpoint_cb, sink_mode):
"""定义训练的方法"""
# 加载训练数据集
ds_train = create_dataset(os.path.join(data_path, "train"), 32, repeat_size)
model.train(epoch_size, ds_train, callbacks=[ckpoint_cb, LossMonitor(125)], dataset_sink_mode=sink_mode) def test_net(network, model, data_path):
"""定义验证的方法"""
ds_eval = create_dataset(os.path.join(data_path, "test"))
acc = model.eval(ds_eval, dataset_sink_mode=False)
print("{}".format(acc)) mnist_path = "./datasets/MNIST_Data"
train_epoch = 1
dataset_size = 1
model = Model(net, net_loss, net_opt, metrics={"Accuracy": Accuracy()})
train_net(args, model, train_epoch, mnist_path, dataset_size, ckpoint, False)
test_net(net, model, mnist_path)
训练结果:


epoch: 1 step: 125, loss is 2.2982173
epoch: 1 step: 250, loss is 2.296105
epoch: 1 step: 375, loss is 2.3065567
epoch: 1 step: 500, loss is 2.3062077
epoch: 1 step: 625, loss is 2.3096561
epoch: 1 step: 750, loss is 2.2847052
epoch: 1 step: 875, loss is 2.284628
epoch: 1 step: 1000, loss is 1.8122461
epoch: 1 step: 1125, loss is 0.4140602
epoch: 1 step: 1250, loss is 0.25238502
epoch: 1 step: 1375, loss is 0.17819008
epoch: 1 step: 1500, loss is 0.3202765
epoch: 1 step: 1625, loss is 0.12312577
epoch: 1 step: 1750, loss is 0.11027573
epoch: 1 step: 1875, loss is 0.2680659
{'Accuracy': 0.9598357371794872}

为网络导入模型参数,并进行预测:
本步骤与上面的训练步骤相关,需要前面设置好的数据集,并且需要前面已经训练好的网络参数。
import os
import numpy as np """ 构建神经网络 """
import mindspore.nn as nn
from mindspore.common.initializer import Normal
from mindspore import Tensor # 导入模型参数
from mindspore.train.serialization import load_checkpoint, load_param_into_net """ 对数据集进行预处理 """
import mindspore.dataset as ds
import mindspore.dataset.transforms.c_transforms as C
import mindspore.dataset.vision.c_transforms as CV
from mindspore.dataset.vision import Inter
from mindspore import dtype as mstype """ 导入模型训练需要的库 """
from mindspore.nn import Accuracy
from mindspore import Model def create_dataset(data_path, batch_size=32, repeat_size=1,
num_parallel_workers=1):
# 定义数据集
mnist_ds = ds.MnistDataset(data_path)
resize_height, resize_width = 32, 32
rescale = 1.0 / 255.0
shift = 0.0
rescale_nml = 1 / 0.3081
shift_nml = -1 * 0.1307 / 0.3081 # 定义所需要操作的map映射
resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR)
rescale_nml_op = CV.Rescale(rescale_nml, shift_nml)
rescale_op = CV.Rescale(rescale, shift)
hwc2chw_op = CV.HWC2CHW()
type_cast_op = C.TypeCast(mstype.int32) # 使用map映射函数,将数据操作应用到数据集
mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns="label", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=resize_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=rescale_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=rescale_nml_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=num_parallel_workers) # 进行shuffle、batch、repeat操作
buffer_size = 10000
mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size)
mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)
mnist_ds = mnist_ds.repeat(repeat_size) return mnist_ds class LeNet5(nn.Cell):
"""
Lenet网络结构
"""
def __init__(self, num_class=10, num_channel=1):
super(LeNet5, self).__init__()
# 定义所需要的运算
self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid')
self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid')
self.fc1 = nn.Dense(16 * 5 * 5, 120, weight_init=Normal(0.02))
self.fc2 = nn.Dense(120, 84, weight_init=Normal(0.02))
self.fc3 = nn.Dense(84, num_class, weight_init=Normal(0.02))
self.relu = nn.ReLU()
self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten() def construct(self, x):
# 使用定义好的运算构建前向网络
x = self.conv1(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.conv2(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x # 实例化网络
net = LeNet5()
# 定义损失函数
net_loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
# 定义优化器
net_opt = nn.Momentum(net.trainable_params(), learning_rate=0.01, momentum=0.9)
# 构建模型
model = Model(net, net_loss, net_opt, metrics={"Accuracy": Accuracy()}) # 加载已经保存的用于测试的模型
param_dict = load_checkpoint("checkpoint_lenet-1_1875.ckpt")
# 加载参数到网络中
load_param_into_net(net, param_dict) _batch_size = 8
# 定义测试数据集,batch_size设置为1,则取出一张图片
mnist_path = "./datasets/MNIST_Data"
ds_test = create_dataset(os.path.join(mnist_path, "test"), batch_size=_batch_size).create_dict_iterator()
data = next(ds_test) # images为测试图片,labels为测试图片的实际分类
images = data["image"].asnumpy()
labels = data["label"].asnumpy() # 使用函数model.predict预测image对应分类
output = model.predict(Tensor(data['image']))
predicted = np.argmax(output.asnumpy(), axis=1) # 输出预测分类与实际分类
for i in range(_batch_size):
print(f'Predicted: "{predicted[i]}", Actual: "{labels[i]}"')
运行结果:

MindSpore 初探, 使用LeNet训练minist数据集的更多相关文章
- 多层感知机训练minist数据集
MLP .caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1p ...
- Window10 上MindSpore(CPU)用LeNet网络训练MNIST
本文是在windows10上安装了CPU版本的Mindspore,并在mindspore的master分支基础上使用LeNet网络训练MNIST数据集,实践已训练成功,此文为记录过程中的出现问题: ( ...
- 使用caffe训练mnist数据集 - caffe教程实战(一)
个人认为学习一个陌生的框架,最好从例子开始,所以我们也从一个例子开始. 学习本教程之前,你需要首先对卷积神经网络算法原理有些了解,而且安装好了caffe 卷积神经网络原理参考:http://cs231 ...
- 实践详细篇-Windows下使用VS2015编译的Caffe训练mnist数据集
上一篇记录的是学习caffe前的环境准备以及如何创建好自己需要的caffe版本.这一篇记录的是如何使用编译好的caffe做训练mnist数据集,步骤编号延用上一篇 <实践详细篇-Windows下 ...
- LeNet训练MNIST
jupyter notebook: https://github.com/Penn000/NN/blob/master/notebook/LeNet/LeNet.ipynb LeNet训练MNIST ...
- 单向LSTM笔记, LSTM做minist数据集分类
单向LSTM笔记, LSTM做minist数据集分类 先介绍下torch.nn.LSTM()这个API 1.input_size: 每一个时步(time_step)输入到lstm单元的维度.(实际输入 ...
- 用CNN及MLP等方法识别minist数据集
用CNN及MLP等方法识别minist数据集 2017年02月13日 21:13:09 hnsywangxin 阅读数:1124更多 个人分类: 深度学习.keras.tensorflow.cnn ...
- Fast RCNN 训练自己数据集 (1编译配置)
FastRCNN 训练自己数据集 (1编译配置) 转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ https:/ ...
- 使用py-faster-rcnn训练VOC2007数据集时遇到问题
使用py-faster-rcnn训练VOC2007数据集时遇到如下问题: 1. KeyError: 'chair' File "/home/sai/py-faster-rcnn/tools/ ...
- BP算法在minist数据集上的简单实现
BP算法在minist上的简单实现 数据:http://yann.lecun.com/exdb/mnist/ 参考:blog,blog2,blog3,tensorflow 推导:http://www. ...
随机推荐
- SRE 排障利器,接口请求超时试试 httpstat
夜莺资深用户群有人推荐的一个工具,看了一下真挺好的,也推荐给大家. 需求场景 A 服务调用 B 服务的 HTTP 接口,发现 B 服务返回超时,不确定是网络的问题还是 B 服务的问题,需要排查. 工具 ...
- substr()函数用法
substr()函数: 定义和用法: substr()返回字符串的一部分 如果start参数是负数且length小于等于start,则length为0 语法: substr(starting,star ...
- 解读MySQL 8.0数据字典的初始化与启动
本文分享自华为云社区<MySQL全文索引源码剖析之Insert语句执行过程>,作者:GaussDB 数据库. 本文主要介绍MySQL 8.0数据字典的基本概念和数据字典的初始化与启动加载的 ...
- 图最短路径之BellmanFord
Bellman–Ford Algorithm 算法参考地址:Bellman–Ford Algorithm | DP-23 - GeeksforGeeks 算法的简介 在图中给定一个图形和一个源顶点 s ...
- 在 AWS 平台搭建 DolphinScheduler
AWS平台搭建 DolphinScheduler DolphinScheduler 是当前热门的调度器,提供了完善的可视化.拖拉拽式的调度.在 AWS 平台上提供了 airflow 与 step fu ...
- 记录用C#写折半查找算法实现
折半查找算法 前言 最近要考试了,重新回顾一下之前学的算法,今天是折半查找,它的平均比较次数是Log2 n 思想 给定一个有序数组A[0..n-1],和查找值K,返回K在A中的下标. 折半查找需要指定 ...
- Linux 内核:设备驱动模型(1)sysfs与kobject基类
Linux 内核:设备驱动模型(1)sysfs与kobject基类 背景 学习Linux 设备驱动模型时,对 kobject 不太理解.因此,学习了一下. 现在我知道了:kobj/kset是如何作为统 ...
- python基础-字典dict {key:value }
字典的定义和操作 字典的特性: 元素数量 支持多个 元素类型 key :value key:除字典外的任何类型 Value:任何类型 下标索引 不支持 重复元素 key不支持 可修改性 支持 数据有序 ...
- React中的Ref
React中ref是一个对象,它有一个current属性,可以对这个属性进行操作,用于获取DOM元素和保存变化的值.什么是保存变化的值?就是在组件中,你想保存与组件渲染无关的值,就是JSX中用不到的或 ...
- 记录一次python3 flask 多线程被执行两次的问题
前言 最近在使用 python3 flask 做管理服务,需要实现服务中 flask server 和 另一个多线程while循环同时存在,如下 from flask import Flask , j ...