MongoDB 安装、配置及详细使用教程
环境:win10
下载地址 :https://pan.baidu.com/s/1a0SwRv9er3HTewzcI8nWgQ
提取码:dyyx
下载后,将该文件夹放在C盘的根目录下,然后去配置系统环境变量,在PATH中添加 C:\mongodb\bin ,然后 点击确定
该文件夹中,有两个.bat结尾的文件,一个是startservice.bat(服务端),一个是startclient.bat (客户端),我们打开的时候,首先打开第一个(服务端),再打开第二个(客户),然后在第二个(客户)里面操作。
使用方法:
1、MongoDB 帮助 ------- db.help()

2、Mongodb 统计信息 ------ db.stats()
刚安装上的MongoDB ,默认默认的数据库为test,这个时候创建的集合,就会保存在test数据库中

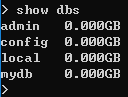
3、创建数据库 ------ use + databaseNmae , 例如:use mydb

4、检查当前所在的数据库 ------ db
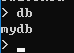
5、查看数据库列表 ------ show dbs
6、删除数据库 ------ db.dropDatabase()
首先,进入到要删除的数据库,use databaseName ,之后 db.dropDatabase() ,在查看 show dbs ,这时候发现,已经成功删除

7、创建集合 ------ db.createCollection(name, options)


① 不带参数, 查看 集合 ------ show collections
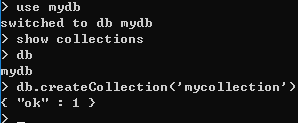
② 带参数的
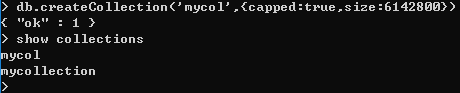
在 MongoDB 中,你不需要创建集合。当你插入一些文档时,MongoDB 会自动创建集合。

8、删除集合 ------ db.collectionName.drop()
MongoDB 利用 db.collectionName.drop()来删除数据库中的集合。

如果成功删除选定集合,则 drop()方法返回 true,否则返回false。
9、数据类型
MongoDB 支持如下数据类型:
- String:字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。
- Integer:整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。
- Boolean:布尔值。用于存储布尔值(真/假)。
- Double:双精度浮点值。用于存储浮点值。
- Min/Max keys:将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。
- Arrays:用于将数组或列表或多个值存储为一个键。
- Timestamp:时间戳。记录文档修改或添加的具体时间。
- Object:用于内嵌文档。
- Null:用于创建空值。
- Symbol:符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。
- Date:日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对
象,传入年月日信息。 - Object ID:对象 ID。用于创建文档的 ID。
- Binary Data:二进制数据。用于存储二进制数据。
- Code:代码类型。用于在文档中存储 JavaScript 代码。
- Regular expression:正则表达式类型。用于存储正则表达式。
10、插入文档 ------ db.collectionNmae.insert(document)
要想将数据插入 MongoDB 集合中,需要使用insert()或 save()方法。
insert()或 save()方法d的区别是当主键重复时,insert()会报错, save()会覆盖原有内容。
范例 1

mycol 是上一节所创建的集合的名称。如果数据库中不存在该集合,那么 MongoDB 会创建该集合,并向其中插入文档。
在插入的文档中,如果我们没有指定 _id 参数,那么 MongoDB 会自动为文档指定一个唯一的 ID。
为了,你可以将用 insert() 方法传入一个文档数组,范例如下:
范例 2
> 传入多条数据 格式:db.mycol.insert([{},{},{}])
>db.post.insert([
{
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
title: 'NoSQL Database',
description: 'NoSQL database doesn't have tables',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 20,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2013,11,10,2,35),
like: 0
}
]
}
])
也可以用 db.post.save(document)插入文档。如果没有指定文档的 _id ,那么save() 就和 insert()完全一样了。如果指定了文档的 _id ,那么它会覆盖掉含有 save() 方法中指定的 _id 的文档的全部数据。
11、查询文档 ------ db.collectionName.find()
find()方法会以非结构化的方式来显示所有文档。
pretty() 方法用格式化方式显示结果,使用的是 pretty() 方法。
语法格式
>db.COLLECTION_NAME.find().pretty()
范例
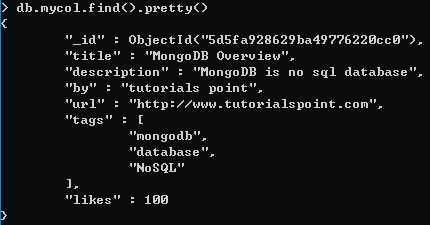
除了 find() 方法之外,还有一个 findOne() 方法,它只返回一个文档。
12、MongoDB 中类似于 WHERE 子句的语句
如果想要基于一些条件来查询文档,可以使用下列操作。
| 操作 | 格式 | 范例 | RDBMS中的类似语句 |
|---|---|---|---|
| 等于 | {<key>:<value> } | db.mycol.find({"by":"tutorials point"}).pretty() | where by = 'tutorials point' |
| 小于 | {<key>:{$lt:<value>}} | db.mycol.find({"likes":{$lt:50}}).pretty() | where likes < 50 |
| 小于或等于 | {<key>:{$lte:<value>}} | db.mycol.find({"likes":{$lte:50}}).pretty() | where likes <= 50 |
| 大于 | {<key>:{$gt:<value>}} | db.mycol.find({"likes":{$gt:50}}).pretty() | where likes > 50 |
| 大于或等于 | {<key>:{$gte:<value>}} | db.mycol.find({"likes":{$gte:50}}).pretty() | where likes >= 50 |
| 不等于 | {<key>:{$ne:<value>}} | db.mycol.find({"likes":{$ne:50}}).pretty() | where likes != 50 |
13、MongoDB 中的 And 条件
语法格式
在 find() 方法中,如果传入多个键,并用逗号( , )分隔它们,那么 MongoDB 会把它看成是 AND 条件。AND条件的基本语法格式为:
db.mycol.find({key1:value1, key2:value2}).pretty()
范例
下例将展示所有由 “tutorials point” 发表的标题为 “MongoDB Overview” 的教程。

对于上例这种情况,RDBMS 采用的 WHERE 子句将会是: where by='tutorials point' AND title='MongoDB Overview'。你可以在 find 子句中传入任意的键值对。
14、MongoDB 中的 OR 条件
若基于 OR 条件来查询文档,可以使用关键字$or。 OR 条件的基本语法格式为:
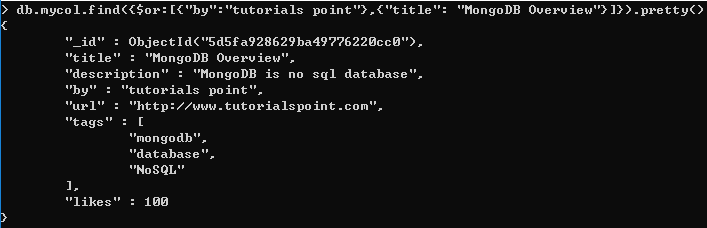
15、结合使用 AND 与 OR 条件
范例
下例所展示文档的条件为:喜欢数大于 100,标题是 “MongoDB Overview”,或者是由 “tutorials point”所发表的。响应的 SQL WHERE 子句为: where likes>10 AND (by = 'tutorials point' OR title = 'MongoDB Overview')
> 格式:db.mycol.find({},$or:[{},{}])

16、更新文档
MongoDB 中的 update() 与 save() 方法都能用于更新集合中的文档。 update() 方法更新已有文档中的值,而 save() 方法则是用传入该方法的文档来替换已有文档。
① update()方法 ------更新文档中已存在的值
语法格式
update()方法基本格式如下:
db.COLLECTION_NAME.update(SELECTIOIN_CRITERIA, UPDATED_DATA)
范例
假如 mycol 集合中有下列数据:
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
下面的例子将把文档原标题 'MongoDB Overview' 替换为新的标题 'New MongoDB Tutorial'。
>db.mycol.update({'title':'MongoDB Overview'},{$set:{'title':'New MongoDB Tutorial'}})
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"New MongoDB Tutorial"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
MongoDB 默认只更新单个文档,要想更新多个文档,需要把参数 multi 设为 true 。
>db.mycol.update({'title':'MongoDB Overview'},{$set:{'title':'New MongoDB Tutorial'}},{multi:true})
② save() 方法
save()方法利用传入该方法的文档来替换已有文档。
语法格式
save() 方法基本语法格式如下:
db.COLLECTION_NAME.save({_id:ObjectId(),NEW_DATA})
范例
下例更新 _id 为 '5983548781331adf45ec7' 的文档。
>db.mycol.save(
{
"_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point New Topic", "by":"Tutorials Point"
}
)
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"New MongoDB Tutorial"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point New Topic", "by":"Tutorials Point"}
17、删除文档 ------ db.collectionName.remove()
MongoDB 利用 remove() 方法 清除集合中的文档。它有 2 个可选参数:
- deletion criteria:(可选)删除文档的标准。
- justOne:(可选)如果设为 true 或 1,则只删除一个文档。
语法格式
remove()方法的基本语法格式如下所示:
db.COLLECTION_NAME.remove(DELLETION_CRITTERIA)
范例
假如 mycol 集合中包含下列数据:
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
下面我们将删除其中所有标题为 'MongoDB Overview' 的文档。
>db.mycol.remove({'title':'MongoDB Overview'})
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
18、只删除一个文档
如果有多个记录,而你只想删除第一条记录,那么就设置 remove() 方法中的 justOne 参数:
db.COLLECTION_NAME.remove(DELETION_CRITERIA,1)
19、删除所有文档
如果没有指定删除标准,则 MongoDB 会将集合中所有文档都予以删除。 这等同于 SQL 中的 truncate 命令。
>db.mycol.remove()
>db.mycol.find()
20、映射
在 MongoDB 中,映射(Projection)指的是只选择文档中的必要数据,而非全部数据。如果文档有 5 个字段,而你只需要显示 3 个,则只需选择 3 个字段即可。
21、find()方法
MongoDB 的查询文档曾介绍过find() 方法,不管是利用 AND 或 OR 条件来获取想要的字段列表都是显示一个文档的所有字段。要想限制,可以利用 0 或 1 来设置字段列表。1 用于显示字段,0 用于隐藏字段。
语法格式
带有映射的 find() 方法的基本语法格式为:
db.COLLECTION_NAME.find({},{KEY:1})
范例
假如 mycol 集合拥有下列数据:
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
下例将在查询文档时显示文档标题。
>db.mycol.find({},{"title":1,"_id":0})
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
{"title":"Tutorials Point Overview"}
注意:在执行 find() 方法时, _id 字段是一直显示的。如果不想显示该字段,则可以将其设为 0。
22、限制记录 ------ limit() 和 skip()
① limit() 方法
要想限制 MongoDB 中的记录,可以使用 limit()方法。limit() 方法接受一个数值类型的参数,其值为想要显示的文档数。
语法格式
limit()方法的基本语法格式为:
db.COLLECTION_NAME.find().limit(NUMBER)
范例
假设 mycol 集合拥有下列数据:
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
下例将在查询文档时只显示 2 个文档。
>db.mycol.find({},{"title":1,_id:0}).limit(2)
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
如果未指定limit() 方法中的数值参数,则将显示该集合内的所有文档。
② skip() 方法
语法格式
skip()方法基本语法格式为:
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
范例
下例将只显示第二个文档:
>db.mycol.find({},{"title":1,_id:0}).limit(1).skip(1)
{"title":"NoSQL Overview"}
注意: skip() 方法中的默认值为 0。
23、记录排序
① sort() 方法
MongoDB 中的文档排序是通过 sort()方法来实现的。 sort() 方法可以通过一些参数来指定要进行排序的字段,并使用 1 和 -1 来指定排序方式,其中 1 表示升序,而 -1 表示降序。
语法格式
sort() 方法基本格式为:
db.COLLECTION_NAME.find().sort({KEY:1})
范例
假设集合 myycol 包含下列数据:
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
下面的范例将显示按照降序排列标题的文档。
>db.mycol.find({},{"title":1,_id:0}).sort({"title":-1})
{"title":"Tutorials Point Overview"}
{"title":"NoSQL Overview"}
{"title":"MongoDB Overview"}
注意,如果不指定排序规则, sort() 方法将按照升序排列显示文档。
24、索引
索引能够实现高效地查询。没有索引,MongoDB 就必须扫描集合中的所有文档,才能找到匹配查询语句的文档。这种扫描毫无效率可言,需要处理大量的数据。
索引是一种特殊的数据结构,将一小块数据集保存为容易遍历的形式。索引能够存储某种特殊字段或字段集的值,并按照索引指定的方式将字段值进行排序。
① ensureIndex() 方法
要想创建索引,需要使用 MongoDB 的 ensureIndex() 方法。
语法格式
ensureIndex()方法的基本语法格式为:
db.COLLECTION_NAME.ensureIndex({KEY:1})
这里的 key 是想创建索引的字段名称,1 代表按升序排列字段值。-1 代表按降序排列。
范例
>db.mycol.ensureIndex({"title":1})
可以为 ensureIndex() 方法传入多个字段,从而为多个字段创建索引。
>db.mycol.ensureIndex({"title":1,"description":-1})
ensureIndex() 方法也可以接受一些可选参数,如下所示:
| 参数 | 类型 | 描述 |
|---|---|---|
| background | 布尔值 | 在后台构建索引,从而不干扰数据库的其他活动。取值为 true 时,代表在后台构建索引。默认值为 false |
| unique | 布尔值 | 创建一个唯一的索引,从而当索引键匹配了索引中一个已存在值时,集合不接受文档的插入。取值为 true 代表创建唯一性索引。默认值为 false 。 |
| name | 字符串 | 索引名称。如果未指定,MongoDB 会结合索引字段名称和排序序号,生成一个索引名称。 |
| dropDups | 布尔值 | 在可能有重复的字段内创建唯一性索引。ongoDB 只在某个键第一次出现时进行索引,去除该键后续出现时的所有文档。 |
| sparse | 布尔值 | 如果为 true,索引只引用带有指定字段的文档。这些索引占据的空间较小,但在一些情况下的表现也不同(特别是排序)。默认值为 false 。 |
| expireAfterSeconds | 整型值 | 指定一个秒数值,作为 TTL 来控制 MongoDB 保持集合中文档的时间。 |
| v | 索引版本 | 索引版本号。默认的索引版本跟创建索引时运行的 MongoDB 版本号有关。 |
| weights | 文档 | 数值,范围从 1 到 99, 999。表示就字段相对于其他索引字段的重要性。 |
| default_language | 字符串 | 对文本索引而言,用于确定停止词列表,以及词干分析器(stemmer)与断词器(tokenizer)的规则。默认值为 english。 |
| language_override | 字符串 | 对文本索引而言,指定了文档所包含的字段名,该语言将覆盖默认语言。默认值为 language。 |
25、聚合
聚合操作能够处理数据记录并返回计算结果。聚合操作能将多个文档中的值组合起来,对成组数据执行各种操作,返回单一的结果。它相当于 SQL 中的 count(*) 组合 group by。
① aggregate() 方法
对于 MongoDB 中的聚合操作,应该使用 aggregate()方法。
语法格式
aggregate() 方法中的基本格式如下所示:
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
范例
假如某个集合包含下列数据:
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Neo4j',
url: 'http://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
}
假如想从上述集合中,归纳出一个列表,以显示每个用户写的教程数量,需要像下面这样使用 aggregate() 方法:
> db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
{
"result" : [
{
"_id" : "tutorials point",
"num_tutorial" : 2
},
{
"_id" : "Neo4j",
"num_tutorial" : 1
}
],
"ok" : 1
}
假如用 SQL 来处理上述查询,则需要使用这样的命令:select by_user, count(*) from mycol group by by_user。
上例使用 by_user 字段来组合文档,每遇到一次 by_user,就递增之前的合计值。下面是聚合表达式列表。
| 表达式 | 描述 | 范例 |
|---|---|---|
$sum |
对集合中所有文档的定义值进行加和操作 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
$avg |
对集合中所有文档的定义值进行平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
$min |
计算集合中所有文档的对应值中的最小值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
$max |
计算集合中所有文档的对应值中的最大值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
$push |
将值插入到一个结果文档的数组中 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
$addToSet |
将值插入到一个结果文档的数组中,但不进行复制 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
$first |
根据成组方式,从源文档中获取第一个文档。但只有对之前应用过 $sort 管道操作符的结果才有意义。 |
db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
$last |
根据成组方式,从源文档中获取最后一个文档。但只有对之前进行过 $sort 管道操作符的结果才有意义。 |
db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
管道的概念
在 UNIX 命令 Shell 中,管道(pipeline)概念指的是能够在一些输入上执行一个操作,然后将输出结果用作下一个命令的输入。MongoDB 的聚合架构也支持这种概念。管道中有很多阶段(stage),在每一阶段中,管道操作符都会将一组文档作为输入,产生一个结果文档(或者管道终点所得到的最终 JSON 格式的文档),然后再将其用在下一阶段。
聚合架构中可能采取的管道操作符有:
- $project 用来选取集合中一些特定字段。
- $match 过滤操作。减少用作下一阶段输入的文档的数量。
- $group 如上所述,执行真正的聚合操作。
- $sort 对文档进行排序。
- $skip 在一组文档中,跳过指定数量的文档。
- $limit 将查看文档的数目限制为从当前位置处开始的指定数目。
- $unwind 解开使用数组的文档。当使用数组时,数据处于预连接状态,通过该操作,数据重新回归为各个单独的文档的状态。利用该阶段性操作可增加下一阶段性操作的文档数量。
26、创建备份
数据库备份
为了在 MongoDB 中创建数据库备份,需要使用 mongodump 命令。该命令会将服务器上的所有数据都转储到 dump 目录中。你可以使用很多选项来限制转储的数据量,或者创建远程服务器备份。
语法格式
mongodump 命令的基本语法格式为:
mongodump
范例
开启 mongod 服务器。假设 mongod 服务器运行在 localhost 上,端口为 27017。在命令行上输入命令,在 MongoDB 实例的 bin 目录下输入 mongodump 命令。
假设 mycol 集合包含如下数据:
>mongodump
上述命令会连接在 127.0.0.1 运行的服务器(端口为 27017),将所有数据备份到 /bin/dump 上。命令输出结果如下图所示:

mongodump 命令其实包含很多选项。
| 语法格式 | 描述 | 范例 |
|---|---|---|
mongodump --host HOST_NAME --port PORT_NUMBER |
该命令将指定 mongod 实例上的所有数据库都进行了备份 | mongodump --host tutorialspoint.com --port 27017 |
mongodump --dbpath DB_PATH --out BACKUP_DIRECTORY |
该命令将指定数据库内容存放目录和备份输出目录 | mongodump --dbpath /data/db/ --out /data/backup/ |
mongodump --collection COLLECTION --db DB_NAME |
该命令只备份那些指定路径上的指定数据库 | mongodump --collection mycol --db test |
27、恢复备份
重新恢复数据
恢复备份数据使用 mongorestore 命令,该命令将备份目录中的所有数据给予恢复。
语法格式
mongorestore 命令的基本语法格式为:
> mongorestore
范例
该命令输入结果如下图所示:

MongoDB 安装、配置及详细使用教程的更多相关文章
- windows下 zookeeper dubbo 安装+配置+demo 详细图文教程
Java集群优化——dubbo+zookeeper构建 互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,Dubbo是一个分布式服务框架,在这 ...
- 在linux下安装配置rabbitMQ详细教程
在linux下安装配置rabbitMQ详细教程 2017年12月20日 17:34:47 阅读数:7539 安装Erlang 由于RabbitMQ依赖Erlang, 所以需要先安装Erlang. Er ...
- 微软源代码管理工具TFS2013安装与使用详细图文教程(Vs2013)
这篇文章联合软件小编主要介绍了微软源代码管理工具TFS2013安装与使用图文教程,本文详细的给出了TFS2013的安装配置过程.使用教程,需要的朋友可以参考下 最近公司新开发一个项目要用微软的TFS2 ...
- [转] 微软源代码管理工具TFS2013安装与使用详细图文教程(Vs2013)
这篇文章联合软件小编主要介绍了微软源代码管理工具TFS2013安装与使用图文教程,本文详细的给出了TFS2013的安装配置过程.使用教程,需要的朋友可以参考下 最近公司新开发一个项目要用微软的TFS2 ...
- Linux下mongodb安装及数据导入导出教程
Linux下mongodb安装及数据导入导出教程 #查看linux发行版本 cat /etc/issue #查看linux内核版本号 uname -r 一.Linux下mongodb安装的一般步骤 1 ...
- MongoDB C Driver and APIinstances linux MongoDB安装配置
<一,linux平台MongoDB安装配置>在这我们使用的Centos6 yum部署的,你想搞编译,自个干!
- CentOS 6.4安装(超级详细图解教程)
链接地址:http://www.osyunwei.com/archives/5855.html CentOS 6.4安装(超级详细图解教程) 附:CentOS 6.4下载地址 32位:http://m ...
- docker安装配置gitlab详细过程
docker安装配置gitlab详细过程 获取镜像 1.方法一 1 docker pull beginor/gitlab-ce:11.0.1-ce.0 2.方法二如果服务器网路不好或者pull不下 ...
- ogre3d环境配置 SDK安装配置及简单事例教程
ogre3d环境配置 SDK安装配置及简单事例教程 http://www.cr173.com/html/22594_1.html ogre3d环境配置 SDK安装配置及简单事例教程 http://ww ...
- python爬虫-MongoDB安装配置
MongoDB安装配置: 在安装配置MongoDB的过程中遇到了很多问题,现在重新梳理一遍安装流程.遇到的问题及其解决方法 系统版本:Windows 10 MongoDB版本:4.2.1 1.下载地址 ...
随机推荐
- python第2~5章 学习笔记
# 第2~5章 学习笔记 ## 什么是计算机语言 计算机就是一台用来计算机的机器,人让计算机干什么计算机就得干什么! 需要通过计算机的语言来控制计算机(编程语言)! 计算机语言其实和人类的语言没有本质 ...
- C转C++ 个人总结
# C转C++ 个人总结 1.使用C++的好处 2.using namespace std 3.cin和cout #include<iostream> //必备的头文件 using nam ...
- Python join拼接
import os print(os.path.join("I","love","you.")) # /XXX 代表的是绝对路径 这个变量之 ...
- 可视化-vscode安装matplotlib工具
可视化工具中,最流行的工具之一是 Matplotlib,它是一个数学绘图库,可以制作简单的图表,如折线图和散点图: 使用pip可以安装Matplotlib: 安装步骤:: 1.在vscode的终端输入 ...
- 2023 版 Java和python开发线性代数探索
目录 前景提示 需求 分析 1.初始化不需要指定矩阵的尺寸,并且可以直接传入数据. 2.可以计算2x2矩阵的逆 3.可以做2x2的矩阵乘法 Java版本开发 一. 开发详情 1.开发一个子类,如图所示 ...
- docker 下拉取oracle_11G镜像配置
1.拉取镜像 docker pull registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g#查看镜像信息docker images 2.创建容器 # ...
- k8s集群证书过期,重新生成证书
Kubernetes集群证书过期后,使用kubeadm重新颁发证书 默认情况下部署kubernetes集群的证书一年内便过期,如果不及时升级证书导致证书过期,Kubernetes控制节点便会不可用,所 ...
- java_2.常量、Scanner类、基本数据类型转换、算数运算符
常量.Scanner类.基本数据类型转换.算数运算符 变量和常量 常量 1.使用final关键字修饰,只能赋值一次,不可以修改值. 2.常量的名称使用全大写. 3.多个单词使用下划线分隔. publi ...
- 昇腾迁移丨4个TensorFlow模型训练案例解读
本文分享自华为云社区<TensorFlow模型训练常见案例>,作者: 昇腾CANN. 基于TensorFlow的Python API开发的训练脚本默认运行在CPU/GPU/TPU上,为了使 ...
- CodeChef Starters 9 Division 3 (Rated) India Fights Corona
原题链接 India Fights Corona 题意: 有\(n\)个城市,\(m\)条道路,其中有些城市自己有医院,所以可以在自己城市做核酸检测,那么花费就只有就医费用,而对于那些自己没有医院的城 ...