【Python】【爬虫】【爬狼】003_获取搜索结果的页数
# 获取搜索内容的页数
需要的包
import urllib.request # 获取网页源码
import re # 正则表达式,进行文字匹配
from bs4 import BeautifulSoup # 解析网页
解析网页
第一步,解析网页为网页源码(【Python】【爬虫系列】【爬狼】002_自定义获取网页源码的函数 - 萌狼蓝天 - 博客园 (cnblogs.com/mllt))
# 获取网页源码
response_html = xrilang_UrlToDocument(Url)
# xrilang_UrlToDocument是我自定义函数,如果你没写这个函数,直接使用,会报错的。
# 如果你想了解这个函数的具体内容,请看【爬狼系列】笔记第002篇
获取搜索内容的页数
分析网页

切换页数,观察地址栏变化。
根据观察第二页、第三页链接如下
# 第二页
https://www.yhdmp.cc/s_all?kw=love&pagesize=24&pageindex=1
# 第三页
https://www.yhdmp.cc/s_all?kw=love&pagesize=24&pageindex=2
由此可以推测出,第一页的地址为
https://www.yhdmp.cc/s_all?kw=love&pagesize=24&pageindex=0
s_all:Search All 搜索全部
kw:Key Word
pagesize:页面大小(一页有多少个视频)
pageindex:页面索引(索引从0开始,代表页数。索引0是第一页,索引1是第二页,以此类推)
获取视频数量

此处会显示视频数量,我们只需取出这个“数字”就可以了。
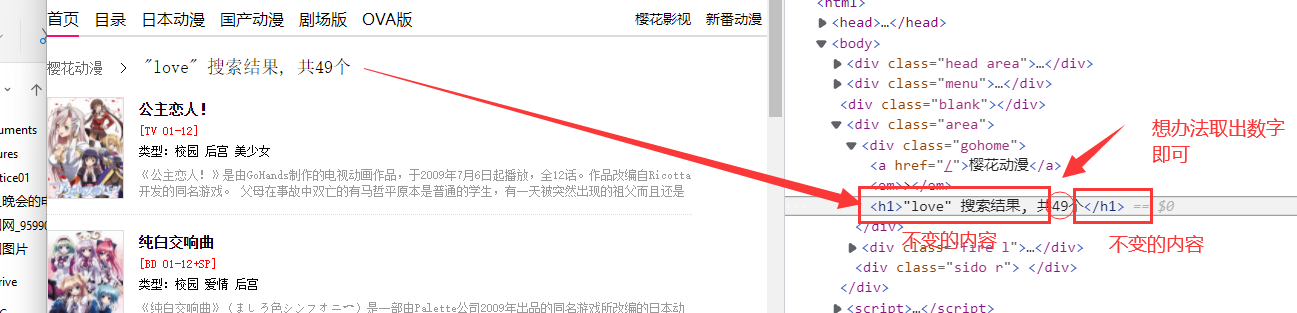
方法1
# 1.获取所搜结果视频数量
reStr1 = r'''搜索结果, 共(.*?)个''' # 正则规则
# temp = re.findall(reStr1, response_html) # 在 response_html 中查找符合上述正则规则(reStr1)的内容
# 运行结果为:['49']
mvNumber = re.findall(reStr1, response_html)[0] # 取出列表的第一项(索引为0) 设置变量mvNumber(搜索得到的视频数量)
# 运行结果为:49
方法2(推荐使用)
# 1.获取所搜结果视频数量
reStr1 = re.compile(r'''搜索结果, 共(.*?)个''') # 正则规则
# temp = re.findall(reStr1, response_html) # 在 response_html 中查找符合上述正则规则(reStr1)的内容
# 运行结果为:['49']
mvNumber = re.findall(reStr1, response_html)[0] # 取出列表的第一项(索引为0) 设置变量mvNumber(搜索得到的视频数量)
# 运行结果为:49
通过视频数量获取页数
通过分析,我们知道,一页有24个视频,视频总数在上面已经求出来了,那么会有多少页呢,这就是一个小学的题了。
视频总数/每页展示视频数=总页数
即:视频总数/24=总页数
注意,如果有余数,则直接+1,结果为整数
# 通过视频数量判断有多少页
# pageNumber = int(mvNumber) / 24
# 运行结果为:2.0416666666666665
# 求出页数
if (int(mvNumber) % 24) == 0:
pageNumber = int(mvNumber) / 24
else:
pageNumber = int(int(mvNumber) / 24) + 1
# 最终得到页数结果 pageNumber
# mvNumber是视频总数
将此功能编写为函数
为了方便求页数,我们需要将次功能编写为函数方便我们使用
def xrilag_SearchAll(keyword):
"""
'获取搜索内容的总页数'
:param keyword:搜索的关键字
:return:int 搜索结果的总页数
"""
# 基础链接
baseUrl = "https://www.yhdmp.cc/s_all?ex=1&kw="
Url = baseUrl + keyword
# 获取网页源码
response_html = xrilang_UrlToDocument(Url)
# 1.获取所搜结果视频数量
reStr1 = re.compile(r'''搜索结果, 共(.*?)个''') # 正则规则
# temp = re.findall(reStr1, response_html) # 在 response_html 中查找符合上述正则规则(reStr1)的内容
# 运行结果为:['49']
mvNumber = re.findall(reStr1, response_html)[0] # 取出列表的第一项(索引为0) 设置变量mvNumber(搜索得到的视频数量)
# 运行结果为:49
# 通过视频数量判断有多少页
# pageNumber = int(mvNumber) / 24
# 运行结果为:2.0416666666666665
# 求出页数
if (int(mvNumber) % 24) == 0:
pageNumber = int(mvNumber) / 24
else:
pageNumber = int(int(mvNumber) / 24) + 1
# 最终得到页数结果 pageNumber
return pageNumber
学习本文,最重要的是学习思维和处理方式
【Python】【爬虫】【爬狼】003_获取搜索结果的页数的更多相关文章
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- 使用python爬虫爬取链家潍坊市二手房项目
使用python爬虫爬取链家潍坊市二手房项目 需求分析 需要将潍坊市各县市区页面所展示的二手房信息按要求爬取下来,同时保存到本地. 流程设计 明确目标网站URL( https://wf.lianjia ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
随机推荐
- 系统 内核启动期间使用ftrace
启动阶段使能event trace 同上,配置commandline: trace_event=sched:*,timer:*,irq:* trace_buf_size=40M 有上面的实例可以知道, ...
- 将nii文件CT图像更改窗宽窗位之后保存成nii文件
因为项目需要把CT图像中骨头更加明确的显示出来,且还需要保存nii文件,所以查了一些资料,在这里做一下笔记,方便以后使用.代码如下: import nibabel as nib import nump ...
- 2023年3月中国数据库行业分析报告正式发布,带你了解NL2SQL技术原理
为了帮助大家及时了解中国数据库行业发展现状.梳理当前数据库市场环境和产品生态等情况,从2022年4月起,墨天轮社区行业分析研究团队出品将持续每月为大家推出最新<中国数据库行业分析报告>,持 ...
- vant 2 的 toast
因为toast使用的场景比较频繁,所以在 注册使用 Toast 的时候,直接在Vue实列的原型上添加了toast方便我们使用 : 格式:this.$toast.fail() this.$to ...
- Vue-Router 是干什么的,原理是什么?
传统的项目中,页面的切换和跳转使用的是超链接实现,但是目前的SPA 是基于组件和路由实现的,页面的切换和跳转是由路由机制完成,区别是更新了视图但不重新请求页面: 原理是把url 和组件之间建立映射关系 ...
- CSP-S 2022~2023 补题
下面的代码都是远古代码,不打算重写了. CSP-S 2023 T1 密码锁 题意:一个密码锁上有 \(5\) 个位置,每个位置上的数字是 \(0 \sim 9\) 的循环,每次打乱会选择一或两个相邻位 ...
- 五、Spring Boot集成Spring Security之认证流程2
二.概要说明 上文已详细介绍了四.Spring Boot集成Spring Security之认证流程 本文则着重介绍用户名密码认证过滤器UsernamePasswordAuthenticationFi ...
- KubeSphere 社区双周报 | OpenFunction 发布 v1.1.0 | 2023.5.26-6.8
KubeSphere 社区双周报主要整理展示新增的贡献者名单和证书.新增的讲师证书以及两周内提交过 commit 的贡献者,并对近期重要的 PR 进行解析,同时还包含了线上/线下活动和布道推广等一系列 ...
- 【2024】所有人都能看懂的 Win 11 安装/重装教程,跟着我一遍包成功
无论你因为系统坏掉想重装一下 Windows,或者只是想升级一下 Windows 都可以.虽然标题写的是 Win 11,不过实际上对于任何 Windows 系统都适用,不过现在 Win 11 已经相当 ...
- Promise 简单实例一枚
<script> function t(){ return new Promise((resolve, reject)=>{ setTimeout(()=>{ resolve( ...