Python爬虫教程-02-使用urlopen
Spider-02-使用urlopen
做一个最简单的python爬虫,使用爬虫爬取:智联招聘某招聘信息的DOM
urllib
- 包含模块
- urllib.request:打开和读取urls
- urllib.error:包含urllib.request产生的常见错误,使用try捕捉
- urllib.parse:包含解析url的方法
- urllib.robotparse:解析robots.txt文件
robots:机器人协议,放在网站的开头,供给爬虫读取,当爬虫读到robots之后,就知道那些是允许爬取的数据,哪些是禁止爬取的数据
(爬虫道德问题:1.不许过频繁爬取 2.不许爬取禁止内容) - 案例v1 (使用PyCharm开发工具,配置python解释器,创建python文件)
- 我把代码放在github了,可以直接下载,地址:
- py01v1.py文件:https://xpwi.github.io/py/py爬虫/py01v1.py
- request.py文档文件:https://xpwi.github.io/py/py爬虫/request.py
# py01v1.py
from urllib import request
# 使用urllib.request请求一个网页的内容,并把内容打印出来
if __name__ == '__main__':
# 定义需要爬的页面
url = "https://jobs.zhaopin.com/CC375882789J00033399409.htm"
# 打开相应url并把页面作为返回
rsp = request.urlopen(url)
# 按住Ctrl键不送,同时点击urlopen,可以查看文档,有函数的具体参数和使用方法
# 把返回结果读取出来
html = rsp.read()
print(html)
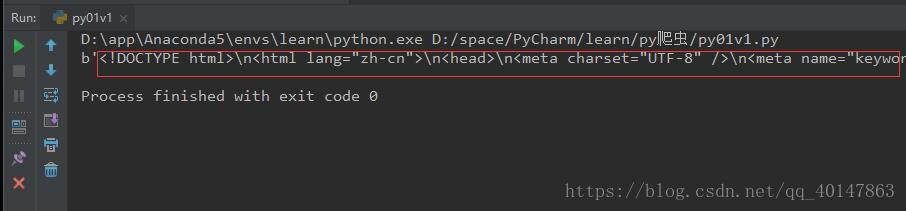
上面简单几行代码就可以爬取页面的HTML代码了
右键运行,截图如下
但是,我们爬取到的代码是不能自行显示中文的,需要解码处理
py02v1.py文件:https://xpwi.github.io/py/py爬虫/py02v1.py
# py02v1.py
from urllib import request
if __name__ == '__main__':
url = "https://jobs.zhaopin.com/CC375882789J00033399409.htm"
rsp = request.urlopen(url)
# 按住Ctrl键不送,同时点击urlopen,可以查看文档,有函数的具体参数和使用方法
html = rsp.read()
# 解码
html = html.decode()
print(html)
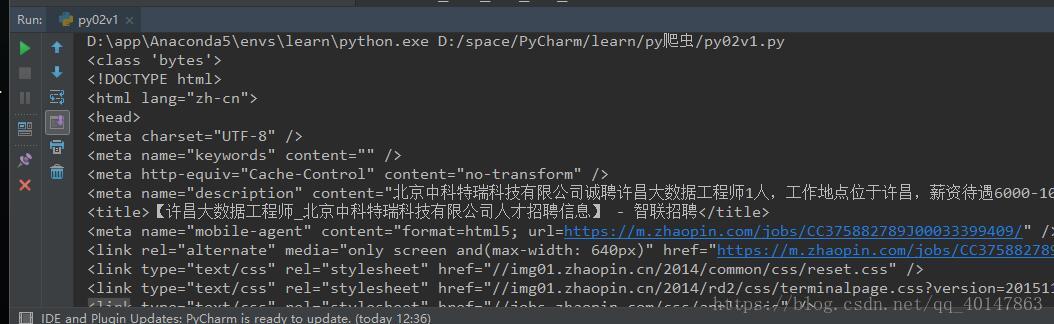
解码后效果:
恭喜你,最简单的爬虫就已经学会啦!
如果运行失败,可能是
1.【爬取的连接失效】,更换最新的地址就可以了
2.【Python环境问题】,这里不做仔细介绍,请自行【百度】解决,也可联系博主
QQ:1370911284
微信:18322295195
更多文章链接:Python 爬虫随笔
- 本笔记学习于图灵学院python全栈课程
- 本笔记不允许任何个人和组织转载
Python爬虫教程-02-使用urlopen的更多相关文章
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
- Python爬虫教程-09-error 模块
Python爬虫教程-09-error模块 今天的主角是error,爬取的时候,很容易出现错,所以我们要在代码里做一些,常见错误的处,关于urllib.error URLError URLError ...
- Python爬虫教程-08-post介绍(百度翻译)(下)
Python爬虫教程-08-post介绍(下) 为了更多的设置请求信息,单纯的通过urlopen已经不太能满足需求,此时需要使用request.Request类 构造Request 实例 req = ...
- Python爬虫教程-07-post介绍(百度翻译)(上)
Python爬虫教程-07-post介绍(百度翻译)(上) 访问网络两种方法 get: 利用参数给服务器传递信息 参数为dict,使用parse编码 post :(今天给大家介绍的post) 一般向服 ...
- Python爬虫教程-25-数据提取-BeautifulSoup4(三)
Python爬虫教程-25-数据提取-BeautifulSoup4(三) 本篇介绍 BeautifulSoup 中的 css 选择器 css 选择器 使用 soup.select 返回一个列表 通过标 ...
- Python爬虫教程-24-数据提取-BeautifulSoup4(二)
Python爬虫教程-24-数据提取-BeautifulSoup4(二) 本篇介绍 bs 如何遍历一个文档对象 遍历文档对象 contents:tag 的子节点以列表的方式输出 children:子节 ...
随机推荐
- java防范跨站脚本攻击(XSS)
网络中心提示网站有数目众多的跨站脚本攻击(XSS)漏洞,经过查看代码,认为是JSP中绑定变量是未经处理直接写入的,而且整个项目中这样的做法太多,因为是多年前的,不好一个个更改,参照网上资料,通过加fi ...
- C#原生压缩和解压缩方法
string path = AppDomain.CurrentDomain.BaseDirectory; string startPath = @"c:\Client"; stri ...
- javascript中prototype与__proto__
1.prototype:构造函数独有的属性: __proto__:每个对象都有一个名为__proto__的属性: 注意:每个构造函数(自带与自创)都有一个prototype的属性,构造函数的proto ...
- 在JSP中常见问题,防止SpringMVC拦截器拦截js等静态资源文件的解决方案
方案一.拦截器中增加针对静态资源不进行过滤(涉及spring-mvc.xml) <mvc:resources location="/" mapping="/**/* ...
- 【数组】Unique Paths
题目: A robot is located at the top-left corner of a m x n grid (marked 'Start' in the diagram below). ...
- 各种height/width总结
CSS盒模型是比较复杂的,尤其是当页面中有滚动条时,仅仅通过css来操作高度宽度是不够的,幸运的是Javascript提供了不少这样的接口.Javascript中clientHeight / clie ...
- ECharts概念学习系列之ECharts是什么?
不多说,直接上干货! http://echarts.baidu.com/index.html http://echarts.baidu.com/echarts2/index.html 开源的EChar ...
- Ambari集群里操作时典型权限问题put: `/home/bigdata/1.txt': No such file or directory的解决方案(图文详解)
不多说,直接上干货! 问题详情 明明put该有的文件在,可是怎么提示的是文件找不到的错误呢? 我就纳闷了put: `/home/bigdata/1.txt': No such file or dire ...
- maven的安装配置超详细教程【含nexus】
1 下载 下载地址:http://maven.apache.org/download.cgi 界面效果如下: 点击之后进入的apache 软件基金的发布目录,在这里你可以下载apache的所有项目. ...
- Linux下批量修改文件及文件夹所有者及权限
Linux下批量修改文件及文件夹所有者及权限需要使用到两个命令,chmod以及chown 例:对/opt/Oracle/目录下的所有文件与子目录执行相同的权限变更: chmod -R 700 /opt ...