solr配置相关:约束文件及引入ik分词器
schema.xml: solr约束文件
Solr中会提前对文档中的字段进行定义,并且在schema.xml中对这些字段的属性进行约束,例如:字段数据类型、字段是否索引、是否存储、是否分词等等
<!--第一种标签为 field标签: 主要是用来指定字段名称的, Lucene中是有用户在程序中指定, solr中需要提前在配置文件中指定-->
<field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>
<!--name: 字段的名称
type: 字段的类型
indexed: 是否索引
stored: 是否保存
multiValued: 是否多值, 这个字段, 类似存储一个数组
这里有两个不允许删除的: 一个是 _version__ 一个是 _root__ 这两个是solr内部需要使用的字段 有一个字段的名称必须为id,其类型都不允许进行修改 原因是id字段已经被主键使用uniqueKey
其余的是一些初始化好的字段
-->
<!--第二种标签为dynamicField, 被称为是动态域 -->
<dynamicField name="*_is" type="int" indexed="true" stored="true" multiValued="true"/>
<!--此种标签是为程序的扩展所使用的, 因为我们不可能把所有的字段全部定义好, 所以就需要动态域来进行动态扩展--> <!--第三种标签为 uniqueKey: 必要标签, 表名文档的唯一属性, 一般默认为id-->
<uniqueKey>id</uniqueKey>
<!--Lucene中是自己进行维护, solr中, 需要自己指定--> <!--第四种标签为 copyField: 被称为是复制域-->
<copyField source="cat" dest="text"/>
<!--source: 表名要复制那个字段的值
dest: 复制到那个字段上 此种标签主要是为了查询所使用的,
例如, 当查询Text字段的时候, 实质上相当于查询title和name两个字段--> <!--第五种标签: fieldType 字段类型定义标签-->
<fieldType name="managed_en" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.ManagedStopFilterFactory" managed="english" />
<filter class="solr.ManagedSynonymFilterFactory" managed="english" />
</analyzer>
</fieldType> <!--此种标签是用来定义字段的类型的,可以指定此字段使用何种分词器进行分词-->
引入ik分词器
第一步: 导入ik相关的依赖包
将三个文件放置在tomcat>webapps>solr>WEB-INF>lib下(此步骤在部署solr到tomcat中的时候, 就已经导入了)

第二步: 导入ik相关的配置文件(ik配置文件, 扩展词典和停止词典)
将三个文件放置在tomcat>webapps>solr>WEB-INF>classes下(此步骤, 在部署solr到tomcat中的时候, 已经导入)
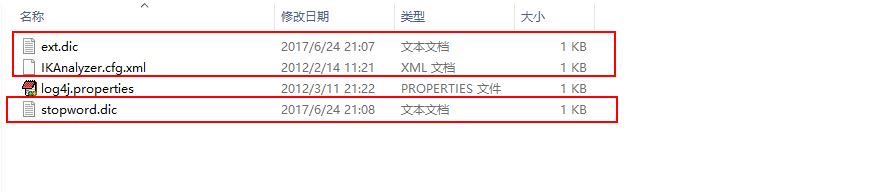
第三步, 在schema.xml配置文件中自定义一个字段类型, 引入ik分词器
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>

第四步: 为对应的字段设置为text_ik类型即可
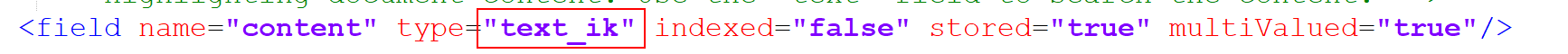
最终的配置文件:schema.xml
<?xml version="1.0" encoding="UTF-8" ?> <schema name="example" version="1.5"> <!-- 不删除
-->
<field name="_version_" type="long" indexed="true" stored="true"/>
<field name="_root_" type="string" indexed="true" stored="false"/> <!--不删除
id: 文档的唯一标识
在lucene中文档唯一的id是lucene自己维护的,, 在solr中,需要程序员自己维护
id字段了的设置内容, 尽量的不要动
-->
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!--
field: 用来定义字段的
name: 字段的名称
type: 字段类型
indexed: 是否分词
stored: 是否保存
multiValued: 是否是多值(当前的这个字段可以是一个数组)
-->
<field name="name" type="text_ik" indexed="true" stored="true"/> <field name="title" type="text_ik" indexed="true" stored="true" /> <field name="content" type="text_ik" indexed="true" stored="true" /> <!--此字段主要用来做查询使用的-->
<field name="text" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<!--
dynamicField: 动态域
为了程序的扩展使用的, 因为有时候无法在配置文件中将所以的字段全部定义了
对于solr来讲, 提供了动态域, 只需要用户在添加索引的时候字段名称的后缀名和动态域的名称一致就可以
-->
<dynamicField name="*_c" type="text_ik" indexed="true" stored="true"/> <!-- Field to use to determine and enforce document uniqueness.
Unless this field is marked with required="false", it will be a required field
-->
<!--
uniqueKey: 文档的唯一标识的字段是谁
-->
<uniqueKey>id</uniqueKey> <!--
copyField: 复制域
source: 来源字段
dest: 目标字段
复制域的作用是用来做查询的, 将其他几个字段的值全部的复制到目标字段中
当进行查询的时候, 如果查询的是text字段, 相当于查询了cat和name字段了
-->
<copyField source="content" dest="text"/>
<copyField source="name" dest="text"/> <!--
fieldType: 字段的类型
name: 类型的名称
class: 类型原生的类
在这个标签中, 可以用来规定资格字段类型的分词效果
可以通过这个标签设置新的字段类型,例如 ik分词器
-->
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<!-- boolean type: "true" or "false" -->
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/> <fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/>
<!--ik分词器配置-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType> </schema>
solr配置相关:约束文件及引入ik分词器的更多相关文章
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例二.
为了更好的排版, 所以将IK分词器的安装重启了一篇博文, 大家可以接上solr的安装一同查看.[Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一: http://ww ...
- Lucene介绍及简单入门案例(集成ik分词器)
介绍 Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和 ...
- IK分词器 整合solr4.7 含同义词、切分词、停止词
转载请注明出处! IK分词器如果配置成 <fieldType name="text_ik" class="solr.TextField"> < ...
- Solr 06 - Solr中配置使用IK分词器 (配置schema.xml)
目录 1 配置中文分词器 1.1 准备IK中文分词器 1.2 配置schema.xml文件 1.3 重启Tomcat并测试 2 配置业务域 2.1 准备商品数据 2.2 配置商品业务域 2.3 配置s ...
- solr添加中文IK分词器,以及配置自定义词库
Solr是一个基于Lucene的Java搜索引擎服务器.Solr 提供了层面搜索.命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式).它易于安装和配置,而且附带了一个基于H ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一.
在这里一下讲解着三个的安装和配置, 是因为solr需要使用tomcat和IK分词器, 这里会通过图文教程的形式来详解它们的安装和使用.注: 本文属于原创文章, 如若转载,请注明出处, 谢谢.关于设置I ...
- Solr(四)Solr实现简单的类似百度搜索高亮功能-1.配置Ik分词器
配置Ik分词器 一 效果图 二 实现此功能需要添加分词器,在这里使用比较主流的IK分词器. 1 没有配置IK分词器,用solr自带的text分词它会把一句话分成单个的字. 2 配置IK分词器,的话它会 ...
- Solr4.4入门,介绍Solr的安装、IK分词器的配置及高亮查询结果(转)
一.Windows下安装solr-4.4.0 1. 下载solr.4.4 2. 下载绿色版tomcat6.0.18 3. 解压下载的solr到d:\study\solr,将dist目录下的sol ...
- solr配置同义词,停止词,和扩展词库(IK分词器为例)
定义 同义词:搜索结果里出现的同义词.如我们输入”还行”,得到的结果包括同义词”还可以”. 停止词:在搜索时不用出现在结果里的词.比如is .a .are .”的”,“得”,“我” 等,这些词会在句子 ...
随机推荐
- [MEF]第01篇 MEF使用入门
一.演示概述 此演示初步介绍了MEF的基本使用,包括对MEF中的Export.Import和Catalog做了初步的介绍,并通过一个具体的Demo来展示MEF是如何实现高内聚.低耦合和高扩展性的软件架 ...
- poj 1637 Sightseeing tour——最大流+欧拉回路
题目:http://poj.org/problem?id=1637 先给无向边随便定向,如果一个点的入度大于出度,就从源点向它连 ( 入度 - 出度 / 2 ) 容量的边,意为需要流出去这么多:流出去 ...
- 10.Python运行Scrapy时出现错误: ModuleNotFoundError: No module named 'win32api'
1.在命令行输入:scrapy crawl demo(demo为爬虫标识,是唯一的) 2.报错信息如下所示: 3.解决方法:https://github.com/mhammond/pywin32/re ...
- 优化html标签
借用Effective之名,开始写Effective系列,总结一些前端的心得. 有些人写页面会走向一个极端,几乎页面所有的标签都用div,究其原因,用div有很多好处,一个是div没有默认样式,不会有 ...
- JDBC 流程
转载地址:https://blog.csdn.net/suwu150/article/details/52744952 JDBC编程的六个步骤: 准备工作中导入ojdbc文件,然后右键选中添加路 ...
- python中format函数学习笔记
简而言之,format函数就是用{}来代替之前的输出字符时使用的% print('my name is %s and I am %d years old' % ('porsche',23)) 下面详细 ...
- 封装与继承(PHP学习)
什么是封装? 答:封装时不知道内部构造,对外部只展现功能的这种行为.例如:收音机,你不知道收音机内部的构造,但是你知道收音机是能用来听广播的. 在PHP中,封装是,不对外公布,属性和方法,这些属性和方 ...
- FPGA设计者必须精通的5项基本功
FPGA设计者的5项基本功:仿真.综合.时序分析.调试.验证. 对于FPGA设计者来说,练好这5项基本功,与用好相应的EDA工具是同一过程,对应关系如下: 1. 仿真:Modelsim, Quartu ...
- Clustershell集群管理
在运维实战中,如果有若干台数据库服务器,想对这些服务器进行同等动作,比如查看它们当前的即时负载情况,查看它们的主机名,分发文件等等,这个时候该怎么办?一个个登陆服务器去操作,太傻帽了!写个shell去 ...
- python 数组的操作--统计某个元素在列表中出现的次数
list.count(obj) 统计某个元素在列表中出现的次数例子: aList = [123, 'xyz', 'zara', 'abc', 123]; print "Count for ...