【NLP_Stanford课堂】拼写校正
在多种应用比如word中都有拼写检查和校正功能,具体步骤分为:
- 拼写错误检测
- 拼写错误校正:
- 自动校正:hte -> the
- 建议一个校正
- 建议多个校正
拼写错误类型:
- Non-word Errors非词错误:即写了一个不是单词的词,比如graffe并不存在,应校正为giraffe
- 检测方法:认为任一不在字典中的词都是一个非词错误,因此字典本身越大越好
- 校正方法:为错误词产生一个候选,其是跟错误词相似的真词,然后选择加权编辑距离最短或者信道噪声概率最高的那个词。
- Real-word Errors真词错误:
- 印刷错误:three->there
- 认知错误(同音异形字):piece -> peace; too -> two
- 检测方法:由于每个真词可能都是一个错误词,因此我们为每个词都产生一个候选集,包括该词本身、跟该词发音或拼写相似的词(编辑距离为1的英文单词)、同音异形词。
- 校正方法:按照信道噪声或者分类器选择最好的候选词。
一、非词错误校正
基本方法:使用The Noisy Channel Model of Spelling信道噪声模型
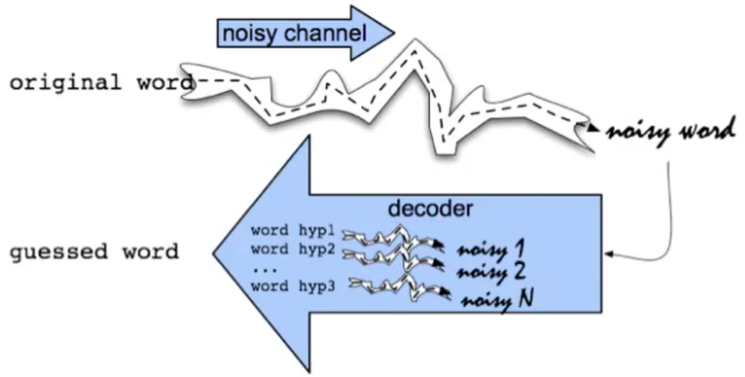
假设初始词经过一个噪声信道输出一个噪声词,即为可能的错误词,我们旨在对该噪声信道建模,从而使得在解码阶段能够根据噪声词得到一个猜测词,其跟初始词一致,即找到错误词正确的拼写。
而信道噪声我们视之为一个概率模型,如下:
输入:一个错误词x
旨在:找到一正确的词w
要求:
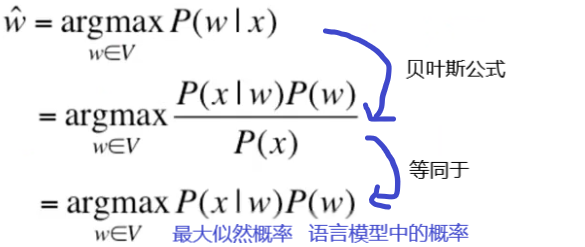
P(w)称为语言模型表示单词w为一个单词的概率,P(x|w)称为信道概率(或错误概率)表示如果是w,x是w拼错的词的概率。
例子:
设:有一个错误词“acress”
1. 产生候选词:
- 相似拼写词:跟错误词之间小的编辑距离
- 采用Damerau-Levenshtein edit distance,计算的操作包括:插入、删除、置换和两个相邻字母之间的换位transposition,
- 以下是与“acress”编辑距离=1的列表:
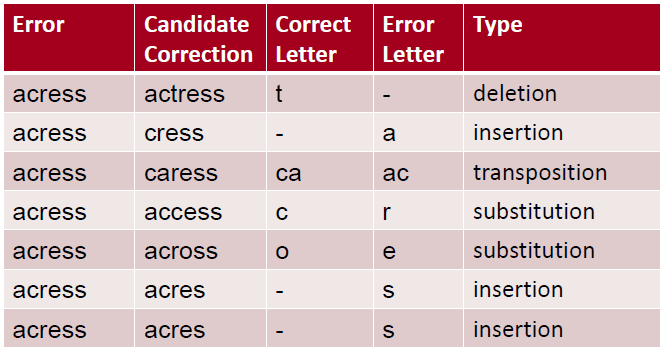
- 80%错误词与正确词之间的编辑距离为1,大部分的编辑距离都小于等于2
- 允许插入空格或者连字符-:thisidea -> this idea; inlaw -> in-law
- 相似发音词:跟错误词的发音之间小的编辑距离
2. 选择最优候选词:套用公式
a) 计算语言模型P(w):可以采用之前说过的任一语言模型,比如unigram、bigram、trigram,大规模拼写校正也可以采用stupid backoff。
b) 计算信道概率P(x|w):首先获得多个单词拼错的列表,然后计算混淆矩阵,然后按照混淆矩阵计算信道概率。
设:
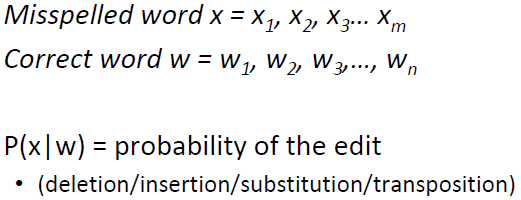
有:

x和y为任一字母a-z,计数count表示后面那张情况发生的次数,其中插入和删除的情况都依赖于前一个字符,sub[x,y]的混淆矩阵结果如下:

然后按照上述混淆矩阵计算信道概率:
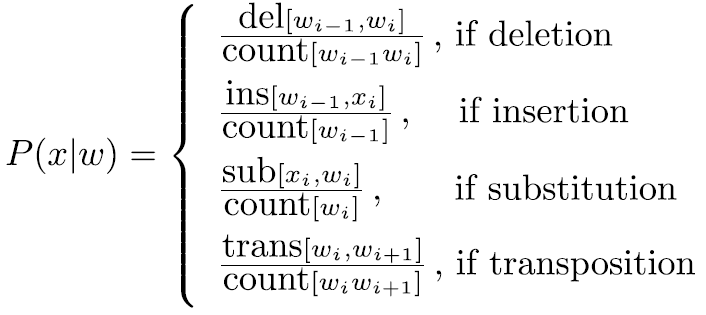
c) 整体概率计算实例如下:

也可以选用语言模型计算整体概率,比如:使用bigram或trigram语言模型

3. 结果评估方法:
使用拼写错误测试集:

二、真词校正
25-40%的拼写错误都是真词错误。
具体步骤:

实例:
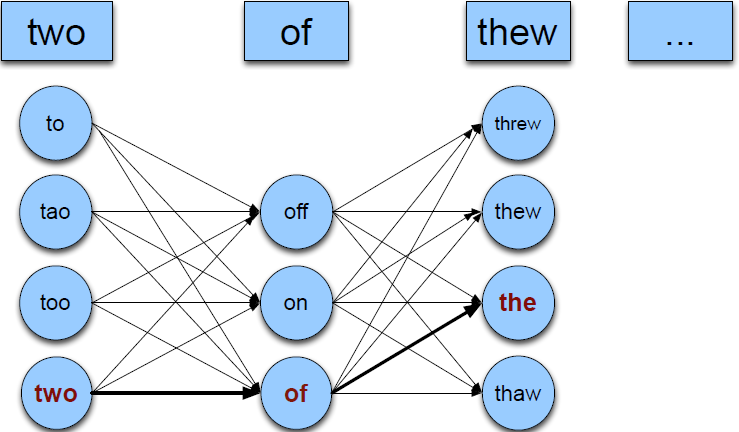
为了方便起见,我们假定每个句子中只有一个拼写错误,所以有:

要求从中找到一个组合序列使得序列的概率最高。
计算P(W):
方法1:语言模型,比如unigram、bigram等
方法2:信道模型:跟“一”中的方法一样,但还需要额外计算没有错误的概率P(w|w),因为候选集中还包括自身词。
计算P(w|w):其完全依赖于应用本身,表示一个词可能被拼错的概率,不同的应用概率不同:

三、经典系统state of art
1. HCI issues in spelling
- 如果对校正结果非常自信:自动校正
- 一般自信:给定一个最好的校正方案
- 一点点自信:给定一个校正方案的列表
- 没有自信:给错误词做出标记,不校正
2. 经典噪声信道
实际应用中,信道概率和语言模型概率的权重并非一致,而是采用如下的计算公式:
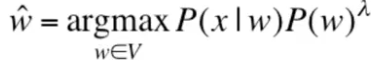
然后在开发测试数据集中训练学习lambdas的值。
3. 语音错误模型
针对有相似发音的错误拼写的纠正
a) Metaphone, used in GNU aspell
- 将错误拼写转换为变音发音,规则如下:

- 然后找到跟错误拼写的发音的编辑距离为1-2的词
- 给结果列表打分,按照:
- 候选词跟错误词之间的加权编辑距离
- 候选词的发音与错误词发音的编辑距离
4. 信道模型的升级版
a) 允许更多的操作(Brill and Moore 200)

b) 在信道中结合发音(Toutanova and Moore 2003)
c)在计算信道概率P(x|w)时考虑更多的影响因素

5. 基于分类器的真词拼写校正方法
- 考虑更多的特征
- 针对特定词对建立分类器
【NLP_Stanford课堂】拼写校正的更多相关文章
- 【NLP_Stanford课堂】语言模型1
一.语言模型 旨在:给一个句子或一组词计算一个联合概率 作用: 机器翻译:用以区分翻译结果的好坏 拼写校正:某一个拼错的单词是这个单词的概率更大,所以校正 语音识别:语音识别出来是这个句子的概率更大 ...
- 【NLP_Stanford课堂】最小编辑距离
一.什么是最小编辑距离 最小编辑距离:是用以衡量两个字符串之间的相似度,是两个字符串之间的最小操作数,即从一个字符转换成另一个字符所需要的操作数,包括插入.删除和置换. 每个操作数的cost: 每个操 ...
- 【NLP_Stanford课堂】语言模型2
一.如何评价语言模型的好坏 标准:比起语法不通的.不太可能出现的句子,是否为“真实”或"比较可能出现的”句子分配更高的概率 过程:先在训练数据集上训练模型的参数,然后在测试数据集上测试模型的 ...
- 【NLP_Stanford课堂】情感分析
一.简介 实例: 电影评论.产品评论是positive还是negative 公众.消费者的信心是否在增加 公众对于候选人.社会事件等的倾向 预测股票市场的涨跌 Affective States又分为: ...
- 【NLP_Stanford课堂】文本分类2
一.实验评估参数 实验数据本身可以分为是否属于某一个类(即correct和not correct),表示本身是否属于某一类别上,这是客观事实:又可以按照我们系统的输出是否属于某一个类(即selecte ...
- 【NLP_Stanford课堂】文本分类1
文本分类实例:分辨垃圾邮件.文章作者识别.作者性别识别.电影评论情感识别(积极或消极).文章主题识别及任何可分类的任务. 一.文本分类问题定义: 输入: 一个文本d 一个固定的类别集合C={c1,c2 ...
- 【NLP_Stanford课堂】语言模型4
平滑方法: 1. Add-1 smoothing 2. Add-k smoothing 设m=1/V,则有 从而每一项可以跟词汇表的大小相关 3. Unigram prior smoothing 将上 ...
- 【NLP_Stanford课堂】语言模型3
一.产生句子 方法:Shannon Visualization Method 过程:根据概率,每次随机选择一个bigram,从而来产生一个句子 比如: 从句子开始标志的bigram开始,我们先有一个( ...
- 【NLP_Stanford课堂】句子切分
依照什么切分句子——标点符号 无歧义的:!?等 存在歧义的:. 英文中的.不止表示句号,也可能出现在句子中间,比如缩写Dr. 或者数字里的小数点4.3 解决方法:建立一个二元分类器: 检查“.” 判断 ...
随机推荐
- jenkins+Publish Over SSH 提示:Transferred 0 file(s)
之前公司用jekins来进行自动化发布,现在公司因没有运维,所以自己学习.并搭建了一个jenkins的环境来进行项目自动化部署. 不料在最后连接ssh后部署时,一直提示Transferred 0 fi ...
- uipath接入Python
安装UiPath.Python.Activities,然后会有五个.Activities,他们的功能分别如下: 本人原创,转发或引用请注明出处.
- 使用swiper来实现轮播图
使用swiper来实现轮播图 swiper实现轮播图几乎是没有一点点技术含量,但是用起来却很方便,包括对移动端的支持也很好. 由于简单这里当然就不会去详细介绍了,推荐两个网址: 1.http://ww ...
- MySQL prompt提示符总结
A counter that increments for each statement you issue \D 当前日期 \d 当前数据库 \h 数据库主机 \l The current de ...
- 028-applicationContext.xml配置文件
版本一 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns:xsi="http: ...
- Django多进程日志文件问题
Django多进程日志文件问题 最近使用Django做一个项目.在部署的时候发现日志文件不能滚动(我使用的是RotatingFileHandler),只有一个日志文件. 查看Log发现一个错误消息:P ...
- mysql 5.6 windows7 解压缩版安装的坑
从官网下载了解压缩版的mysql ,解压缩后,配置好环境变量,运行安装命令,提示我 缺失ddl文件,然后百度,找到了一个windows 系统组件扫描安装缺失组件的程序,然后继续安装,遇到了 初始化密码 ...
- 【.Net】 【C++】容器类型对照
C# 中主要有两类容器:一个是 System.Array 类(参阅:http://msdn.microsoft.com/library/default.asp?url=/library/en-us/c ...
- WPF Window对象的生命周期
WPF中所有窗口的基类型都是System.Windows.Window.Window通常用于SDI(SingleDocumentInterface).MDI(MultipleDocumentInter ...
- Firebird Fluentdata
Fluentdata 支持很多种数据库驱动,但对Firebird不友好,不过可以使用DB2Provider来操作大部分功能, 例如: new DbContext().ConnectionString( ...