xgboost 特征选择,筛选特征的正要性
import pandas as pd
import xgboost as xgb
import operator
from matplotlib import pylab as plt def ceate_feature_map(features):
outfile = open('xgb.fmap', 'w')
i = 0
for feat in features:
outfile.write('{0}\t{1}\tq\n'.format(i, feat))
i = i + 1 outfile.close() def get_data():
train = pd.read_csv("../input/train.csv") features = list(train.columns[2:]) y_train = train.Hazard for feat in train.select_dtypes(include=['object']).columns:
m = train.groupby([feat])['Hazard'].mean()
train[feat].replace(m,inplace=True) x_train = train[features] return features, x_train, y_train def get_data2():
from sklearn.datasets import load_iris
#获取数据
iris = load_iris()
x_train=pd.DataFrame(iris.data)
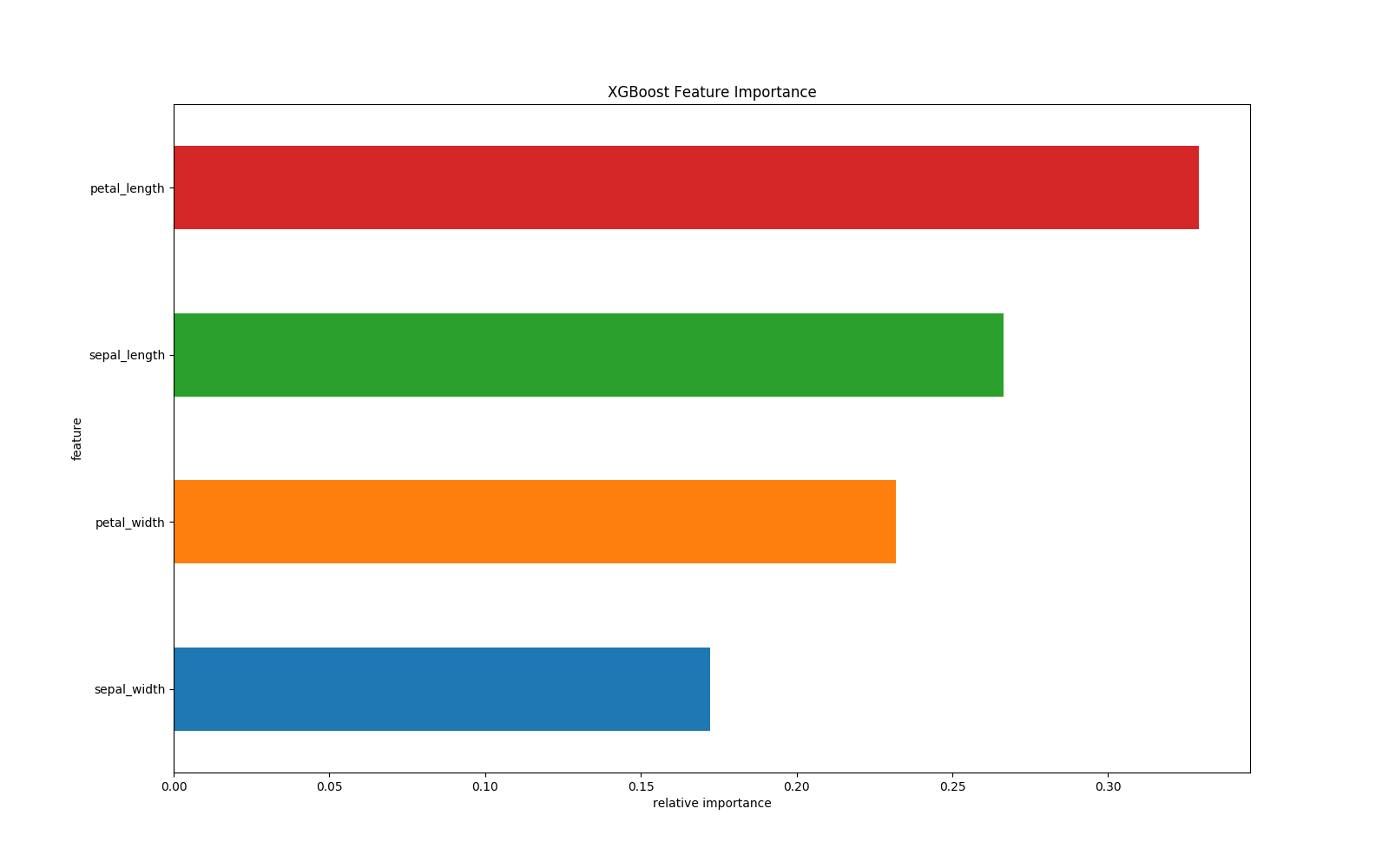
features=["sepal_length","sepal_width","petal_length","petal_width"]
x_train.columns=features
y_train=pd.DataFrame(iris.target)
return features, x_train, y_train #features, x_train, y_train = get_data()
features, x_train, y_train = get_data2()
ceate_feature_map(features) xgb_params = {"objective": "reg:linear", "eta": 0.01, "max_depth": 8, "seed": 42, "silent": 1}
num_rounds = 1000 dtrain = xgb.DMatrix(x_train, label=y_train)
gbdt = xgb.train(xgb_params, dtrain, num_rounds) importance = gbdt.get_fscore(fmap='xgb.fmap')
importance = sorted(importance.items(), key=operator.itemgetter(1)) df = pd.DataFrame(importance, columns=['feature', 'fscore'])
df['fscore'] = df['fscore'] / df['fscore'].sum() plt.figure()
df.plot()
df.plot(kind='barh', x='feature', y='fscore', legend=False, figsize=(16, 10))
plt.title('XGBoost Feature Importance')
plt.xlabel('relative importance')
plt.gcf().savefig('feature_importance_xgb.png')
根据结构分数的增益情况计算出来选择哪个特征的哪个分割点,某个特征的重要性,就是它在所有树中出现的次数之和。
参考:https://blog.csdn.net/q383700092/article/details/53698760
另外:使用xgboost,遇到一个问题

D:\Program\Python3.5\lib\site-packages\sklearn\cross_validation.py:44: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.
"This module will be removed in 0.20.", DeprecationWarning)
先卸载原先版本的xgboost, pip uninstall xgboost
然后下载安装新版本的xgboost,地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost
命令:pip install xgboost-0.6-cp35-none-win_amd64.whl
xgboost 特征选择,筛选特征的正要性的更多相关文章
- XGBoost 输出特征重要性以及筛选特征
1.输出XGBoost特征的重要性 from matplotlib import pyplot pyplot.bar(range(len(model_XGB.feature_importances_) ...
- XGBoost特征选择
1. 特征选择的思维导图 2. XGBoost特征选择算法 (1) XGBoost算法背景 2016年,陈天奇在论文< XGBoost:A Scalable Tree Boosting Sys ...
- Java面向对象设计主要有三大特征:封装性、继承性和多态性
Java面向对象设计主要有三大特征:封装性.继承性和多态性 一 封装性 1.1 概念:它是将类的一些敏感信息隐藏在类的类部,不让外界直接访问到,但是可以通过getter/setter方法间接访 ...
- Java学习:面向对象三大特征:封装性、继承性、多态性之多态性。
面向对象三大特征:封装性.继承性.多态性之多态性. extends继承或者implemens实现,是多态性的前提. 例如:小菜是一个学生,但同时也是一个人.小菜是一个对象,这个对象既有学生形态,也有人 ...
- Java学习:面向对象的三大特征:封装性、继承性、多态性之继承性
面向对象的三大特征:封装性.继承性.多态性. 继承 继承是多态的前提 ,如果没有继承,就没有多态. 继承主要解决的问题就是:共性抽取. 继承关系当中的特点: 子类可以拥有父类的“内容” 子类还可以拥有 ...
- 模式识别原理(Pattern Recognition)、概念、系统、特征选择和特征
§1.1 模式识别的基本概念 一.广义定义 1.模式:一个客观事物的描述,一个可用来仿效的完善的例子. 2.模式识别:按哲学的定义是一个“外部信息到达感觉器官,并被转换成有意义的感觉经验”的过程. 例 ...
- 机器学习实战基础(十四):sklearn中的数据预处理和特征工程(七)特征选择 之 Filter过滤法(一) 方差过滤
Filter过滤法 过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法.它是根据各种统计检验中的分数以及相关性的各项指标来选择特征 1 方差过滤 1.1 VarianceThreshold ...
- 机器学习之路:python 特征降维 特征筛选 feature_selection
特征提取: 特征降维的手段 抛弃对结果没有联系的特征 抛弃对结果联系较少的特征 以这种方式,降低维度 数据集的特征过多,有些对结果没有任何关系,这个时候,将没有关系的特征删除,反而能获得更好的预测结果 ...
- 机器学习实战基础(十八):sklearn中的数据预处理和特征工程(十一)特征选择 之 Wrapper包装法
Wrapper包装法 包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择.但不 ...
随机推荐
- CentOS7.0使用Yum安装Nginx
安装Nginx yum install nginx 正常情况下必定是: 已加载插件:fastestmirror, langpacks base | 3.6 kB 00:00:00 docker-mai ...
- git回溯到指定版本
git回溯到指定版本 git log命令查看仓库日志 然后使用git checkout 命令 例如回溯到上图中的版本 git checkout 12db5d6fd138922a8aaf2214c84c ...
- Future使用场景与分析
前面分享了CountDownLatch的用法,但是由于分享过程中,发现有些朋友,问我Future与CountDownLatch的有什么区别? 答案:只是concurrent包下的并发帮助工具类,两者并 ...
- 【模拟】Friday the Thirteenth
题目描述 Is Friday the 13th really an unusual event?That is, does the 13th of the month land on a Friday ...
- Oracle PL/SQL DBA 编程实践基础
[附:一文一图]
- 访问控制技术- 标准IP访问列表
1.设置pc IP 网关 192.168.1.1 192.168.1.254 192.168.1.2 192.168.1.254 192.168.3.1 192.168.3.254 2.设置交换机借 ...
- Ubuntu 16.04/CentOS 6.9安装Apache压力(并发)测试工具ab
说明: ab工具已经在Apache中包含,如果不想安装Apache,那么可以使用下面方法单独安装. 安装: Ubuntu: sudo apt-get install apache2-utils Cen ...
- 磁盘爆满导致MySQL无法启动:Disk is full writing './mysql-bin.~rec~' (Errcode: 28). Waiting for someone to free space...
今天收到监控邮件说博客访问失败.打开页面一看,硕大的502 Bad Gateway,ping了一下VPS发现是通的,SSH连接上去看了下Nginx日志发现没问题,重启lnmp的时候发现Mysql起不来 ...
- Console-算法:fun1(do while)
ylbtech-Arithmetic:Console-算法[do while]-XX 1.A,Demo(案例) 1.B,Solution(解决方案) using System; namespace ...
- Java:网络编程之登陆服务器
1. 客服端:浏览器(telnet) 服务端:自定义 2. 客服端:浏览器 服务端:TomCat服务器 3. 客服端:自定义 服务端:TomCat服务器 //例子如下: import java.n ...