【转】K-Means聚类算法原理及实现
k-means 聚类算法原理:
1、从包含多个数据点的数据集 D 中随机取 k 个点,作为 k 个簇的各自的中心。
2、分别计算剩下的点到 k 个簇中心的相异度,将这些元素分别划归到相异度最低的簇。两个点之间的相异度大小采用欧氏距离公式衡量,对于两个点 T0(x1,y2)和 T1(x2,y2),T0 和 T1 之间的欧氏距离为:
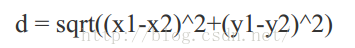
欧氏距离越小,说明相异度越小
3、根据聚类结果,重新计算 k 个簇各自的中心,计算方法是取簇中所有点各自维度的算术平均数。
4、将 D 中全部点按照新的中心重新聚类。
5、重复第 4 步,直到聚类结果不再变化。
6、将结果输出。
举例说明, 假设包含 9 个点数据 D 如下(见 simple_k-means.txt), 从 D 中随机取 k 个元素,作为 k 个簇的各自的中心, 假设选 k=2, 即将如下的 9 个点聚类成两个类(cluster)
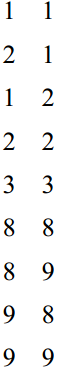
1.假设选 C0(1 1)和 C1(2 1)前两个点作为两个类的簇心。
2. 分别计算剩下的点到 k 个簇中心的相异度,将这些元素分别划归到相异度最低的簇。结果为:

3.根据 2 的聚类结果,重新计算 k 个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数。
C0 新的簇心为: 1.0,1.5
C1 新的簇心为: 5.857142857142857, 5.714285714285714
4.将 D 中全部元素按照新的中心重新聚类。
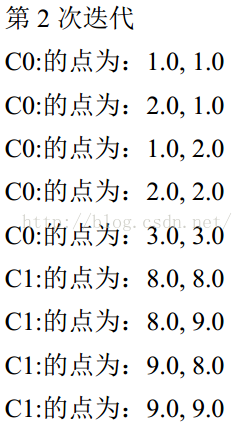
5.重复第 4 步,直到聚类结果不再变化。当每个簇心点前后移动的距离小于某个阈值t的时候,就认为聚类已经结束了,不需要再迭代,这里的值选t=0.001,距离计算采用欧氏距离。
C0 的簇心为: 1.6666666666666667, 1.75
C1 的簇心为: 7.971428571428572, 7.942857142857143
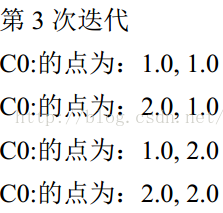
C0 的簇心为: 1.777777777777778, 1.7916666666666667
C1 的簇心为: 8.394285714285715, 8.388571428571428
C0 的簇心为: 1.7962962962962965, 1.7986111111111114
C1 的簇心为: 8.478857142857143, 8.477714285714285

C0 的簇心为: 1.799382716049383, 1.7997685185185184
C1 的簇心为: 8.495771428571429, 8.495542857142857
C0 的簇心为: 1.7998971193415638, 1.7999614197530864
C1 的簇心为: 8.499154285714287, 8.499108571428572
#include <iostream>
#include <cstdlib>
#include <ctime>
#include <vector>
#include <cmath> using namespace std; class Cluster//聚类,每个聚类都包含两个属性,一个是簇心的属性(维数),另一个是距离本簇心最近的样本点
{
public:
vector <double> centroid;//存放簇心的属性(维数)
vector <int> samples;//存放属于相同簇心样本的下标
}; double CalculateDistance(vector<double> a, vector<double> b)//计算两个向量之间的距离
{
int len1 = a.size();
int len2 = b.size();
if(len1 != len2)
cerr<<"Dimensions of two vectors must be same!!\n";
double temp = 0;
for(int i = 0; i < len1; ++i)
temp += pow(a[i]-b[i], 2);
return sqrt(temp);
} //max_iteration表示最大的迭代次数,min_move_distance
vector<Cluster> KMeans(vector<vector<double> >data_set, int k, int max_iteration, double threshold)
{
int row_number = data_set.size();//数据的个数
int col_number = data_set[0].size();//每个向量(属性)的维数 //初始随机选取k个质心
vector<Cluster> cluster(k);//存放k个簇心。vector<T> v(n,i)形式,v包含n 个值为 i 的元素
srand((int)time(0));
for(int i = 0; i < k; ++i)
{
int c = rand()%row_number;
cluster[i].centroid = data_set[c];//把第c个作为簇心,并把它相应的属性赋值给centroid
} //iteration
int iter = 0;
while(iter < max_iteration)
{
iter++;
for(int i = 0; i < k; ++i)
cluster[i].samples.clear();
//找出每个样本点所属的质心
for(int i = 0; i < row_number; ++i)
{
double min_distance = INT_MAX;
int index = 0;
//计算离样本点i最近的质心
for(int j = 0; j < k; ++j)
{
double temp_distance = CalculateDistance(data_set[i], cluster[j].centroid);
if(min_distance > temp_distance)
{
min_distance = temp_distance;
index = j;
}
}
cluster[index].samples.push_back(i);//把第i个样本点放入,距离其最近的质心的samples
} double max_move_distance = INT_MIN;
//更新簇心
for(int i = 0; i < k; ++i)
{
vector<double> temp_value(col_number, 0.0);
for(int num = 0; num < cluster[i].samples.size(); ++num)//计算每个样本的属性之和
{
int temp_same = cluster[i].samples[num];
for(int j = 0; j < col_number; ++j)
temp_value[j] += data_set[temp_same][j];
}
vector<double> temp_centroid = cluster[i].centroid;
for(int j = 0; j < col_number; ++j)
cluster[i].centroid[j] = temp_value[j]/cluster[i].samples.size();
//计算从上一个簇心移动到当前新的簇心的距离
double temp_distance = CalculateDistance(temp_centroid, cluster[i].centroid);
if(max_move_distance < temp_distance)
max_move_distance = temp_distance;
}
if(max_move_distance < threshold)
break;
}
return cluster;
} int main()
{
int threshold = 0.001;//当从上一个簇心移动到当前粗心的距离几乎不变时,可以结束。这里用threshold作为阈值
vector <vector<double> >data_set(9, vector<double>(2, 0.0));
int point_number;
cin>>point_number;
for(int i = 0; i < point_number; ++i)
{
for(int j = 0; j < 2; ++j)
cin>>data_set[i][j];
} int col = data_set[0].size();
vector<Cluster> cluster_res = KMeans(data_set, 2, 200, threshold);
for(int i = 0; i < cluster_res.size(); ++i)
{
cout<<"Cluster "<<i<<" : "<<endl;
cout<<"\t"<<"Centroid: ";//<<endl;
cout<<"(";
for(int j = 0; j < cluster_res[i].centroid.size()-1; ++j)
cout<< cluster_res[i].centroid[j]<<",";
cout<<cluster_res[i].centroid[cluster_res[i].centroid.size()-1]<<")"<<endl;
cout<<"\t"<<"Samples: ";
for(int j = 0; j < cluster_res[i].samples.size(); ++j)
{
int c = cluster_res[i].samples[j];
cout<<"(";
for(int m = 0; m < col-1; ++m)
cout<<data_set[c][m]<<",";
cout<<data_set[c][col-1]<<") ";
}
cout<<endl;
}
return 0;
} /**
1 1
2 1
1 2
2 2
3 3
8 8
8 9
9 8
9 9
*/
运行结果:
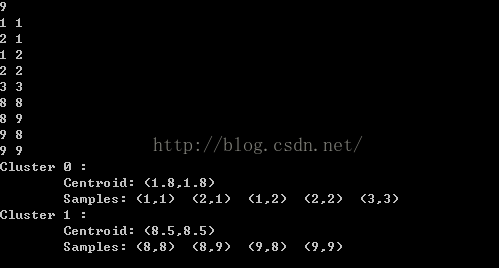
转发自:https://blog.csdn.net/hearthougan/article/details/52932452
【转】K-Means聚类算法原理及实现的更多相关文章
- Kmeans聚类算法原理与实现
Kmeans聚类算法 1 Kmeans聚类算法的基本原理 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一.K-means算法的基本思想是:以空间中k个点为中心进行聚类,对 ...
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- OPTICS聚类算法原理
OPTICS聚类算法原理 基础 OPTICS聚类算法是基于密度的聚类算法,全称是Ordering points to identify the clustering structure,目标是将空间中 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 【机器学习】:Kmeans均值聚类算法原理(附带Python代码实现)
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
- BIRCH聚类算法原理
在K-Means聚类算法原理中,我们讲到了K-Means和Mini Batch K-Means的聚类原理.这里我们再来看看另外一种常见的聚类算法BIRCH.BIRCH算法比较适合于数据量大,类别数K也 ...
- K-Means聚类算法原理
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means算法有大量的变体,本文就从最传统的K-Means算法讲起,在其基础上讲述K-Means的优化变体 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
随机推荐
- Linux网络编程基础API
第5章 Linux网络编程基础API 探讨Linux网络编程基础API与内核中TCP/IP协议族之间的关系,并未后续章节提供编程基础.从3个方面讨论Linux网络API. socket地址API.so ...
- Spring AOP中使用@Aspect注解 面向切面实现日志横切功能详解
引言: AOP为Aspect Oriented Programming的缩写,意为:面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术.AOP是OOP的延续,是软件开发中的一 ...
- 《 .NET内存宝典》阅读指南 - 第1章
先发表生成URL以印在书里面.等书籍正式出版销售后会公开内容.
- 练手WPF(四)——贪吃蛇小游戏的简易实现(上)
一. 游戏界面首先,按照惯例,编辑MainWindow.xaml,先将游戏界面制作好.非常简单:(1)主游戏区依然使用我们熟悉的Canvas控件,大小为640X480像素,设定每小格子为20px,所以 ...
- 你不知道的Go unsafe.Pointer uintptr原理和玩法
unsafe.Pointer 这个类型比较重要,它是实现定位和读写的内存的基础,Go runtime大量使用它.官方文档对该类型有四个重要描述: (1)任何类型的指针都可以被转化为Pointer (2 ...
- 纯C语言实现循环双向链表创建,插入和删除
#include <stdio.h> #include <stdlib.h> typedef int ElemType; typedef struct DLNode{ Elem ...
- Python【day 11】迭代器
迭代器-用 1.迭代器的概念 1.可迭代对象-iterable str.list.tuple.dict.set.open().range() 2.可迭代对象的概念: 其数据类型的执行方法中含有__it ...
- git使用读书笔记
Normal 0 7.8 磅 0 2 false false false EN-US ZH-CN X-NONE /* Style Definitions */ table.MsoNormalTable ...
- 初识.netCore以及如何vs2019创建项目和发布
一:什么是.netCore 从图上得知,.NetCore是同.NetFramework一样也是一种框架,并且都是基于.Net Standard Library,前面我们有用过.netFramwork来 ...
- python之便携式mysql类和tornado mysql长链接
mymysql.py class MyMysql2(object): def __init__(self, host = '', user = '', passwd = '', db = '', po ...