【原创】大数据基础之Azkaban(1)简介、源代码解析
Azkaban3.45
一 简介
1 官网
Azkaban was implemented at LinkedIn to solve the problem of Hadoop job dependencies. We had jobs that needed to run in order, from ETL jobs to data analytics products.
Initially a single server solution, with the increased number of Hadoop users over the years, Azkaban has evolved to be a more robust solution.
Azkaban是由LinkedIn为了解决Hadoop环境下任务依赖问题而开发的,LinkedIn团队有很多任务需要按照顺序运行,包括ETL任务以及数据分析任务;
Azkaban一开始是单server方案,现在已经演化为一个更健壮的方案;(可惜当前版本的WebServer还是单点)
Azkaban consists of 3 key components:
- Relational Database (MySQL)
- AzkabanWebServer
- AzkabanExecutorServer
Azkaban有3个核心组件:Mysql、WebServer、ExecutorServer;
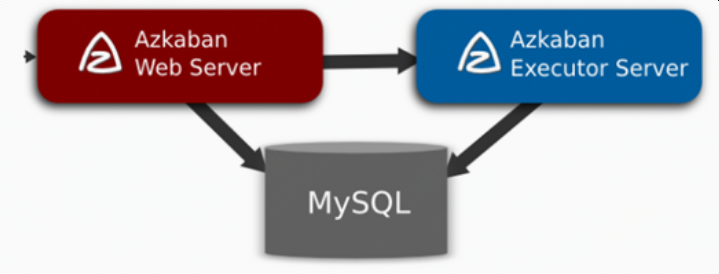
2 部署
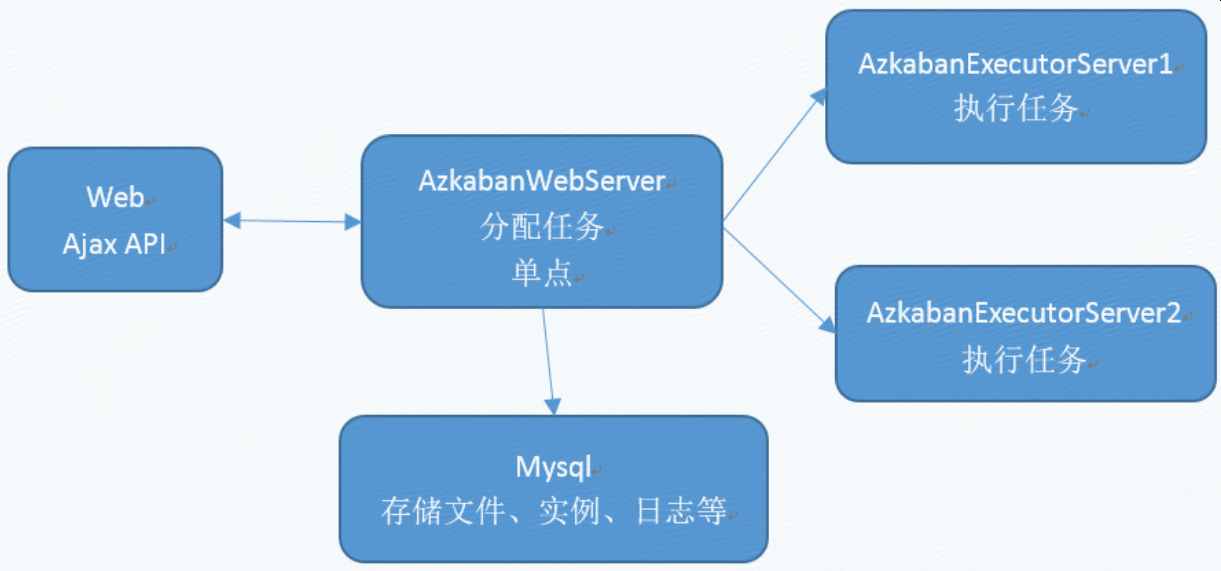
3 数据库表结构
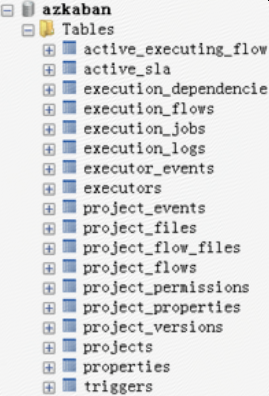
projects:项目
project_flows:工作流定义
execution_flows:工作流实例
execution_jobs:任务实例
triggers:调度定义
ps:表中很多数据都是编码的,enc_type是编码类型(对应的枚举为EncodingType),2是gzip编码,其他为无编码,2需要调用GZIPUtils.transformBytesToObject解析得到原始字符串;
4 概念
l Job:最小的执行单元,作为DAG的一个结点,即任务
l Flow:由多个Job组成,并通过dependent配置Job的依赖属性,即工作流
l Tirgger:根据指定Cron信息触发Flow,即调度
二 代码解析
1 启动过程
Web Server
AzkabanWebServer.main
launch
prepareAndStartServer
configureRoutes
TriggerManager.start
FlowTriggerService.start
recoverIncompleteTriggerInstances
SELECT %s FROM execution_dependencies WHERE trigger_instance_id in (SELECT trigger_instance_id FROM execution_dependencies WHERE dep_status = %s or dep_status = %s or (dep_status = %s and flow_exec_id = %s))
FlowTriggerScheduler.start
ExecutorManager
setupExecutors
loadRunningFlows
QueueProcessorThread.run
ExecutingManagerUpdaterThread.run
Executor Server
AzkabanExecutorServer.main
launch
AzkabanExecutorServer.start
insertExecutorEntryIntoDB
2 工作流执行过程
Web Server两个入口:
ExecuteFlowAction.doAction
ExecutorServlet.ajaxExecuteFlow
Web Server分配任务:
ExecutorManager.submitExecutableFlow
JdbcExecutorLoader.uploadExecutableFlow
INSERT INTO execution_flows (project_id, flow_id, version, status, submit_time, submit_user, update_time) values (?,?,?,?,?,?,?)
ExecutorLoader.addActiveExecutableReference
INSERT INTO active_executing_flows (exec_id, update_time) values (?,?)
queuedFlows.enqueue
QueueProcessorThread.run
processQueuedFlows
ExecutorManager.selectExecutorAndDispatchFlow (get from queuedFlows)
selectExecutor
dispatch
JdbcExecutorLoader.assignExecutor
UPDATE execution_flows SET executor_id=? where exec_id=?
ExecutorApiGateway.callWithExecutable (调用Executor Server)
Executor Server执行任务:
ExecutorServlet.doGet
handleAjaxExecute
FlowRunnerManager.submitFlow
JdbcExecutorLoader.fetchExecutableFlow
SELECT exec_id, enc_type, flow_data FROM execution_flows WHERE exec_id=?
FlowPreparer.setup
FlowRunner.run
setupFlowExecution
updateFlow
UPDATE execution_flows SET status=?,update_time=?,start_time=?,end_time=?,enc_type=?,flow_data=? WHERE exec_id=?
runFlow
progressGraph
runReadyJob
runExecutableNode
JobRunner.run
uploadExecutableNode
INSERT INTO execution_jobs (exec_id, project_id, version, flow_id, job_id, start_time, end_time, status, input_params, attempt) VALUES (?,?,?,?,?,?,?,?,?,?)
prepareJob
runJob
Job.run (ProcessJob, JavaJob)
Web Server轮询流程状态:
ExecutingManagerUpdaterThread.run
getFlowToExecutorMap
ExecutorApiGateway.callWithExecutionId
updateExecution
3 调度执行过程
TriggerManager.start
loadTriggers
SELECT trigger_id, trigger_source, modify_time, enc_type, data FROM triggers
TriggerScannerThread.start
checkAllTriggers
onTriggerTrigger
TriggerAction.doAction
ExecuteFlowAction.doAction
PS:还有另一套完全独立的定时任务逻辑,通过azkaban.server.schedule.enable_quartz控制(默认false),以下为register job到quartz:
ProjectManagerServlet.ajaxHandleUpload
SELECT id, name, active, modified_time, create_time, version, last_modified_by, description, enc_type, settings_blob FROM projects WHERE name=? AND active=true
ProjectManager.loadAllProjectFlows
SELECT project_id, version, flow_id, modified_time, encoding_type, json FROM project_flows WHERE project_id=? AND version=?
FlowTriggerScheduler.scheduleAll
SELECT MAX(flow_version) FROM project_flow_files WHERE project_id=? AND project_version=? AND flow_name=?
SELECT flow_file FROM project_flow_files WHERE project_id=? AND project_version=? AND flow_name=? AND flow_version=?
registerJob
以下为quartz job执行:
FlowTriggerQuartzJob.execute
FlowTriggerService.startTrigger
TriggerInstanceProcessor.processSucceed
TriggerInstanceProcessor.executeFlowAndUpdateExecID
ExecutorManager.submitExecutableFlow
4 任务执行过程
Job是任务的核心接口,所有具体任务都是该接口的子类:
Job
AbstractJob
AbstractProcessJob
ProcessJob (Shell任务)
JavaProcessJob (Java任务)
JavaJob
【原创】大数据基础之Azkaban(1)简介、源代码解析的更多相关文章
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- 【原创】大数据基础之Impala(1)简介、安装、使用
impala2.12 官方:http://impala.apache.org/ 一 简介 Apache Impala is the open source, native analytic datab ...
- 【原创】大数据基础之Benchmark(2)TPC-DS
tpc 官方:http://www.tpc.org/ 一 简介 The TPC is a non-profit corporation founded to define transaction pr ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- 大数据基础知识:分布式计算、服务器集群[zz]
大数据中的数据量非常巨大,达到了PB级别.而且这庞大的数据之中,不仅仅包括结构化数据(如数字.符号等数据),还包括非结构化数据(如文本.图像.声音.视频等数据).这使得大数据的存储,管理和处理很难利用 ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- 大数据基础知识问答----hadoop篇
handoop相关知识点 1.Hadoop是什么? Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速 ...
- hadoop大数据基础框架技术详解
一.什么是大数据 进入本世纪以来,尤其是2010年之后,随着互联网特别是移动互联网的发展,数据的增长呈爆炸趋势,已经很难估计全世界的电子设备中存储的数据到底有多少,描述数据系统的数据量的计量单位从MB ...
- 大数据基础总结---HDFS分布式文件系统
HDFS分布式文件系统 文件系统的基本概述 文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易. 文件名:在文件系统中,文件名是用于定位存储位置. 元数据(Metad ...
随机推荐
- 爬虫基础(三)-----selenium模块应用程序
摆脱穷人思维 <三> : 培养"目标导向"的思维: 好项目永远比钱少,只要目标正确,钱总有办法解决. 一 selenium模块 什么是selenium?seleni ...
- Educational Codeforces Round 62 (Rated for Div. 2) - C Playlist
当时题意看错了...不过大致思路是对的,唯一没有想到的就是用优先队列搞这个东西,真是不该啊... 题意大概就是,有N首歌,N首歌有两个东西,一个是长度Ti,一个是美丽值Bi,你最多可以选择K首歌, 这 ...
- C语言之概述
//添加对函数的说明(规范) #include<stdio.h> /*A simple C progress*/ int main(void) { int num; /*Define an ...
- Flask WTForms的使用和源码分析 —— (7)
Flask-WTF是简化了WTForms操作的一个第三方库.WTForms表单的两个主要功能是验证用户提交数据的合法性以及渲染模板.还有其它一些功能:CSRF保护, 文件上传等.安装方法: pip3 ...
- JS生成 UUID的方法
方法一. function uuid() { var s = []; var hexDigits = "0123456789abcdef"; for (var i = 0; i & ...
- Vue中Vuex的详解与使用(简洁易懂的入门小实例)
怎么安装 Vuex 我就不介绍了,官网上有 就是 npm install xxx 之类的.(其实就是懒~~~哈哈) 那么现在就开始正文部分了 众所周知 Vuex 是什么呢?是用来干嘛的呢? Vuex ...
- Java基础:Java变量、数据类型、运算符(2)
1. 标识符和关键字 1.1 标识符 标识符是用来标识类名.对象名.变量名.方法名.类型名.数组名.文件名的有效序列. Java规定,标识符由字母.数字.下划线“_”.美元符号“$”组成,并且首字母不 ...
- How to Build a Chat Bot Using Azure Bot Service and Train It with LUIS
Introduction If you haven’t had much programming experience before, building a conversational bot an ...
- mysql-python安装时EnvironmentError: mysql_config not found
mysql-python安装时EnvironmentError: mysql_config not found 在安装 mysql-python时,会出现: 复制代码 sh: mysql_config ...
- html5 基础入门
html5 基础入门 前言介绍 HTML5草案的前身名为 Web Applications 1.0,于2004年被WHATWG提出,于2007年被W3C接纳,并成立了新的 HTML工作团队. 如果从狭 ...