XPath语法和lxml模块
XPath语法和lxml模块
什么是XPath?
xpath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历。
XPath开发工具
Chrome插件XPath Helper。
安装方法:
- 打开插件伴侣,选择插件
- 选择提取插件内容到桌面,桌面上会多一个文件夹
- 把文件夹放入想要放的路径下
- 打开谷歌浏览器,选择扩展程序,开发者模式打开,选择加载已解压的扩展程序,选择路径打开即可
Firefox插件Try XPath。
XPath节点
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
XPath语法

使用方式:
使用//获取整个页面当中的元素,然后写标签名,然后在写谓语进行提取,比如:
//title[@lang='en']
//标签[@属性名='属性值']
# 如果想获取html标签下的body标签
html/body
谓语:谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。在下面的表格中,列出了带有谓语的一些路径表达式
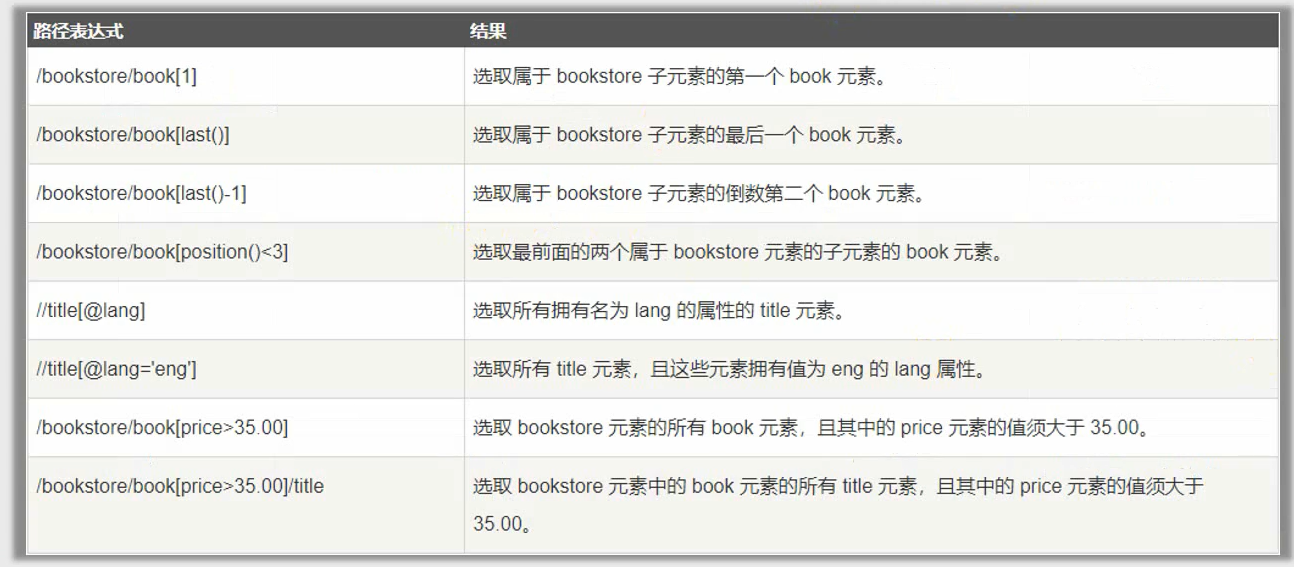
通配符
只要book标签带有属性都可以通过//book[@*]匹配到
选取多个路径
通过在路径表达式中使用|运算符,可以选取若干个路径
# 选取所有book元素以及book元素下所有的title元素
//bookstore/book|//book/title
运算符
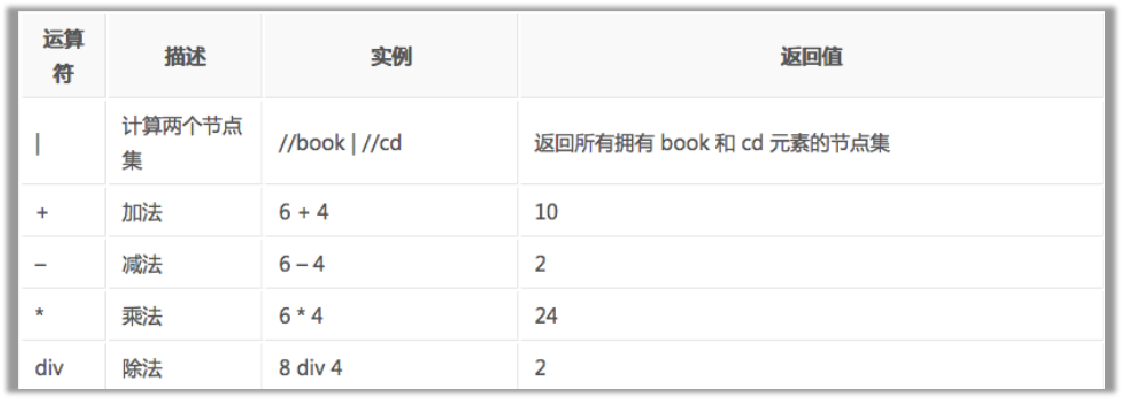
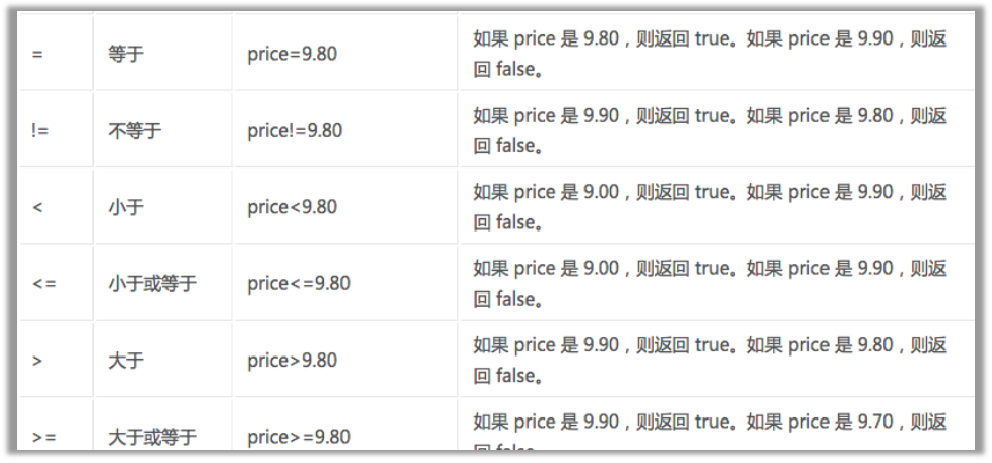

需要注意的知识点:
/和//的区别:/代表只获取子节点,//获取子孙节点,一般//用的比较多,当然也要视情况而定
contains:有时候某个属性中包含了多个值,那么可以使用contains函数,示例如下:
//title[contains(@lang,'en')]
谓词中下标是从1开始的,不是从0开始的
lxml库
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。
lxml python 官方文档:http://lxml.de/index.html
需要安装C语言库,可使用 pip 安装:pip install lxml
基本使用:
我们可以利用他来解析HTML代码,并且在解析HTML代码的时候,如果HTML代码不规范,他会自动的进行补全
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
# 将字符串解析为html文档
html = etree.HTML(text)
print(html)
# 按字符串序列化html
result = etree.tostring(html).decode('utf-8')
print(result)
从文件中读取html代码:
#读取
html = etree.parse('hello.html')
result = etree.tostring(html).decode('utf-8')
print(result)
在lxml中使用xpath语法
<!-- hello.html -->
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
语法练习
from lxml import etree
html = etree.parse('hello.html')
# 获取所有li标签:
# result = html.xpath('//li')
# print(result)
# for i in result:
# print(etree.tostring(i))
# 获取所有li元素下的所有class属性的值:
# result = html.xpath('//li/@class')
# print(result)
# 获取li标签下href为www.baidu.com的a标签:
# result = html.xpath('//li/a[@href="www.baidu.com"]')
# print(result)
# 获取li标签下所有span标签:
# result = html.xpath('//li//span')
# print(result)
# 获取li标签下的a标签里的所有class:
# result = html.xpath('//li/a//@class')
# print(result)
# 获取最后一个li的a的href属性对应的值:
# result = html.xpath('//li[last()]/a/@href')
# print(result)
# 获取倒数第二个li元素的内容:
# result = html.xpath('//li[last()-1]/a')
# print(result)
# print(result[0].text)
# 获取倒数第二个li元素的内容的第二种方式:
result = html.xpath('//li[last()-1]/a/text()')
print(result)
XPath语法和lxml模块的更多相关文章
- Python爬虫 XPath语法和lxml模块
XPath语法和lxml模块 什么是XPath? xpath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历. X ...
- Generator yield语法和 co模块
Generator yield 语法使用,也叫生成器,实际上就是多个异步按顺序执行 1.下面是一个读取两个文件的例子 const fs = require('fs'); const readFile ...
- XPath语法和CSS选择器介绍
XPath语法 XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML 文档中对元素和属性进行遍历.XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 ...
- 洗礼灵魂,修炼python(71)--爬虫篇—【转载】xpath/lxml模块,爬虫精髓讲解
Xpath,lxml模块用法 转载的原因和前面的一样,我写的没别人写的好,所以我也不浪费时间了,直接转载这位崔庆才大佬的 原帖链接:传送门 以下为转载内容: --------------------- ...
- lxml模块(应用xpath技术)
一.lxml介绍 第三方库lxml是第一款表现出高性能特征的python xml库,天生支持Xpath1.0.XSLT1.0.定制元素类,甚至python风格的数据绑定接口.lxml是通过Cpytho ...
- Python爬虫基础——XPath语法的学习与lxml模块的使用
XPath与正则都是用于数据的提取,二者的区别是: 正则:功能相对强大,写起来相对复杂: XPath:语法简单,可以满足绝大部分的需求: 所以,如果你可以根据自己的需要进行选择. 一.首先,我们需要为 ...
- 爬虫(六):XPath、lxml模块
1. XPath 1.1 什么是XPath XPath(XML Path Language) 是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历. 1.2 ...
- 好习惯: 用controller as 语法和$inject数组注入
angular好习惯1: 用controller as 语法和$inject数组注入 1) 像普通的JS类一样实现controller,摆脱$scope 2) 用.$inject数组注入相关模块,便于 ...
- python爬虫网页解析之lxml模块
08.06自我总结 python爬虫网页解析之lxml模块 一.模块的安装 windows系统下的安装: 方法一:pip3 install lxml 方法二:下载对应系统版本的wheel文件:http ...
随机推荐
- 客户端注册 Watcher 实现 ?
1.调用 getData()/getChildren()/exist()三个 API,传入 Watcher 对象 2.标记请求 request,封装 Watcher 到 WatchRegistrati ...
- spring-boot关于spring全注解IOC
什么是IOC容器: Spring IoC 容器是一个管理Bean 的容器,在S pring 的定义中,它要求所有的IoC 容器都需要实现接口BeanFactory ,它是一个顶级容器接口 IoC 是一 ...
- 有哪些不同类型的 IOC(依赖注入)方式?
构造器依赖注入:构造器依赖注入通过容器触发一个类的构造器来实现 的,该类有一系列参数,每个参数代表一个对其他类的依赖.Setter 方法注入:Setter 方法注入是容器通过调用无参构造器或无参 st ...
- AQS 支持两种同步方式?
1.独占式 2.共享式 这样方便使用者实现不同类型的同步组件,独占式如 ReentrantLock,共享式如 Semaphore,CountDownLatch,组合式的如 ReentrantReadW ...
- Effective Java —— 使类和成员的可访问性最小化
本文参考 本篇文章参考自<Effective Java>第三版第十五条"Minimize the accessibility of classes and members&quo ...
- React 可视化开发工具 Shadow Widget 非正经入门(之五:指令式界面设计)
本系列博文从 Shadow Widget 作者的视角,解释该框架的设计要点.本篇解释 Shadow Widget 中类 Vue 的控制指令,与指令式界面设计相关. 1. 指令式界面设计 Vue 与 A ...
- 一块小饼干(Cookie)的故事-上篇
cookie 如果非要用汉语理解的话应该是 一段小型文本文件,由网景的创始人之一的卢 蒙特利在93年发明. 上篇是熟悉一下注册的大致流程,下篇熟悉登录流程以及真正的Cookie 实现基本的注册功能 我 ...
- JDBC/Mybatis连接数据库报错:The server time zone value 'Öйú±ê׼ʱ¼ä' is unrecognized or represents more than one time zone.
造成这个的原因是maven导入MyBatis的时候会自动导入最新版本的8.0.11,然后8.0.11采用了新驱动,之前版本会报错. 当我们使用高版本的MySQL驱动时可以在获取数据库的连接getCon ...
- PAT B1024科学计数法
科学计数法是科学家用来表示很大或很小的数字的一种方便的方法,其满足正则表达式 [+-][1-9].[0-9]+E[+-][0-9]+,即数字的整数部分只有 1 位,小数部分至少有 1 位,该数字及其指 ...
- Javascript中数组的判断方法
摘要: 1.数组检测的方法: 1) typeof . 2) instanceof . 3) constructor . 4) Object.prototype.toString. 5) Array.i ...