Improving Commonsense Question Answering by Graph-based Iterative Retrieval over Multiple Knowledge Sources —— 基于多知识库迭代检索的常识问答系统
基于多知识库迭代检索的问答系统

背景
常识问答任务需要引入外部知识来帮助模型更好地理解自然语言问题,现有的解决方案大都采用两阶段框架:
- 第一阶段 —— 从广泛的知识来源中找到与给定问题相关的知识事实或者用预训练模型生成相关的知识
- 第二阶段 —— 将找到的或者生成的知识与问题融合以预测答案。
实验结果证明,外部知识融合到问答系统的做法是十分有效的,但这仍然存在一个关键的问题:就从单一外部知识库找寻相关知识而言,抽取到的部分知识可能对解决问题基本毫无作用,甚至还可能损害模型的性能。例如,以下面一个QA为例,对于问题实体\(farmland\)和三个选项实体\(midwest \space countryside \space illinois\),从ConceptNet中抽取到的知识显示,\(farmland\)和三个选项实体都直接相关\((AtLocation)\)。

虽然外部知识给到了模型,但模型仍然很难做出正确的选择,因为这三个选项看上去似乎都是正确的。这样的问题在论文中被称为知识的多价值属性,这种问题在问答系统中十分常见,实体关系的多值属性会损害现有模型的性能。
贡献
提出一种新的多知识源问答方法,通过利用多种知识来源,在所需的背景知识和原始问题以及选择之间建立精确的联系,以解决多值属性带来的挑战。
三个创新:
- 提出基于图的迭代检索模块 —— 通过问题中实体之间的隐藏关系来缩小和细化潜在的有用知识事实
- 引入词典为实体或者概念提供解释 —— 综合实体或概念解释和迭代检索的知识事实可以帮助模型精确区分欺骗性的答案选择
- 提出答案选择感知注意力机制 —— 在将隐层状态向量输入最终预测的线性分类器之前,引入答案选择感知注意机制来计算给定问题、检索的知识和候选选择的各自的隐层向量之间的注意力分数
框架
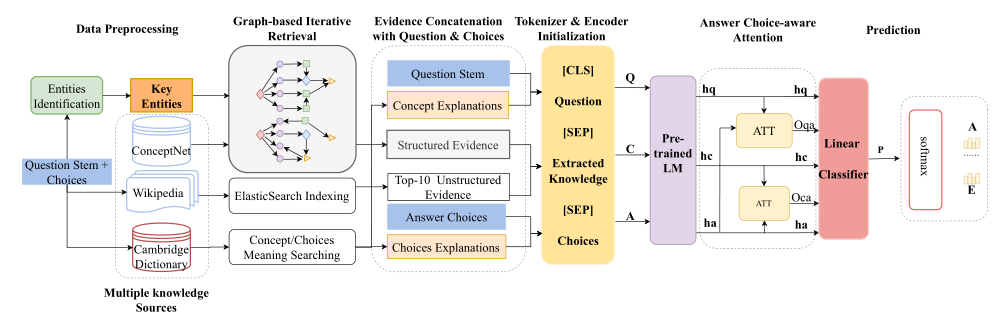
仍然采用两阶段的框架(默认已经进行了对QA对的实体识别):
第一阶段 —— 从多个外部知识库中抽取与QA对相关的知识,这部分大多是在检索知识
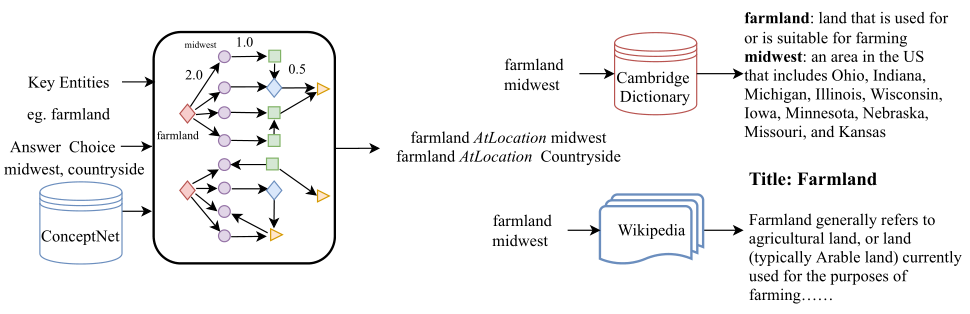
- 结构化证据 —— 从ConceptNet中找到问题概念和识别的关键实体(包含选项实体),并把它们作为初始节点。根据问题的类型,使用基于规则的方法推断可能的关系,并使用这些关系来缩小知识提取的范围。基于初始节点和潜在关系,迭代地检索与问题相关的知识事实。
- 非结构化证据 —— 将维基百科文档拆分成句子,使用ElasticSearch构建索引。根据原问题检索相关句子,使用标题和段落缩小文档的范围。然后使用段落级候选词和它们的句子来建立索引,并检索前10个相关的句子
- 实体或概念解释 —— 从字典中提取答案选择和问题概念的含义,帮助模型区分分散注意力的实体
第二阶段 —— 用预训练模型对构造的输入进行编码,将编码后的三个隐层向量通过一个答案选择感知注意力计算注意力得分,最终输入到分类器中得到QA对的得分。
- 输入构造 —— \([CLS] \space Question \space [SEP] \space Extracted \space Knowledge \space [SEP] \space Choices\)
- 答案选择感知注意力机制 —— 主要是计算QA对各自隐层向量的注意力系数以及证据和选项各自隐层向量的注意力系数,最后串接加权后的问题隐层向量\(O_{qa}h_{q}\)和加权后的证据隐层向量\(O_{ca}h_{c}\)以及选项隐层向量\(h_{a}\)
多源知识库
结构化的ConceptNet、非结构化的Wikipedia以及剑桥词典(Cambridge Dictionary)。
- ConceptNet —— 最大的结构化知识库之一,知识主要来自其他众包资源、专家创造的资源
- Wikipedia —— 一个免费的在线百科全书,由世界各地的志愿者创建和编辑,论文中选用最新的Wikipedia 22-May-2020版本
- Cambridge Dictionary —— 1995年出版,囊括超140k单词、短语及解释。
文本编码
在从多个知识源中检索与问题相关的知识事实后,使用\([SEP]\)来分割证据知识、原始问题和候选答案。
具体做法:
- 将原始答案选择与来自剑桥词典的答案解释连接起来作为\(A= \left\{ a_{1},a_{2},\dots,a_{n} \right\}\)
- 将来自维基百科和概念网的证据连接起来作为上下文\(C=\left\{c_{1}, c_{2}, \ldots, c_{k}\right\}\)
- 将来自剑桥词典的概念解释与问题词干连接起来作为\(Q=\left\{q_{1}, q_{2}, \ldots, q_{m}\right\}\)
从形式上来看,预先训练的语言模型的输入是问题Q、相关证据C和答案选择A的连接:
\]
答案选择感知注意力机制
通常在从RoBERTa模型中获得最后的隐藏状态向量后,对于下游任务中的问题回答,以往的模型方案是通常直接使用线性分类器来预测答案。
然而,在论文的实验过程中,观察到线性分类器在检索到的证据或背景知识上表现不佳。因此,论文引入了一种答案选择感知的注意机制来计算问题\(h_{q}\)和选择之间的注意分数,并且通过标准的注意计算来计算检索到的证据\(h_{c}\)和答案选择\(h_{a}\)之间的注意分数。
\]
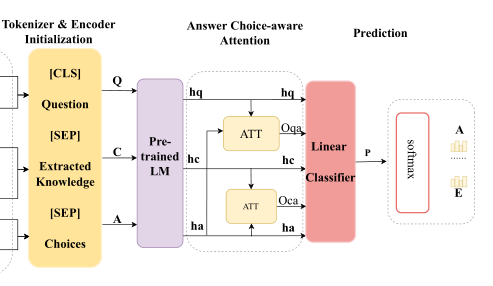
最后,将注意力重新加权的隐藏状态连接起来,通过线性分类器与ReLU进行传递,以计算最终的双向注意力向量进行预测。公式如下:
\]
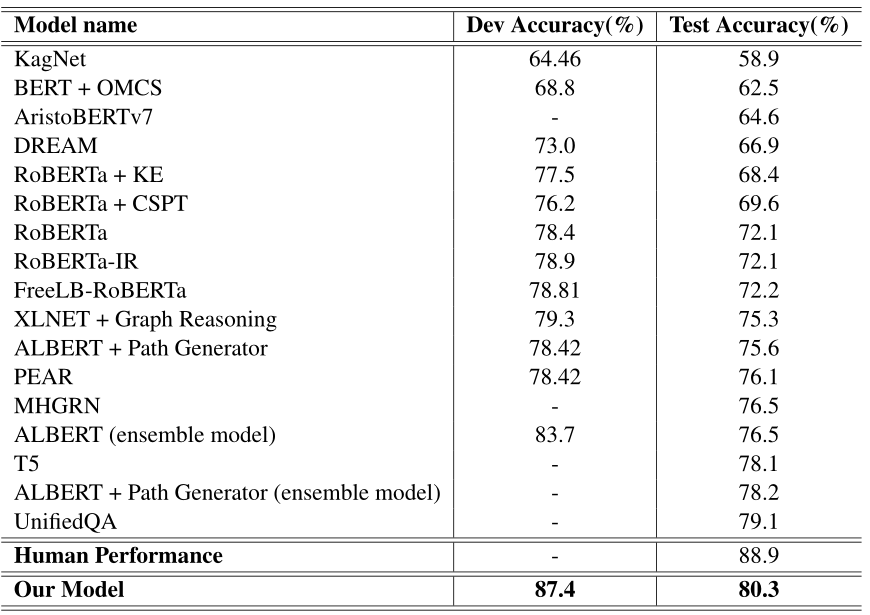
实验结果
- pretrained model —— RoBERTa-large(24-layers)
- max update step —— 6000
- warmup update step —— 150
- max length —— 512
- dropout —— 0.1
- optimizer —— Adam
- loss function —— cross-entropy loss
- batch size —— 4
- learning rate —— 1e-5
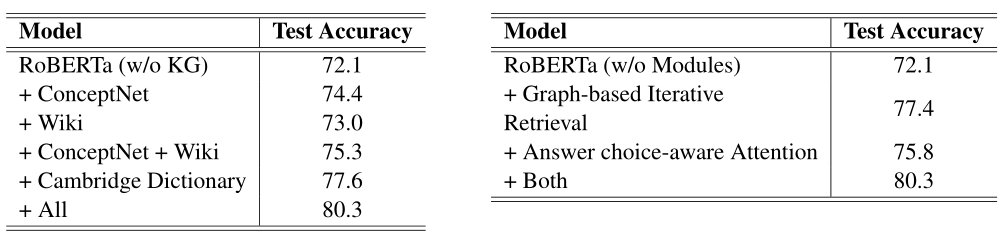
创新有效性研究
左图是对使用多元知识库有效性的研究,可以看到证据来源的知识库越多,模型的表现越好。单知识库来源下,模型表现:剑桥字典 > ConceptNet > Wikipedia。
右图是对图的迭代知识检索以及QA感知注意力机制有效性的研究,实验证明,这两处创新皆能提升模型表现。
结论
处理多项选择题回答任务,需要额外的背景知识或常识。通过有效地整合多种知识资源,提出了一种基于图迭代检索的新的常识问答系统。首先,论文提出一个新的基于图的迭代知识检索模块来迭代检索与给定问题及其选择相关的概念和实体。此外,论文还提出了一种答案选择感知的注意机制,用于融合由预先训练的语言模型编码的所有隐藏层的状态表示。论文作者在CommonsenseQA数据集上进行了实验,实验结果表明,该方法在CommonsenseQA测试集上的准确率上明显优于其他模型。最后,论文进行了对创新的有效性研究,研究结果显示了基于图的迭代知识检索模块和答案选择感知注意模块在从多个知识源检索和合成背景知识方面的有效性。
Improving Commonsense Question Answering by Graph-based Iterative Retrieval over Multiple Knowledge Sources —— 基于多知识库迭代检索的常识问答系统的更多相关文章
- 《Graph-Based Reasoning over Heterogeneous External Knowledge for Commonsense Question Answering》论文整理
融合异构知识进行常识问答 论文标题 -- <Graph-Based Reasoning over Heterogeneous External Knowledge for Commonsense ...
- 《Connecting the Dots: A Knowledgeable Path Generator for Commonsense Question Answering》一文的理解和总结
构建常识问答知识路径生成器 论文贡献 提出学习一个多跳知识路径产生器来根据问题动态产生结构化证据.生成器以预先训练的语言模型为主干,利用语言模型中存储的大量非结构化知识来补充知识库的不完整性.路径 ...
- Learning Conditioned Graph Structures for Interpretable Visual Question Answering
Learning Conditioned Graph Structures for Interpretable Visual Question Answering 2019-05-29 00:29:4 ...
- 论文阅读:Learning Visual Question Answering by Bootstrapping Hard Attention
Learning Visual Question Answering by Bootstrapping Hard Attention Google DeepMind ECCV-2018 2018 ...
- Hierarchical Question-Image Co-Attention for Visual Question Answering
Hierarchical Question-Image Co-Attention for Visual Question Answering NIPS 2016 Paper: https://arxi ...
- Visual Question Answering with Memory-Augmented Networks
Visual Question Answering with Memory-Augmented Networks 2018-05-15 20:15:03 Motivation: 虽然 VQA 已经取得 ...
- CIKM 2013 Paper CQARank: Jointly Model Topics and Expertise in Community Question Answering
中文简单介绍: 本文对怎样在问答社区对用户主题兴趣及专业度建模分析进行了研究,而且提出了针对此问题的统计图模型Topics Expertise Model. 论文出处:CIKM'13. 英文摘要: C ...
- 【自然语言处理】--视觉问答(Visual Question Answering,VQA)从初始到应用
一.前述 视觉问答(Visual Question Answering,VQA),是一种涉及计算机视觉和自然语言处理的学习任务.这一任务的定义如下: A VQA system takes as inp ...
- 论文笔记:Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering
Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering 2019-04-25 21: ...
随机推荐
- mybatis 架构及基础模块
1. mybatis整体架构 基础支撑层详解 1.日志模块 mybatis日志模块没有实现类,需要接入第三方的组件,问题是第三方的组件有各自的log级别,为了能接入第三方组件,mybati日志模块定义 ...
- Java进阶面试
消息中间件: 1.你们公司生产环境用的是什么消息中间件? https://mp.weixin.qq.com/s?__biz=MzU0OTk3ODQ3Ng==&mid=2247484149&am ...
- F. Moving Points 解析(思維、離散化、BIT、前綴和)
Codeforce 1311 F. Moving Points 解析(思維.離散化.BIT.前綴和) 今天我們來看看CF1311F 題目連結 題目 略,請直接看原題. 前言 最近寫1900的題目更容易 ...
- 什么PO模式?
PO模式PO是Page Object的缩写,PO模式是自动化测试项目开发实践的最佳设计模式之一.核心思想是通过对界面元素的封装减少冗余代码,同时在后期维护中,若元素定位发生变化, 只需要调整页面元素封 ...
- CSS动画之过渡模块
:hover伪类选择器可以用于所有的选择器(只有在悬停时,执行选择器的属性)CSS3中新增过渡模块:transition property(属性)duration(过渡效果花费的时间)timing-f ...
- 快来,我悄悄的给你说几个HashCode的破事。
这是why技术的第 72 篇原创文章 Hash冲突是怎么回事 在这个文章正式开始之前,先几句话把这个问题说清楚了:我们常说的 Hash 冲突到底是怎么回事? 直接上个图片: 你说你看到这个图片的时候想 ...
- CopyOnWriteArrayList线程安全分析
CopyOnWriteArrayList是开发过程中常用的一种并发容器,多用于读多写少的并发场景.但是CopyOnWriteArrayList真的能做到完全的线程安全吗? 答案是并不能. 一.Copy ...
- Linux开机启动顺序启动顺序及配置开机启动
Linux:开机启动顺序启动顺序及配置开机启动 开机启动顺序 1.加载内核 2.启动 init(/etc/inittab) pid=1 3.系统初始化 /etc/rc.d/rc.sysinit 4.运 ...
- NS-3环境布置及安装
MMP的,入坑NS3了,LTE是什么鬼!!! ubantu安装NS3解决依赖环境 一堆安装包需要安装,试了N多次(CentOS没安装明白,转而ubantu).利用脚本进行按装. 貌似得先对本机软件进行 ...
- 【Kata Daily 190918】Spacify(插空)
题目: Modify the spacify function so that it returns the given string with spaces insertedbetween each ...