Visual Question Answering with Memory-Augmented Networks
Visual Question Answering with Memory-Augmented Networks
2018-05-15 20:15:03
Motivation:
虽然 VQA 已经取得了很大的进步,但是这种方法依然对完全 general,freeform VQA 表现很差,作者认为是因为如下两点:
1. deep models trained with gradient based methods learn to respond to the majority of training data rather than specific scarce exemplars ;
用梯度下降的方法训练得到的深度模型,对主要的训练数据有较好的相应,但是对特定的稀疏样本却不是;
2. existing VQA systems learn about the properties of objects from question-answer pairs, sometimes indepently of the image.
选择性的关注图像中的某些区域是很重要的策略。
我们从最近的 memory-augmented neural networks 以及 co-attention mechanism 得到启发,本文中,我们利用 memory-networks 来记忆 rare events,然后用 memory-augmented networks with attention to rare answers for VQA.

The Proposed Algorithm :
本文的算法流程如上图所示,首先利用 embedding 的方法,提取问题和图像的 feature,然后进行 co-attention 的学习,然后将两个加权后的feature进行组合,然后输入到 memory network 中,最终进行答案的选择。
Image Embedding:用 pre-trained model 进行特征的提取;
Question Embedding:用双向 LSTM 网络进行语言特征的学习;
Sequential Co-attention:
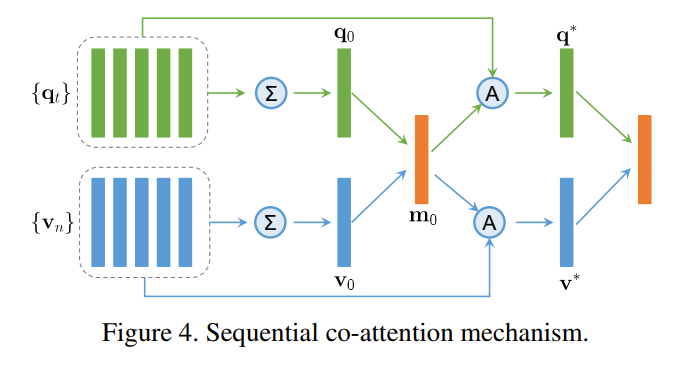
这里的协同 attention 机制,考虑到图像和文本共同的特征,相互影响,得到共同的注意力机制。我们根据 视觉特征和语言特征的平均值,进行点乘,得到一个 base vector m0 :
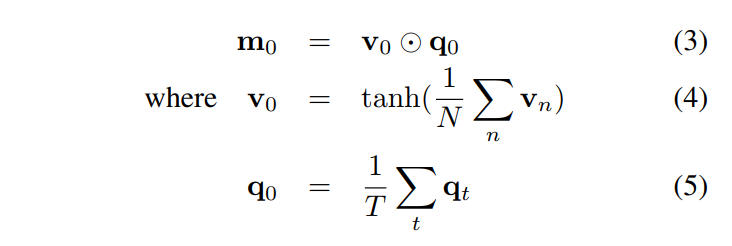
我们用一个两层的神经网络进行 soft attention 的计算。对于 visual attention,the soft attention 以及 加权后的视觉特征向量分别为:
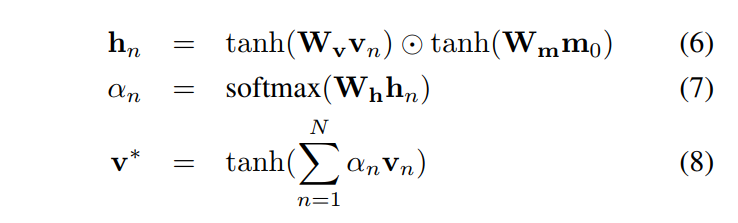
其中 Wv, Wm,Wh 都表示 hidden states。类似的,我们计算加权后的问题特征向量,如下:
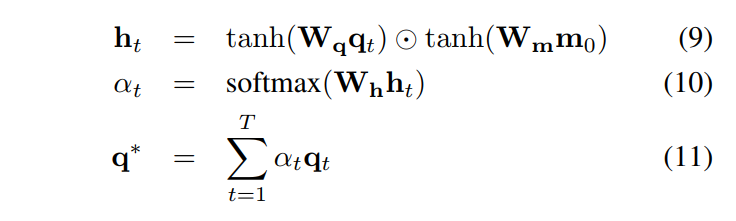
我们将加权后的 v 和 q 组合,用来表示输入图像和问题对,图4,展示了 co-attention 机制的整个过程。
Memory Augmented Network:
The RNNs lack external memory to maintain a long-term memory for scarce training data. This paper use a memory-augmented NN for VQA.
特别的,我们采用了标准的 LSTM 模型作为 controller,起作用是 receives input data,然后跟外部记忆模块进行交互。外部记忆,Mt,是有一系列的 row vectors 作为 memory slots。
xt 代表的是视觉特征和文本特征的组合;yt 是对应的编码的问题答案(one-hot encoded answer vector)。然后将该 xt 输入到 LSTM controller,如:
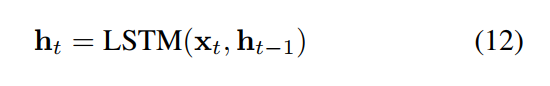
对于从外部记忆单元中读取,我们将 the hidden state ht 作为 Mt 的 query。首先,我们计算 搜索向量 ht 和 记忆中每一行的余弦距离:
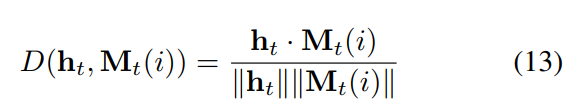
然后,我们通过 the cosine distance 用 softmax 计算一个 read weight vector wr:
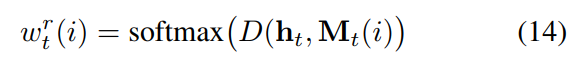
有这些 read-weights, 一个新的检索的记忆 rt 可以通过下面的式子得到:
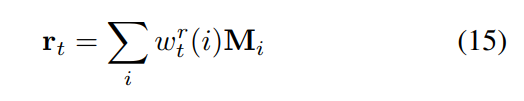
最后,我们将 the new memory vector rt 和 controller hidden state ht 组合,然后产生 the output vector ot for learning classifier.
我们采用 the usage weights wu 来控制写入到 memory。我们通过衰减之前的 state 来更新 the usage weights :
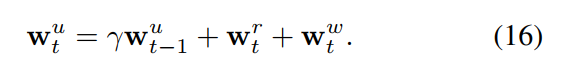
为了计算 the write weights,我们引入一个截断机制 来更新 the least-used positions。此处,我们采用 m(v, n) 来表示 the n-th smallest element of a vector v. 我们采用 a learnable sigmoid gate parameter 来计算之前的 read weights 和 usage weights 的 convex combination:
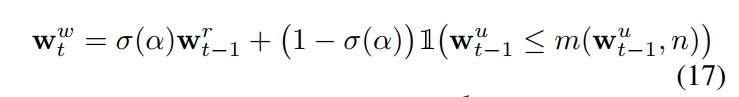
A larger n results in maintaining a longer term of memory of scarce training data. 跟 LSTM 内部的记忆单元相比,这里的两个参数都可以用来调整 the rate of writing to exernal memory. 这给我们更多的自由来调整模型的更新。公式(12)中输出的隐层状态 ht 可以根据 the write weights 写入到 memory 中:
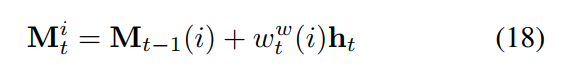
Answer Reasoning:
有了 the hidden state ht 以及 那个外部记忆单元中得到的 the reading memory rt,我们将这两个组合起来,作为当前问题和图片的表达,输入到分类网络中,然后得到答案的分布。
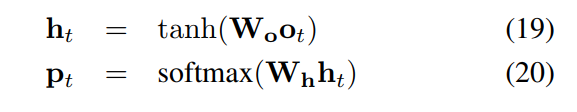
--- Done !
Visual Question Answering with Memory-Augmented Networks的更多相关文章
- 论文笔记:Visual Question Answering as a Meta Learning Task
Visual Question Answering as a Meta Learning Task ECCV 2018 2018-09-13 19:58:08 Paper: http://openac ...
- Hierarchical Question-Image Co-Attention for Visual Question Answering
Hierarchical Question-Image Co-Attention for Visual Question Answering NIPS 2016 Paper: https://arxi ...
- 【自然语言处理】--视觉问答(Visual Question Answering,VQA)从初始到应用
一.前述 视觉问答(Visual Question Answering,VQA),是一种涉及计算机视觉和自然语言处理的学习任务.这一任务的定义如下: A VQA system takes as inp ...
- 论文阅读:Learning Visual Question Answering by Bootstrapping Hard Attention
Learning Visual Question Answering by Bootstrapping Hard Attention Google DeepMind ECCV-2018 2018 ...
- Learning Conditioned Graph Structures for Interpretable Visual Question Answering
Learning Conditioned Graph Structures for Interpretable Visual Question Answering 2019-05-29 00:29:4 ...
- 第八讲_图像问答Image Question Answering
第八讲_图像问答Image Question Answering 课程结构 图像问答的描述 具备一系列AI能力:细分识别,物体检测,动作识别,常识推理,知识库推理..... 先要根据问题,判断什么任务 ...
- 论文:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering-阅读总结
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering-阅读总结 笔记不能简单的抄写文中 ...
- 论文笔记:Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering
Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering 2019-04-25 21: ...
- SalGAN: Visual saliency prediction with generative adversarial networks
SalGAN: Visual saliency prediction with generative adversarial networks 2017-03-17 摘要:本文引入了对抗网络的对抗训练 ...
随机推荐
- Yii Restful api认证
- datetime处理日期和时间
datetime.now() # 获取当前datetimedatetime.utcnow() datetime(2017, 5, 23, 12, 20) # 用指定日期时间创建datetime 一.将 ...
- 检测FTP服务并开启FTP服务
1. 检测FTP服务是否开启 1.1. 通过查询提供FTP服务的进程是否存在,并未找到任何包含ftp关键字的进程信息,可判断服务未开启. root@lb- ~ # ps -ef | grep ftp ...
- Java技术整理1---反射机制及动态代理详解
1.反射是指在程序运行过程中动态获取类的相关信息,包括类是通过哪个加载器进行加载,类的方法和成员变量.构造方法等. 如下示例可以通过三种方法根据类的实例来获取该类的相关信息 public static ...
- LoadRunner录制登录机票网址,并回放,加断言
回放录制登录过程脚本,加断言 在页面登录的过程如下: 1先进入http://127.0.0.1:1080/WebTours/index.htm 2之后获取userSession信息 3在输入信息后点击 ...
- C# 调整控件的Z顺序
当窗口或者容器控件中的控件在布局过程中发生重叠的时候,会出现层次性.Z顺序较大的控件会遮挡Z顺序较小的控件,放在顶层的控件会挡住放在底层的控件. 1.编辑一个这样的窗口(使用Label控件) 2.添加 ...
- Building Tool(Maven/Gradle)
构建工具的简单介绍 在代码世界中有三大构建工具,ant.Maven和Gradle.现在的状况是maven和gradle并存,gradle使用的越来越广泛.Maven使用基于XML的配置,Gradle采 ...
- JustOj 1994: P1001
题目描述 给定一个长度为N(0< n< =10000)的序列,保证每一个序列中的数字a[i]是小于maxlongint的非负整数 ,编程要求求出整个序列中第k大的数字减去 ...
- python--表达式(运算表达式)
运算表达式 python 的表达式包括:算术运算符,赋值运算符,比较运算符,成员运算符 算术运算符 运算符 描述 + 加 - 两个对象相加 - 减 - 得到负数或是一个数减去另一个数 * 乘 - 两个 ...
- 了解一下 Linux 上用于的 SSH 图形界面工具
如果你碰巧喜欢好的图形界面工具,你肯定很乐于了解一些 Linux 上优秀的 SSH 图形界面工具.让我们来看看这三个工具,看看它们中的一个(或多个)是否完全符合你的需求. 在你担任 Linux 管理员 ...