Scrapy 项目:腾讯招聘
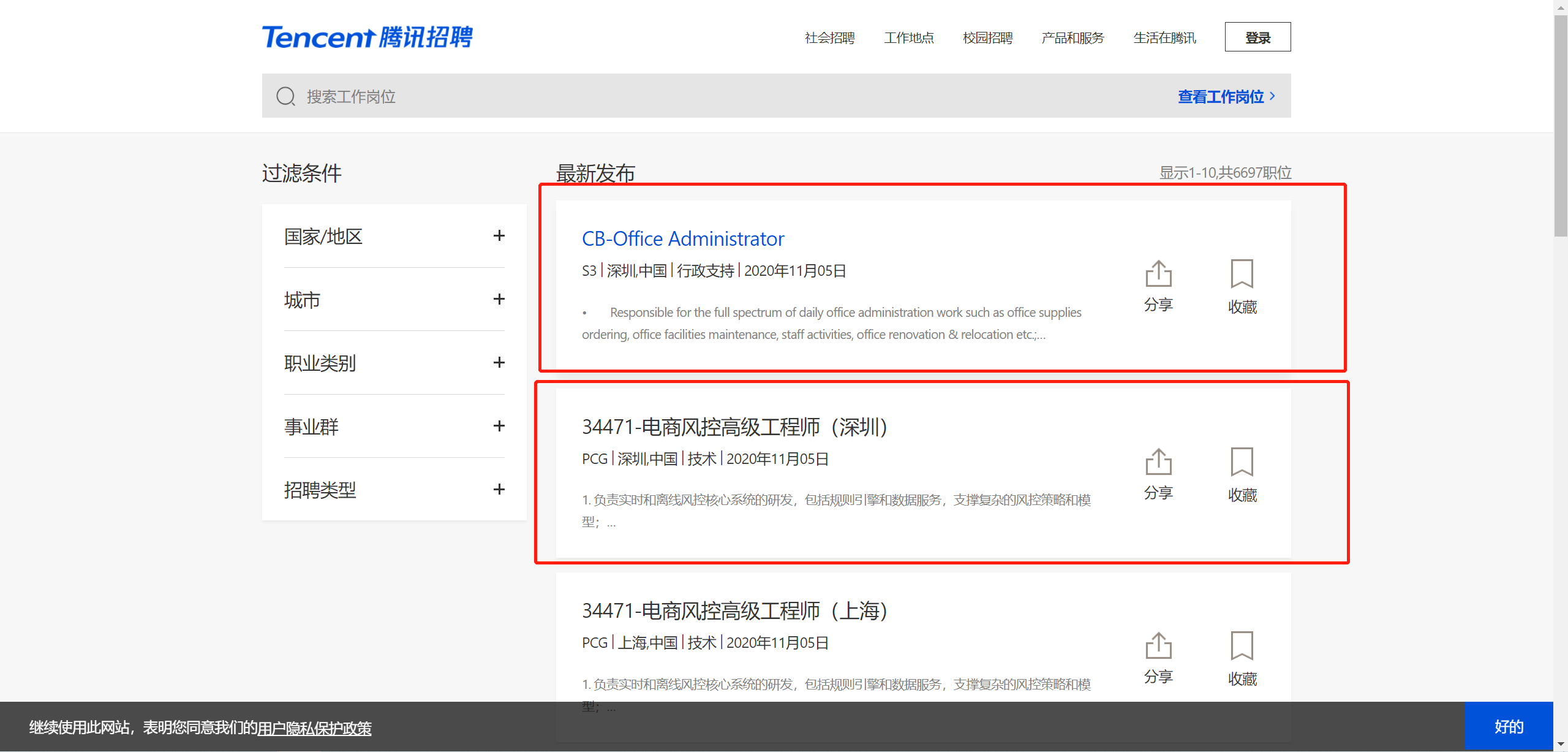
目的:
通过爬取腾讯招聘网站(https://careers.tencent.com/search.html)练习Scrapy框架的使用
步骤:
1、通过抓包确认要抓取的内容是否在当前url地址中,测试发现内容不在当前url中并且数据格式为json字符串
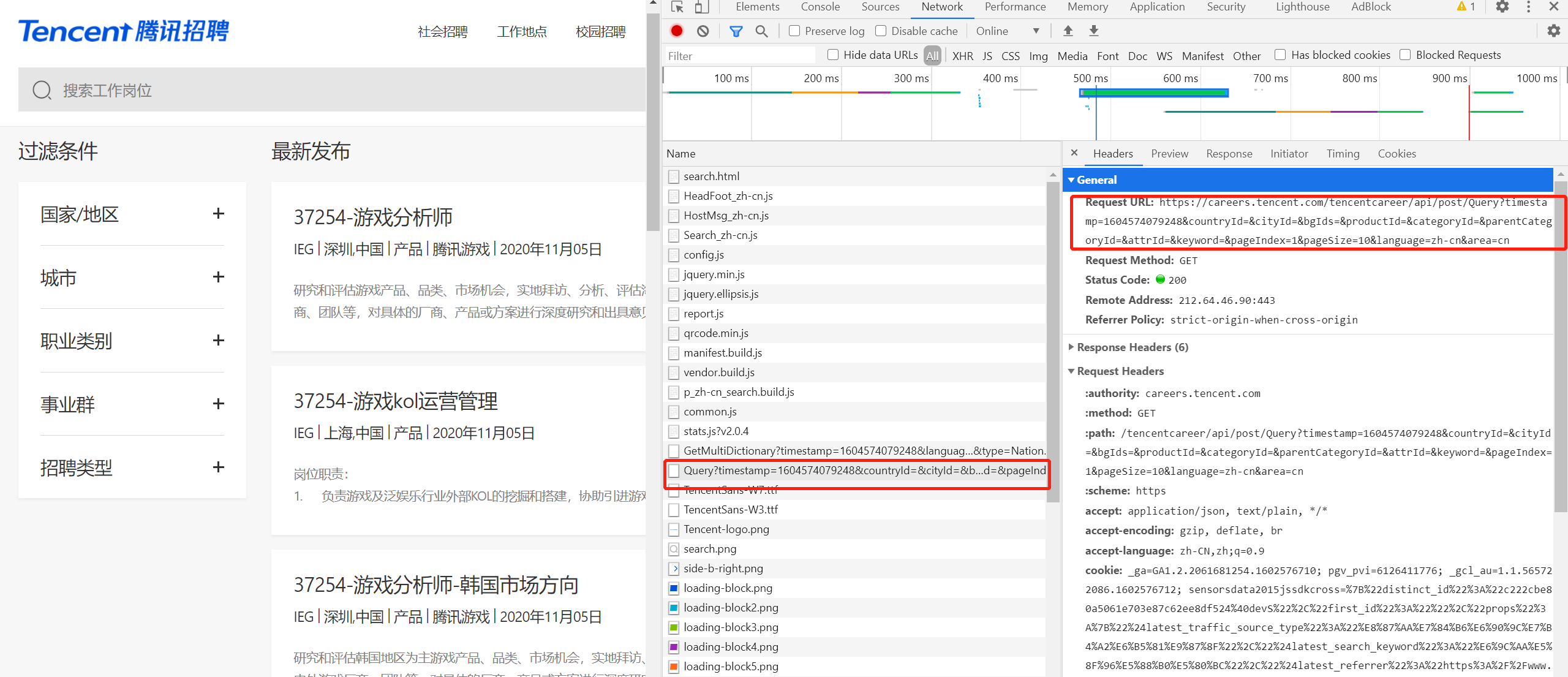
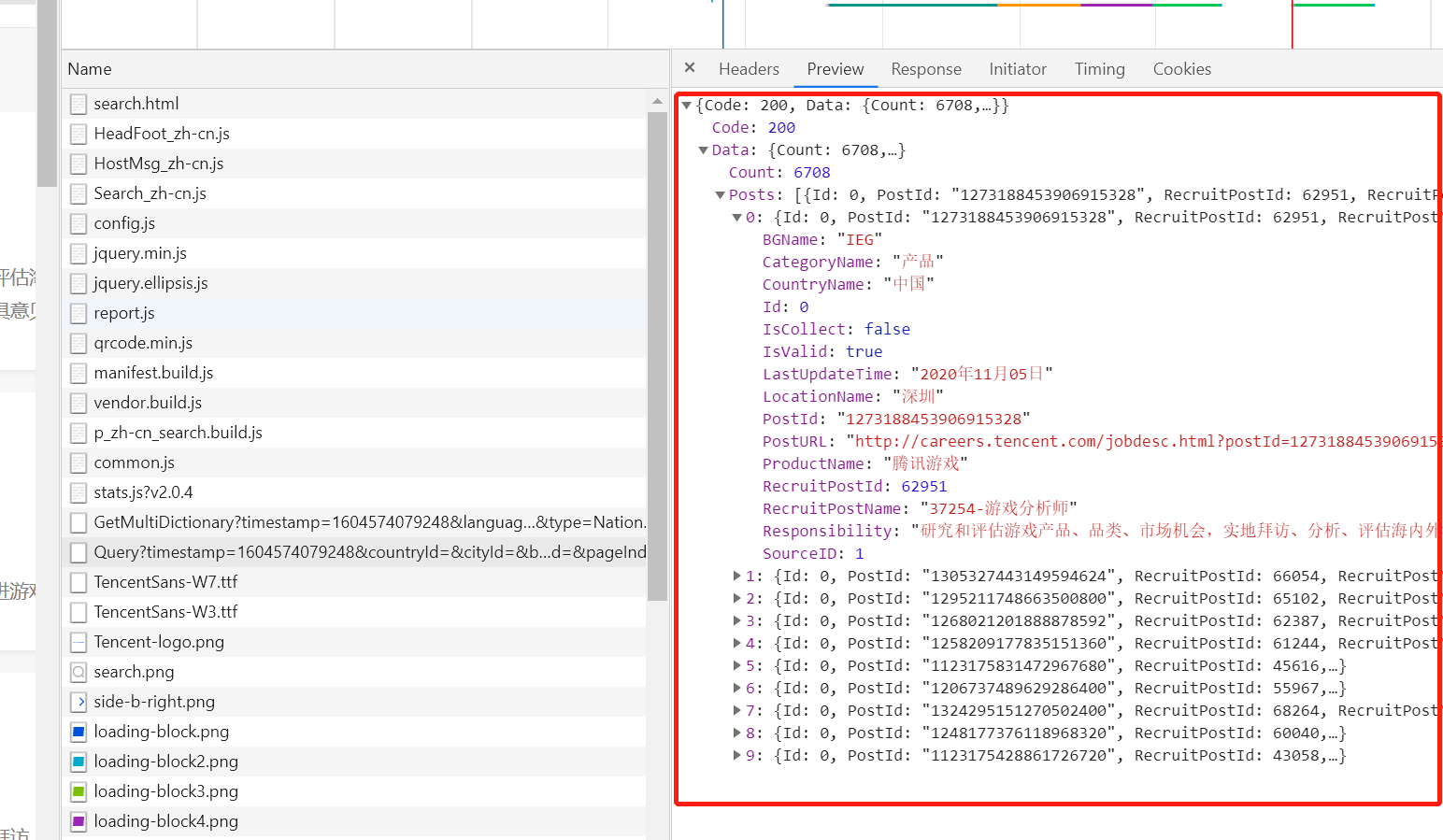
2、请求url地址过长,考虑去除某些部分,经测试得到
'https://careers.tencent.com/tencentcareer/api/post/Query?keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn'
3、寻找url地址,pageIndex=页码,可构造爬虫循环的URL列表
4、书写爬虫代码
- scrapy startproject tencent tencent.com
- cd tencent.com
- scrapy genspider hr tencent.com
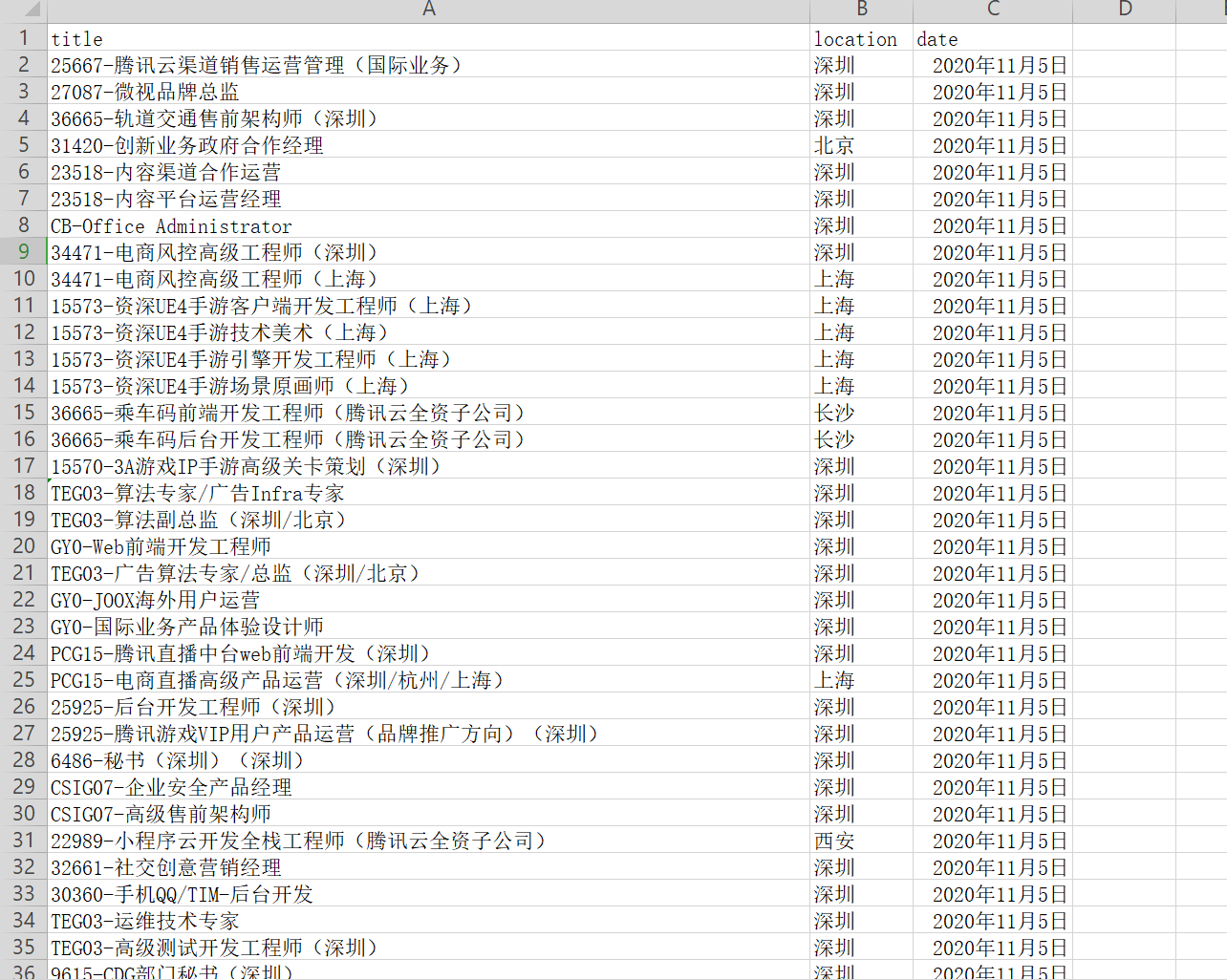
5、保存为CSV文件
1 import scrapy
2 import json
3
4
5 class HrSpider(scrapy.Spider):
6 name = 'hr'
7 allowed_domains = ['tencent.com']
8 start_urls = ['https://careers.tencent.com/tencentcareer/api/post/Query?keyword=&pageIndex=1&pageSize=10&language'
9 '=zh-cn&area=cn']
10 url = 'https://careers.tencent.com/tencentcareer/api/post/Query?keyword=&pageIndex={' \
11 '}&pageSize=10&language=zh-cn&area=cn '
12 pageIndex = 1
13
14 def parse(self, response):
15 json_str = json.loads(response.body)
16 for content in json_str["Data"]["Posts"]:
17 content_dic = {"title": content["RecruitPostName"], "location": content["LocationName"],
18 "date": content["LastUpdateTime"]}
19 print(content_dict)20
yield content_dic
21
23 if self.pageIndex < 10:
24 self.pageIndex += 1
25 next_url = self.url.format(self.pageIndex)
26 yield scrapy.Request(url=next_url, callback=self.parse)
运行爬虫
- scrapy crawl hr
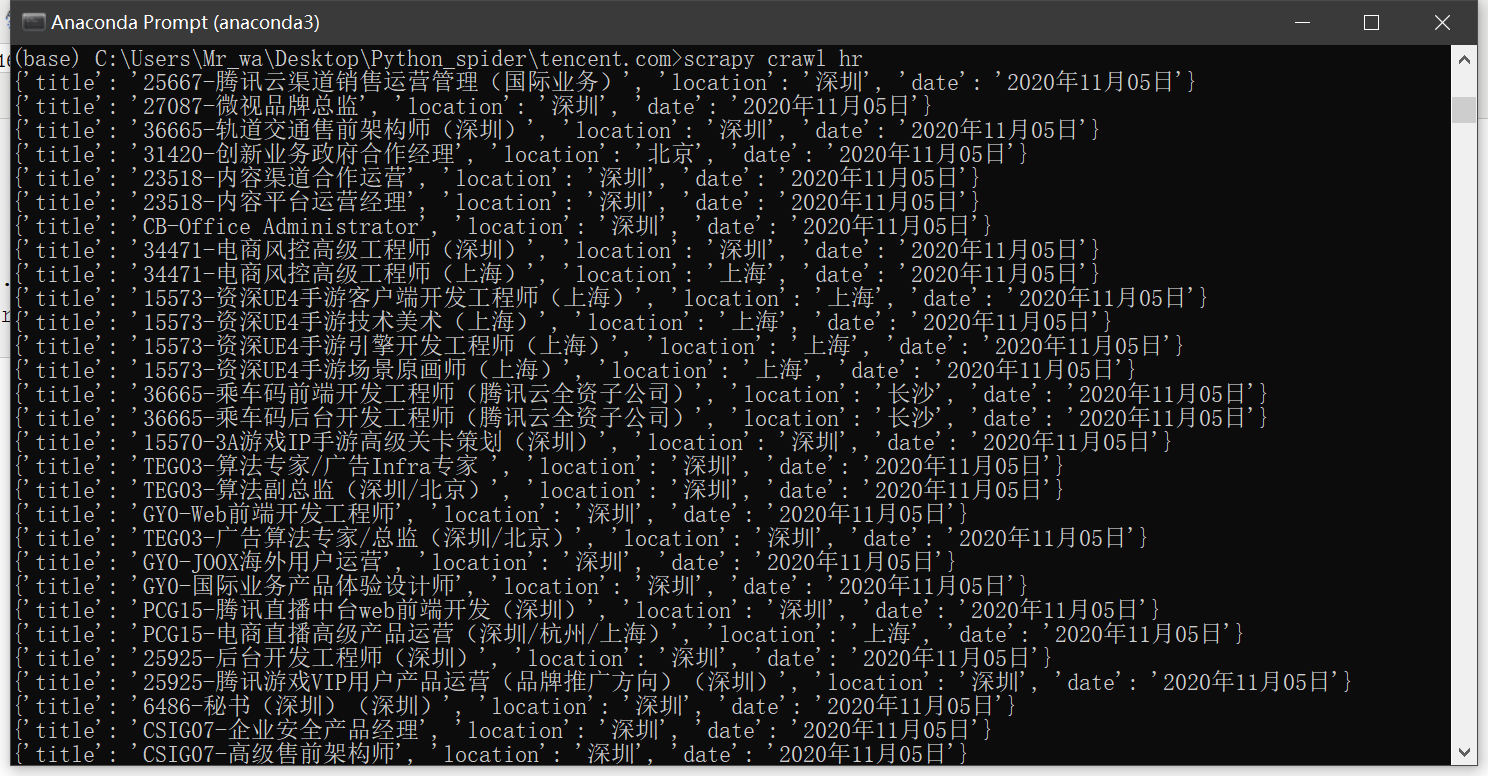
保存命令
- scrapy crawl hr -o tencent.csv
Scrapy 项目:腾讯招聘的更多相关文章
- Scrapy实现腾讯招聘网信息爬取【Python】
一.腾讯招聘网 二.代码实现 1.spider爬虫 # -*- coding: utf-8 -*- import scrapy from Tencent.items import TencentIte ...
- Scrapy:腾讯招聘整站数据爬取
项目地址:https://hr.tencent.com/ 步骤一.分析网站结构和待爬取内容 以下省略一万字 步骤二.上代码(不能略了) 1.配置items.py import scrapy class ...
- Scrapy案例02-腾讯招聘信息爬取
目录 1. 目标 2. 网站结构分析 3. 编写爬虫程序 3.1. 配置需要爬取的目标变量 3.2. 写爬虫文件scrapy 3.3. 编写yield需要的管道文件 3.4. setting中配置请求 ...
- Scrapy项目 - 实现腾讯网站社会招聘信息爬取的爬虫设计
通过使Scrapy框架,进行数据挖掘和对web站点页面提取结构化数据,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- Scrapy项目 - 数据简析 - 实现腾讯网站社会招聘信息爬取的爬虫设计
一.数据分析截图 本例实验,使用Weka 3.7对腾讯招聘官网中网页上所罗列的招聘信息,如:其中的职位名称.链接.职位类别.人数.地点和发布时间等信息进行数据分析,详见如下图: 图1-1 Weka ...
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- python爬虫scrapy项目详解(关注、持续更新)
python爬虫scrapy项目(一) 爬取目标:腾讯招聘网站(起始url:https://hr.tencent.com/position.php?keywords=&tid=0&st ...
- pymongodb的使用和一个腾讯招聘爬取的案例
一.在python3中操作mongodb 1.连接条件 安装好pymongo库 启动mongodb的服务端(如果是前台启动后就不关闭窗口,窗口关闭后服务端也会跟着关闭) 3.使用 import pym ...
- 亲测——pycharm下运行第一个scrapy项目 ©seven_clear
最近在学习scrapy,就想着用pycharm调试,但不知道怎么弄,从网上搜了很多方法,这里总结一个我试成功了的. 首先当然是安装scrapy,安装教程什么的网上一大堆,这里推荐一个详细的:http: ...
随机推荐
- Linux环境mysql快速备份及迁移
在项目实施的过程中,经常会面临数据库迁移,导出和导出数据,如果用普通的mysql客户端备份,时间较长且容易出错.那么mysql快速备份及迁移,就成为数据库迁移的重中之重. 下面介绍我在项目实现过程中用 ...
- 配合 jekins—springboot脚本
#!/usr/bin/bash # author : renguangyin@yingu.com current=$(cd `dirname $0`; pwd) cd ${current} ext_n ...
- WPS Excel启用正则表达式
WPS Excel启用正则表达式 新建一个空白表格文件 进入VB编辑器 插入模块 工具-引用-勾选正则表达式 (Microsoft VBScript Regular Express 5.5) 复制代码 ...
- OsgEarth开发笔记(一):Osg3.6.3+OsgEarth3.1+vs2019x64开发环境搭建(上)
前言 OSG研究之后,做地理GIS显示了地球:<项目实战:Qt+OSG教育学科工具之地理三维星球>,这一文章是基于OSG做的,而基于OsgEarth是可以进一步对地球进行深度操作,所以 ...
- 秒啊,速来get这9个jupyter实用技巧
1 简介 jupyter notebook与jupyter lab作为广受欢迎的ide,尤其适合开展数据分析相关工作,而掌握它们相关的一些实用技巧,势必会大大提升日常工作效率.而今天我就来给大家介绍9 ...
- 深度学习论文翻译解析(十九):Searching for MobileNetV3
论文标题:Searching for MobileNetV3 论文作者:Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Che ...
- vs中python包安装教程
vs安装python很简单,只需要在vs安装包中选择python就可以了,这里使用的python3.7: 如果有了解,都知道安装python包的指令:"pip install xxx&quo ...
- 分层图最短路( LYOi Online Judge 初中的最后一天)
代码参照: LYOI Online Judge #374. 初中的最后一天 分层图最短路模板题 1 #include<iostream> 2 #include<cstdi ...
- Discrete Centrifugal Jumps CodeForces - 1407D 单调栈+dp
题意: 给你n个数hi,你刚开始在第1个数的位置,你需要跳到第n个数的位置. 1.对于i.j(i<j) 如果满足 max(hi+1,-,hj−1)<min(hi,hj) max(hi,hj ...
- Kuroni and the Punishment CodeForces - 1305F 随机函数mt19937 + 质因子分解
题意: 给你n个数,你每次操作可以对一个数加1或者减1,让你求你最少需要操作多少次可以使这n个数的公因子大于1 题解: 正常方法就是枚举质因子(假设质因子为x),然后对于这个数组中的数a[i],让a[ ...