Python 爬取大众点评 50 页数据,最好吃的成都火锅竟是它!
前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 胡萝卜酱
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
爬虫
首先笔者定位为成都,美食类型选的“火锅”,火锅具体类型选的不限,区域选的不限,排序选的智能,如图: 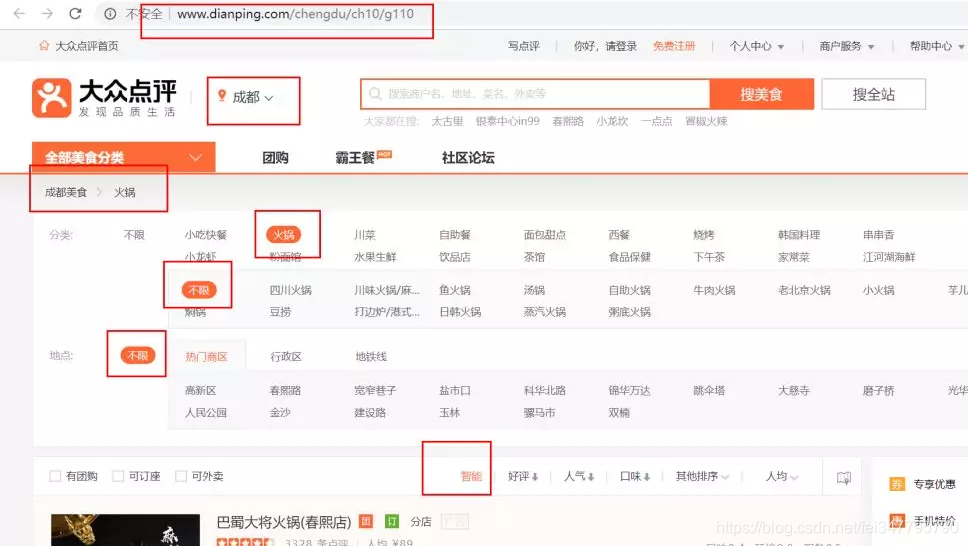
你也可以选择别的选项,只是注意URL的变化。本文都是按照上述选项爬取的数据。接下来翻页观察一下URL的变化:
第二页:

第三页:

很容易观察出翻页变化的知识p后面的数字,倒推回第一页,发现一样的显示内容,因此,写一个循环,便可以爬取全部页面。
但是大众点评只提供了前50页的数据,所以,我们也只能爬取前50页。
这一次,笔者用的pyquery来分析网页的,所以我们需要定位到我们所爬取的数据的位置,如图: 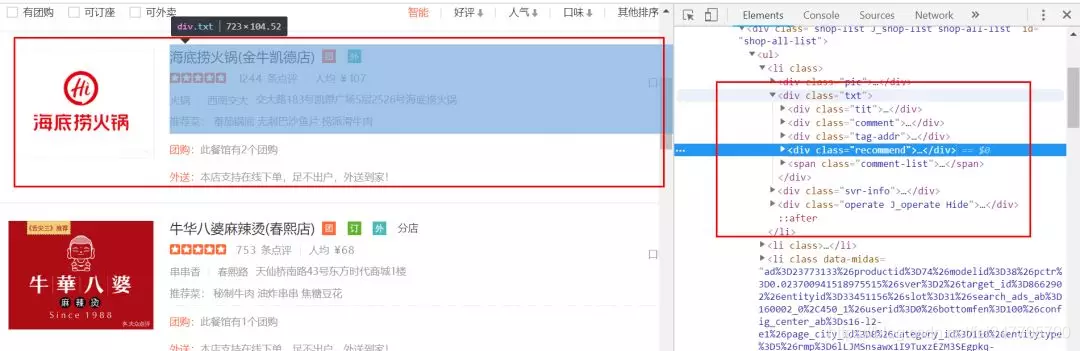
在具体分析的网页的时候,我震惊了,大众点评的反爬做的太过分了,它的数字,一些文字居然都不是明文显示,而是代码,你还不知道怎么分析它。如图:
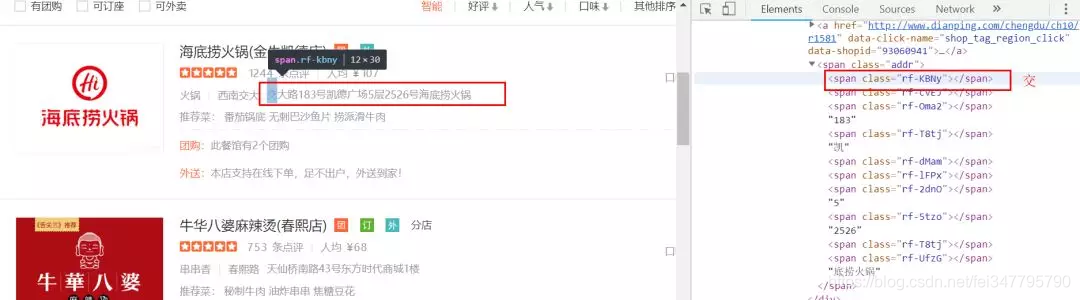
很烦的,一些文字又可以显示,一些又用代码表示。一些数字也是,不过好一点的是数字只有9个,只要稍微观察一下,就能发现数字的代码是什么了。这里笔者列出来了。 {'hs-OEEp': 0, 'hs-4Enz': 2, 'hs-GOYR': 3, 'hs-61V1': 4, 'hs-SzzZ': 5, 'hs-VYVW': 6, 'hs-tQlR': 7, 'hs-LNui': 8, 'hs-42CK': 9}。值得注意的是,数字1,是用明文表示的。
那么,如何用pyquery来定位呢,很简单,你找到你要获取的数据,然后右键→copy→cut selector,你复制到代码里面就OK了。pyquery的具体用法百度既有。
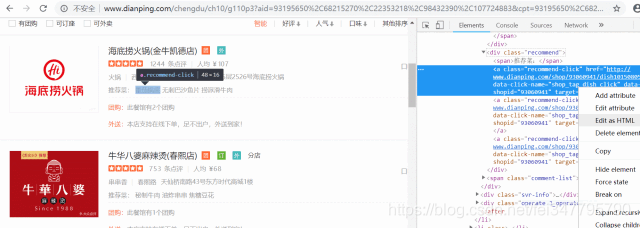
最后,我们获取了火锅50个页面的数据,每页15个数据,一共750家餐厅的数据。
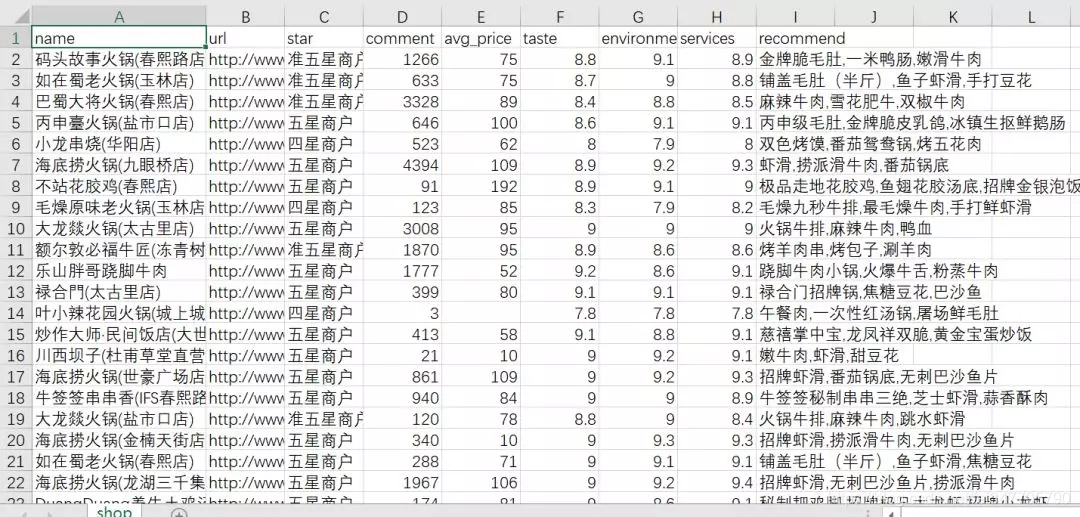
分析
大众点评已经给出了星级评价,可以看看大致趋势。
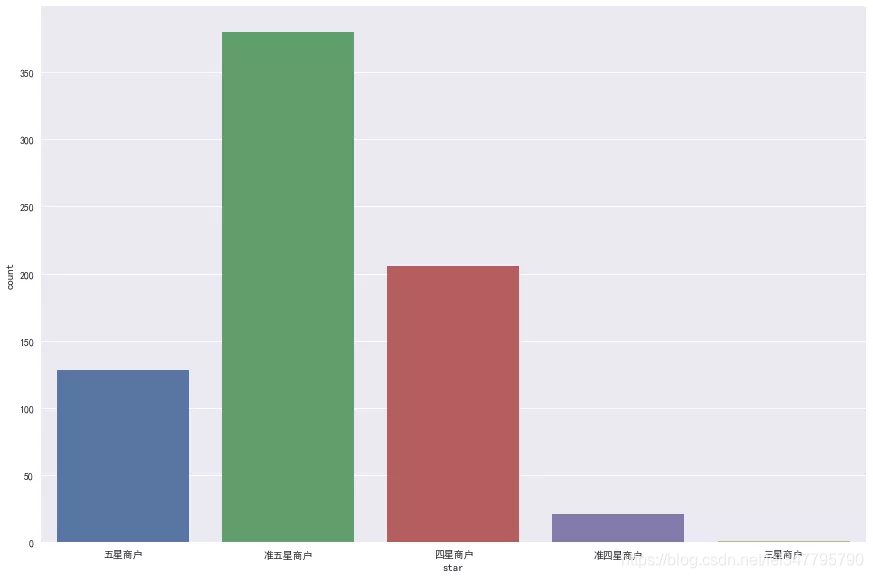
准五星商户最多,可能因为大部分食客都习惯给好评,只有实在不满时才会打出低评有关,造成了评级一般不低,但近满分还是蛮少的。
在本文,我们假设评论数目为饭店的热度,也就是它越火,评论数目越多。
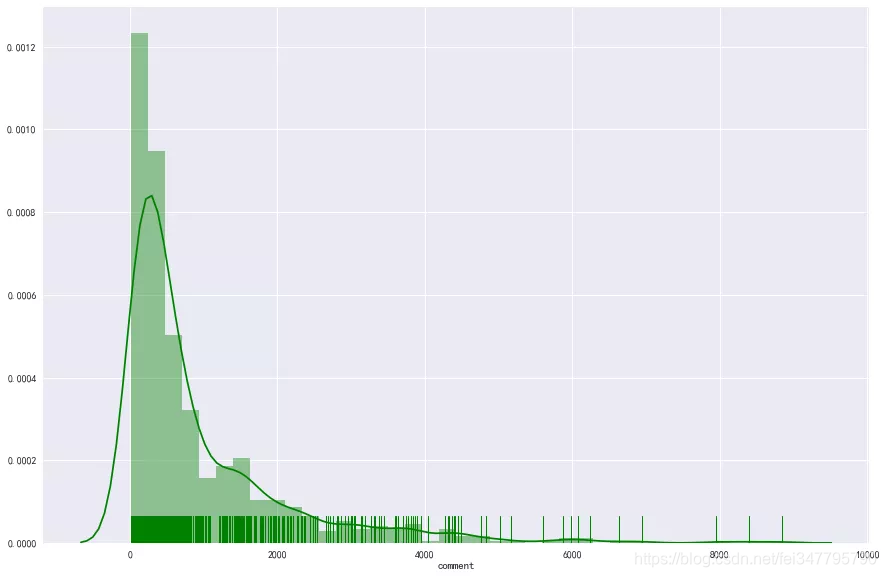
评论数目大多在1000以内,但是高于2000,甚至高于4000也还存在一些,这些饭店应该是一些网红店。以5000为约束,筛选出饭店均为小龙坎、蜀大侠都非常知名的火锅店。那么评论数量和星级有关系吗?看下图: 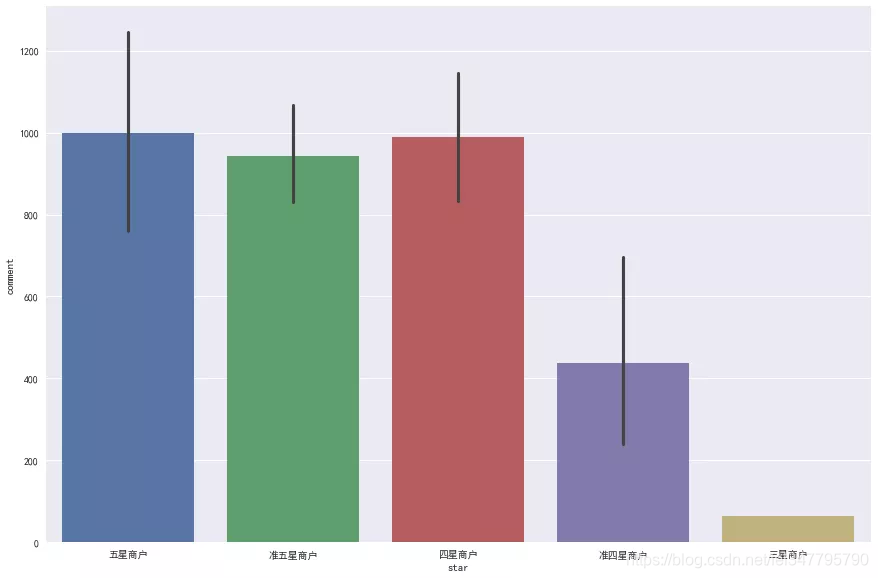
这里取其评论数平均值,发现对于四星以上商户来说,评论数和星级并不关系,但均比低于四星的饭店销量更好。这说明在四星以上之后,人们选择差别不大,但一般不愿意接受评论太差的饭店。
对于笔者这样的学生党来说,影响较大还有人均消费情况。
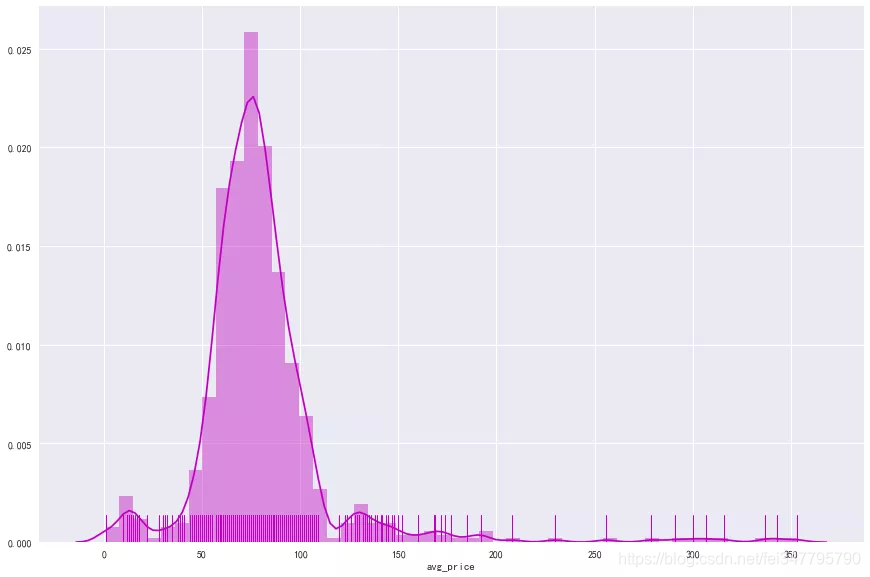
成都的火锅店人均消费大部分都在50-100的区间内,高于150的也有一些。对于笔者来讲,吃一顿火锅,人均在50-100是可以接受的,高于100,就要低头看看钱包了()。那扩展看,人均消费和星级、评论数量有关系吗? 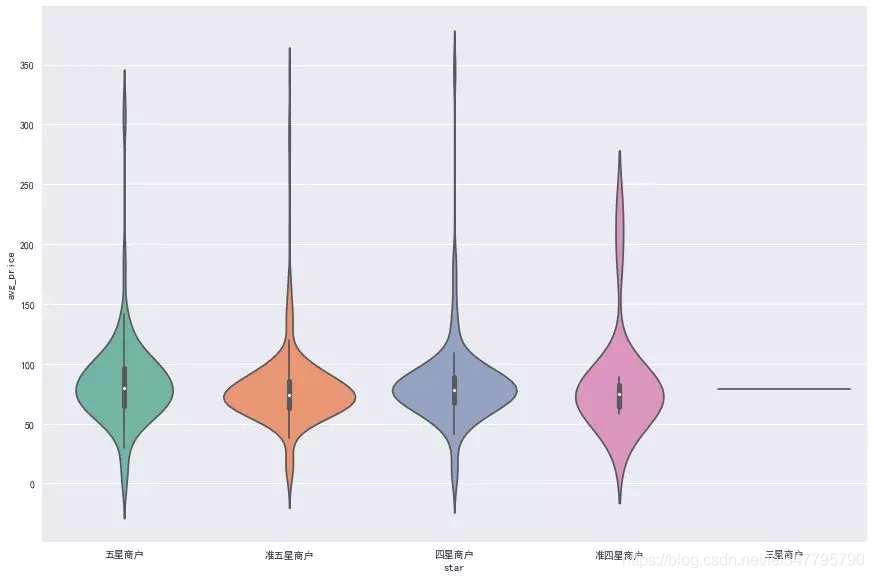
上图是人均消费和星级的关系,看起来并无任何关系,那说明一些口碑好的火锅店,其实人均也不贵。下面看看人均和评论数目的关系吧。

通过比较,发现评论数目低于500,人均在50-100区间是最多的。当然这肯定和评论数量、人均消费本身集中于这一阶段有关。
吃火锅,一家店的生意好坏,肯定还和它的特色菜有关,笔者通过jieba分词,将爬取到的推荐菜做了一个词云图,如下。 
笔者最爱的牛肉是特色菜之最啊,尤其是麻辣牛肉,只要去吃火锅,都要来上一份,其次是毛肚、虾滑、鹅肠等等。
接下来是大家都关心的,口味、环境和服务的情况。
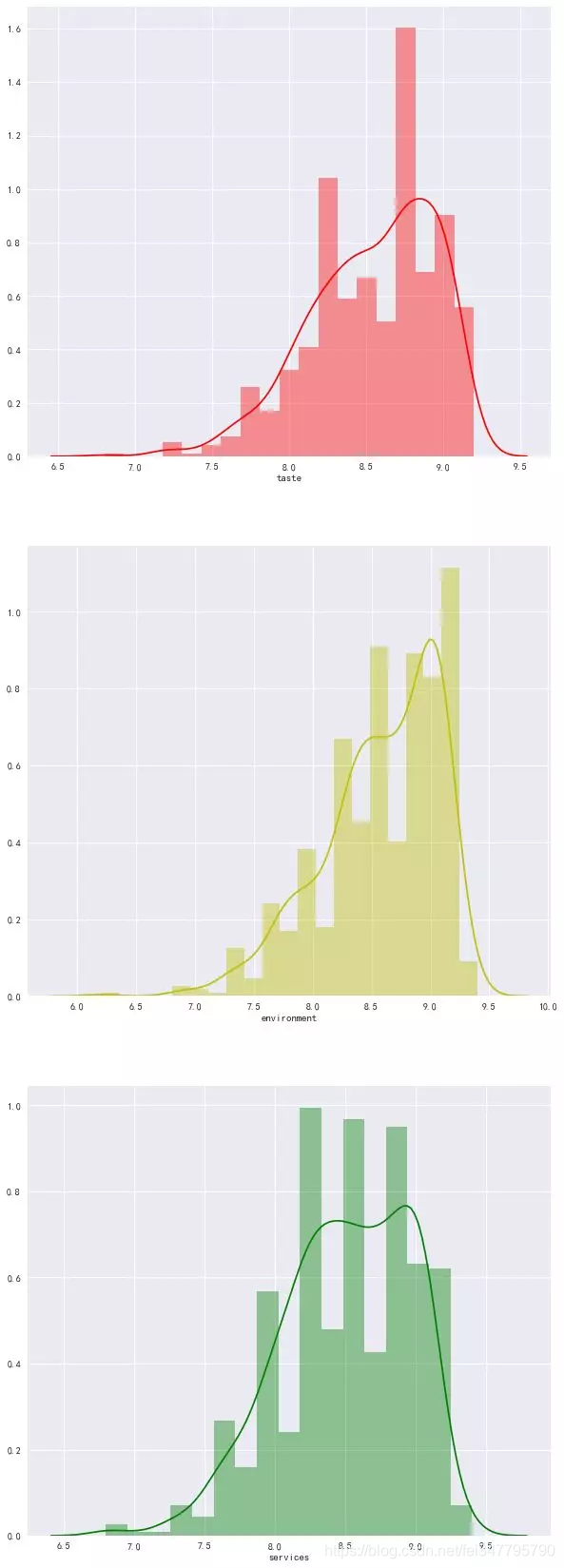
三者得分大多都是集中在8.0-9.2这一阶段,笔者认为,低于7.5分的饭店还是不要去尝试了。同时,星级评价应该也是由这三者得分产生的。
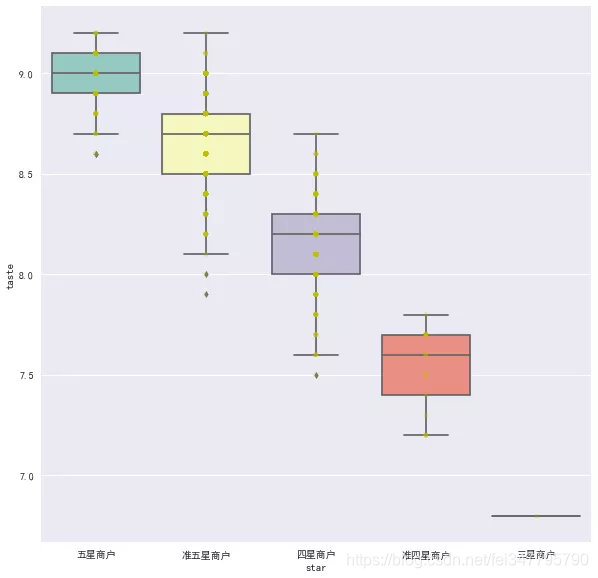
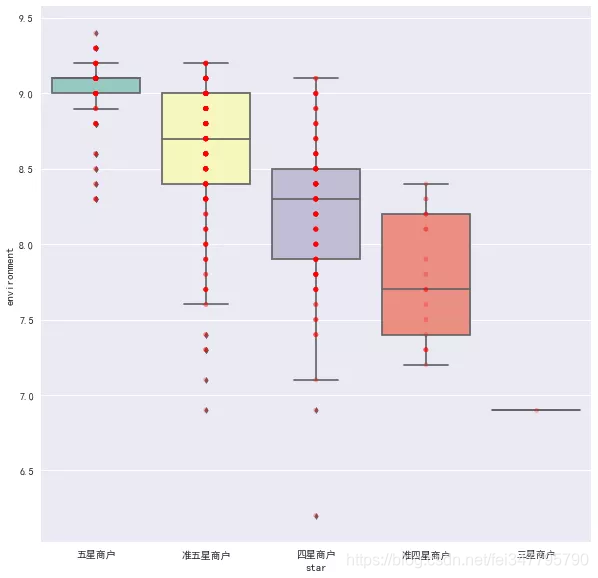
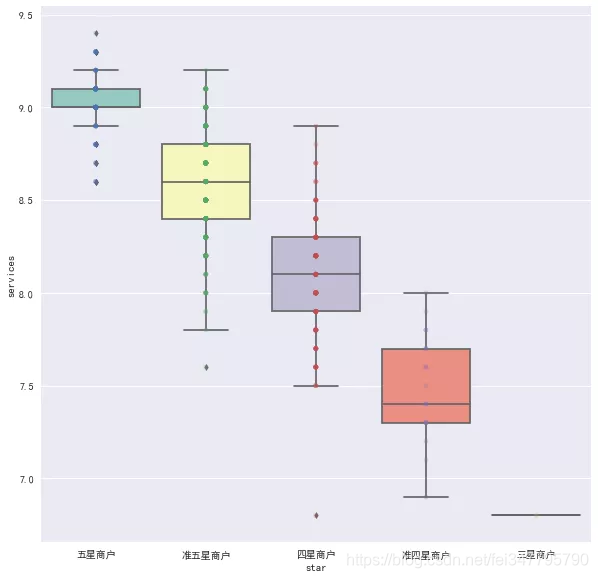
果然如预想的一向,星级评价越好,它在口味、环境和服务的得分越高。那么口味,环境,服务得分与评论数量,平均价格有关系吗?
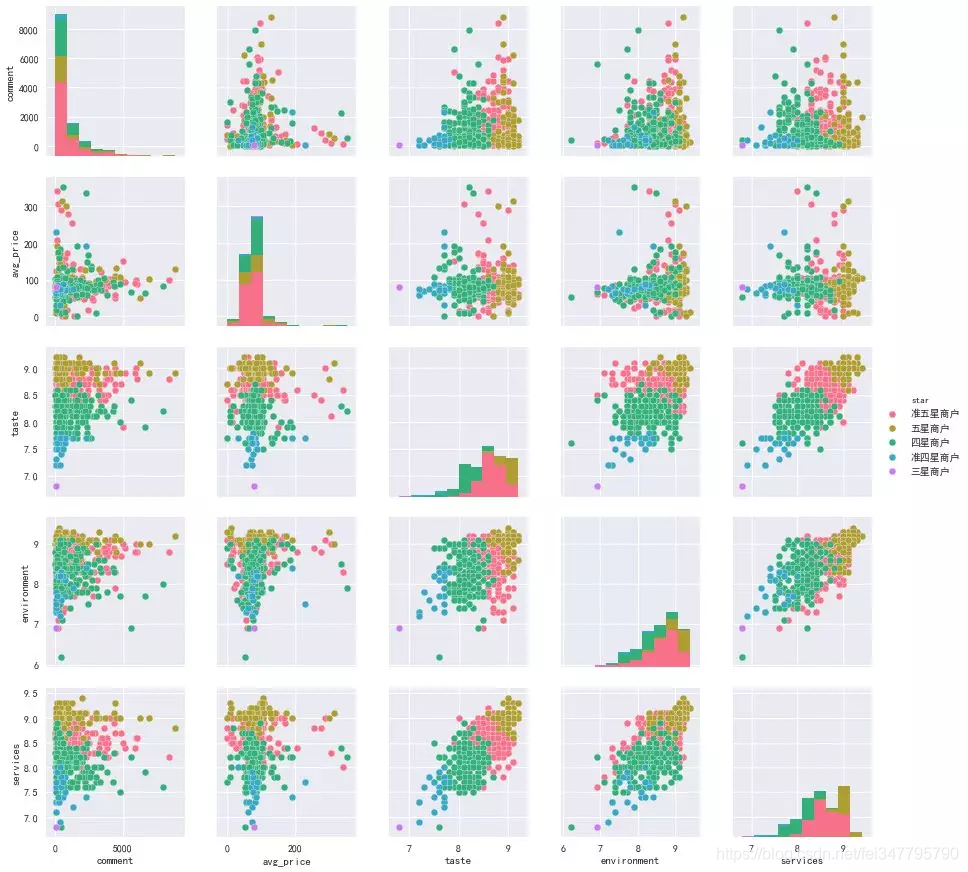
如图所看,并无什么直接关系,但是我们发现口味、环境和服务三者之间存在着非常好的线性关系,于是单独拿出来画了一个较大的图。
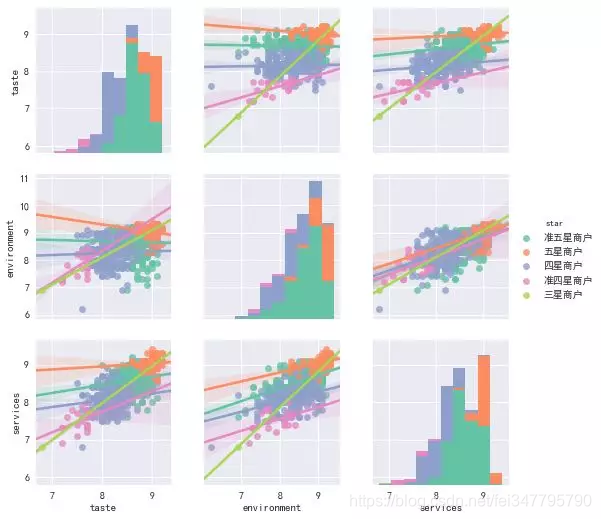
我们并且拟合了线性关系,由于三星商户只有一家,它的情况较为特殊之外,其他星级在口味、环境和服务的关系拟合中保持的相当一致,这也证明我们的猜想,这些变量之间存在线性关系。鉴于笔者本文最大的目的是做推荐,于是,我们进行了K-means聚类,这里取K为3,并且把星级转换为数字,五星对应5分,准五星对应4.5分,以此类推。最终得到了三类,通过作图,看看聚类情况如何吧。
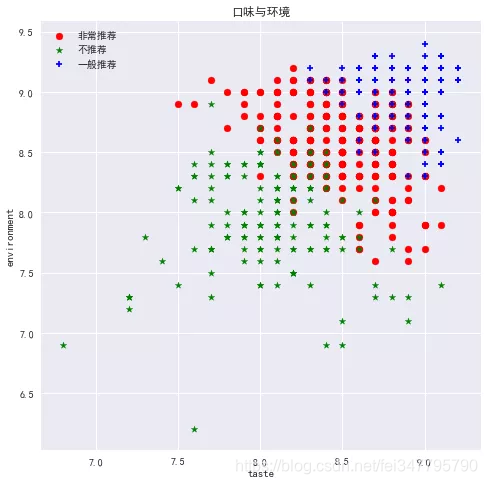
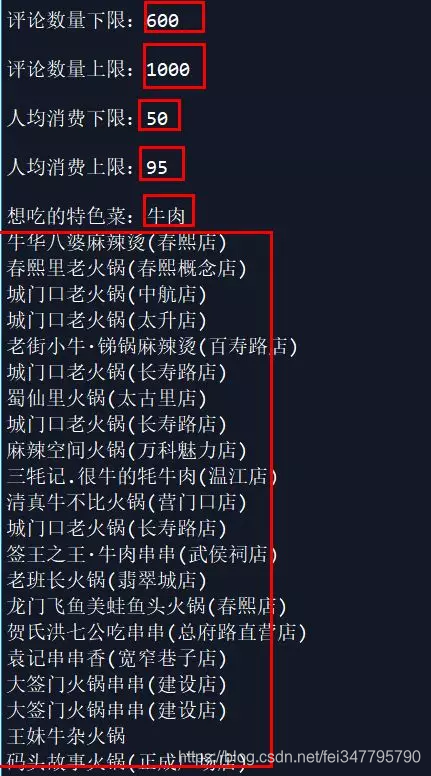
和我们想要的结果一致,在口味、环境、服务和星级上得分越高,我们就越推荐。然而推荐的店铺还是好多,能不能在集中一些呢?于是通过限制评论数量、人均消费和特色菜来进行推荐。由于笔者喜欢人少,便宜还有牛肉的店铺,这里得到了如下的结果:
代码
import time
import requests
from pyquery import PyQuery as pq
import pandas as pd
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
def restaurant(url):
# 获取网页静态源代码
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
except Exception:
return None
name=[]
url = []
star = []
comment = []
avg_price = []
taste = []
environment = []
services = []
recommend = []
num = {'hs-OEEp': 0, 'hs-4Enz': 2, 'hs-GOYR': 3, 'hs-61V1': 4, 'hs-SzzZ': 5, 'hs-VYVW': 6, 'hs-tQlR': 7, 'hs-LNui': 8, 'hs-42CK': 9}
def detail_number(htm):
try:
a = str(htm)
a = a.replace('1<', '<span class="1"/><')
a = a.replace('.', '<span class="."/>')
b = pq(a)
cn = b('span').items()
number = ''
for i in cn:
attr = i.attr('class')
if attr in num:
attr = num[attr]
number = number + str(attr)
number = number.replace('None', '')
except:
number = ''
return number
def info_restaurant(html):
# 获取饭店的名称和链接
doc = pq(html)
for i in range(1,16):
#获取饭店名称
shop_name = doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > div.tit > a:nth-child(1) > h4').text()
if shop_name == '':
break
name.append(shop_name)
#获取饭店链接
url.append(doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.pic > a').attr('href'))
try:
star.append(doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > div.comment > span').attr('title'))
except:
star.append("")
#获取评论数量
comment_html = doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > div.comment > a.review-num > b')
comment.append(detail_number(comment_html))
#获取人均消费
avg_price_html = doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > div.comment > a.mean-price > b')
avg_price.append(detail_number(avg_price_html))
#获取口味评分
taste_html = doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > span > span:nth-child(1) > b')
taste.append(detail_number(taste_html))
#获取环境评分
environment_html = doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > span > span:nth-child(2) > b')
environment.append(detail_number(environment_html))
#获取服务评分
services_html = doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > span > span:nth-child(3) > b')
services.append(detail_number(services_html))
#推荐菜,都是显示三道菜
try:
recommend.append(doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > div.recommend > a:nth-child(2)').text()+str(',')+\
doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > div.recommend > a:nth-child(3)').text()+str(',')+\
doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > div.recommend > a:nth-child(4)').text())
except:
recommend.append("")
for i in range(1,51):
print('正在获取第{}页饭店信息'.format(i))
hotpot_url = 'http://www.dianping.com/chengdu/ch10/g110p'+str(i)+'?aid=93195650%2C68215270%2C22353218%2C98432390%2C107724883&cpt=93195650%2C68215270%2C22353218%2C98432390%2C107724883&tc=3'
html = restaurant(hotpot_url)
info_restaurant(html)
print ('第{}页获取成功'.format(i))
time.sleep(12)
shop = {'name': name, 'url': url, 'star': star, 'comment': comment, 'avg_price': avg_price, 'taste': taste, 'environment': environment, 'services': services, 'recommend': recommend}
shop = pd.DataFrame(shop, columns=['name', 'url', 'star', 'comment', 'avg_price','taste', 'environment', 'services', 'recommend'])
shop.to_csv("shop.csv",encoding="utf_8_sig",index = False)
Python 爬取大众点评 50 页数据,最好吃的成都火锅竟是它!的更多相关文章
- python爬取大众点评并写入mongodb数据库和redis数据库
抓取大众点评首页左侧信息,如图: 我们要实现把中文名字都存到mongodb,而每个链接存入redis数据库. 因为将数据存到mongodb时每一个信息都会有一个对应的id,那样就方便我们存入redis ...
- 用Python爬取大众点评数据,推荐火锅店里最受欢迎的食品
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:有趣的Python PS:如有需要Python学习资料的小伙伴可以加点 ...
- python爬取大众点评
拖了好久的代码 1.首先进入页面确定自己要抓取的数据(我们要抓取的是左侧分类栏-----包括美食.火锅)先爬取第一级分类(美食.婚纱摄影.电影),之后根据第一级链接爬取第二层(火锅).要注意第二级的p ...
- python爬取豆瓣电影第一页数据and使用with open() as读写文件
# _*_ coding : utf-8 _*_ # @Time : 2021/11/2 9:58 # @Author : 秋泊酱 # @File : 获取豆瓣电影第一页 # @Project : 爬 ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- Hawk: 20分钟无编程抓取大众点评17万数据
1. 主角出场:Hawk介绍 Hawk是沙漠之鹰开发的一款数据抓取和清洗工具,目前已经在Github开源.详细介绍可参考:http://www.cnblogs.com/buptzym/p/545419 ...
- python 爬取天猫美的评论数据
笔者最近迷上了数据挖掘和机器学习,要做数据分析首先得有数据才行.对于我等平民来说,最廉价的获取数据的方法,应该是用爬虫在网络上爬取数据了.本文记录一下笔者爬取天猫某商品的全过程,淘宝上面的店铺也是类似 ...
- python爬虫爬取大众点评并导入redis
直接上代码,导入redis的中文编码没有解决,日后解决了会第一时间上代码!新手上路,多多包涵! # -*- coding: utf-8 -*- import re import requests fr ...
- 使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...
随机推荐
- leetcode-數組篇
Remove Element public class Lc27 { public static int removeElement(int[] nums, int val) { if (nums = ...
- Linux系统:centos7下搭建ZooKeeper3.4中间件,常用命令总结
本文源码:GitHub·点这里 || GitEE·点这里 一.下载解压 1.Zookeeper简介 Zookeeper 作为一个分布式的服务框架,主要用来解决分布式集群中应用系统的一致性问题,它能提供 ...
- Python调用Redis
#!/usr/bin/env python # -*- coding:utf-8 -*- # ************************************* # @Time : 2019/ ...
- C++ 面向对象程序设计复习大纲
这是我在准备C++考试时整理的提纲,如果是通过搜索引擎搜索到这篇博客的师弟师妹,建议还是先参照PPT和课本,这个大纲也不是很准确,自己总结会更有收获,多去理解含义,不要死记硬背,否则遇到概念辨析题会 ...
- 用户APC的执行过程
Windows内核分析索引目录:https://www.cnblogs.com/onetrainee/p/11675224.html 用户APC的执行过程 一.一个启发式问题 有一个问题,线程什么时候 ...
- 04-JVM垃圾收集器详解
1.垃圾收集器的种类 垃圾收集算法是内存回收的方法论,垃圾收集器是内存回收的具体实现工具.目前没有万能的垃圾收集器,需要根据具体的应用场景选择合适的垃圾收集器. 1.1Serial收集器(-XX:+U ...
- docker采用Dockerfile安装jdk1.8案例
1 获取一个简单的Docker系统镜像,并建立一个容器. 这里我选择下载CentOS镜像 docker pull centos 通过docker tag命令将下载的CentOS镜像名称换成centos ...
- [转]UIPATH机器人指南
本文转自:https://blog.csdn.net/weixin_33957036/article/details/80907372 介绍 机器人是UiPath的执行代理,可运行Studio中内置的 ...
- Linux下使用 github+hexo 搭建个人博客02-hexo部署到Github Pages
之前的这篇文章<Linux下使用 github+hexo 搭建个人博客01-hexo搭建>,相信大家都知道怎么搭建 hexo ,怎么切换主题,并且完成了一篇博文的创建,以及 MarkDow ...
- YARN HA部署架构
hadoop001: zk rm(zkfc线程) nm hadoop002: zk rm(zkfc线程) nm hadoop003: zk nm RMStateStore: 存储在ZK的/rmstor ...