9.python3实用编程技巧进阶(四)
4.1.如何读写csv数据
爬取豆瓣top250书籍
import requests
import json
import csv
from bs4 import BeautifulSoup books = []
def book_name(url):
res = requests.get(url)
html = res.text
soup = BeautifulSoup(html, 'html.parser')
items = soup.find(class_="grid-16-8 clearfix").find(class_="indent").find_all('table') for i in items:
book = []
title = i.find(class_="pl2").find('a')
book.append('《' + title.text.replace(' ', '').replace('\n', '') + '》') star = i.find(class_="star clearfix").find(class_="rating_nums")
book.append(star.text + '分') try:
brief = i.find(class_="quote").find(class_="inq")
except AttributeError:
book.append('”暂无简介“')
else:
book.append(brief.text) link = i.find(class_="pl2").find('a')['href']
book.append(link) global books
books.append(book) print(book) try:
next = soup.find(class_="paginator").find(class_="next").find('a')['href']
# 翻到最后一页
except TypeError:
return 0
else:
return next next = 'https://book.douban.com/top250?start=0&filter='
count = 0 while next != 0:
count += 1
next = book_name(next)
print('-----------以上是第' + str(count) + '页的内容-----------') csv_file = open('D:/top250_books.csv', 'w', newline='', encoding='utf-8')
w = csv.writer(csv_file)
w.writerow(['书名', '评分', '简介', '链接'])
for b in books:
w.writerow(b)
结果
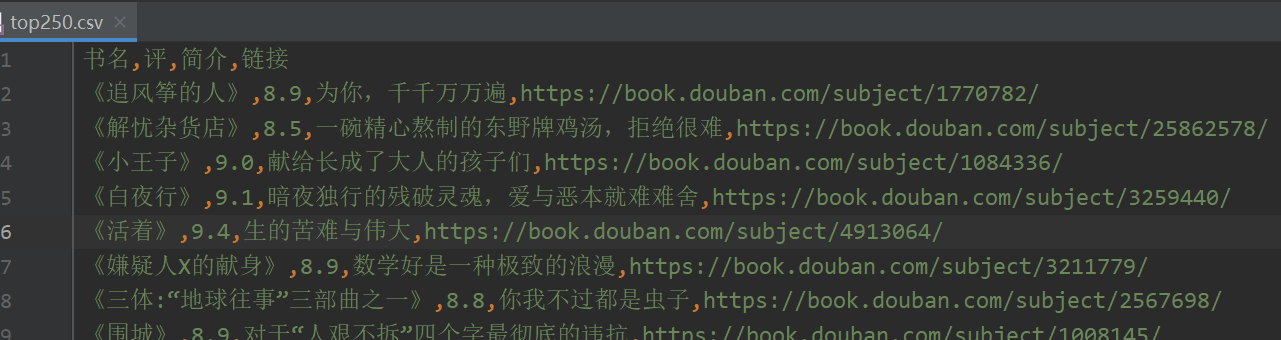
把评分为9.0的书籍保存到book_out.csv文件中
'''
1.爬取豆瓣评分排行前250本书,保存为top250.csv
2.读取top250.csv文件,把评分为9.0以上的书籍保存到另外一个csv文件中
''' import csv #打开的时候必须用encoding='utf-8',否则报错
with open('top250_books.csv', encoding='utf-8') as rf:
reader = csv.reader(rf)
#读取头部
headers = next(reader)
with open('books_out.csv', 'w', encoding='utf-8') as wf:
writer = csv.writer(wf)
#把头部信息写进去
writer.writerow(headers) for book in reader:
#获取评分
score = book[1]
#把评分大于9.0的过滤出来
if score and float(score) >= 9.0:
writer.writerow(book)
4.2.如何读写excel
安装两个库
pip install xlrd xlwt
读取excel
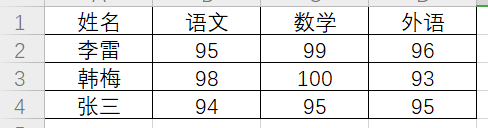
#4.2.如何读取excel
import xlrd
book = xlrd.open_workbook('demo.xlsx')
sheet = book.sheet_by_index(0)
#获取有多少行多少列
print(sheet.nrows) #
print(sheet.ncols) #
print(sheet.cell(0,0)) #text:'姓名'
print(sheet.cell_value(0,0)) #姓名
print(sheet.row_values(0)) #['姓名', '语文', '数学', '外语']
print(sheet.row_values(1,1)) #[95.0, 99.0, 96.0]
求分数的总和
#4.2.如何读写excel
import xlrd, xlwt
rbook = xlrd.open_workbook('demo.xlsx')
rsheet = rbook.sheet_by_index(0)
k = rsheet.ncols
#在最后添加一列 ‘总分’
rsheet.put_cell(0,k,xlrd.XL_CELL_TEXT, '总分', None)
for i in range(1,rsheet.nrows):
#求分数总和
t = sum(rsheet.row_values(i, 1))
rsheet.put_cell(i,k,xlrd.XL_CELL_NUMBER,t,None)
wbook = xlwt.Workbook()
wsheet = wbook.add_sheet(rsheet.name)
for i in range(rsheet.nrows):
for j in range(rsheet.ncols):
wsheet.write(i,j,rsheet.cell_value(i,j))
wbook.save('out.xlsx')
结果

9.python3实用编程技巧进阶(四)的更多相关文章
- Python3实用编程技巧进阶✍✍✍
Python3实用编程技巧进阶 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大家看的时候可以 ...
- Python3实用编程技巧进阶
Python3实用编程技巧进阶 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大家看的时候可以 ...
- Python3实用编程技巧进阶 ☝☝☝
Python3实用编程技巧进阶 ☝☝☝ 1.1.如何在列表中根据条件筛选数据 # 1.1.如何在列表中根据条件筛选数据 data = [-1, 2, 3, -4, 5] #筛选出data列表中大于等 ...
- 6.python3实用编程技巧进阶(一)
1.1.如何在列表中根据条件筛选数据 # 1.1.如何在列表中根据条件筛选数据 data = [-1, 2, 3, -4, 5] #筛选出data列表中大于等于零的数据 #第一种方法,不推荐 res1 ...
- 7.python3实用编程技巧进阶(二)
2.1.如何拆分含有多种分隔符的字符串 #2.1.如何拆分含有多种分隔符的字符串 s = 'ab;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz' #第一种方法 def my__ ...
- 8.python3实用编程技巧进阶(三)
3.1.如何实现可迭代对象和迭代器对象 #3.1 如何实现可迭代对象和迭代器对象 import requests from collections.abc import Iterable,Iterat ...
- 10.python3实用编程技巧进阶(五)
5.1.如何派生内置不可变类型并修其改实例化行为 修改实例化行为 # 5.1.如何派生内置不可变类型并修其改实例化行为 #继承内置tuple, 并实现__new__,在其中修改实例化行为 class ...
- EF – 2.EF数据查询基础(上)查询数据的实用编程技巧
目录 5.4.1 查询符合条件的单条记录 EF使用SingleOrDefault()和Find()两个方法查询符合条件的单条记录. 5.4.2 Entity Framework中的内部数据缓存 DbS ...
- EF – 2.EF数据查询基础(上)查询数据的实用编程技巧
目录 5.4.1 查询符合条件的单条记录 EF使用SingleOrDefault()和Find()两个方法查询符合条件的单条记录. 5.4.2 Entity Framework中的内部数据缓存 DbS ...
随机推荐
- JS&Jquery基础之窗口对象的关系总结
1.top 该变更永远指分割窗口最高层次的浏览器窗口.如果计划从分割窗口的最高层次开始执行命令,就可以用top变量.2.opener opener用于在window.open的页面引用执行该wi ...
- 利用Github建立博客专用图库
0.前言 当我们写博客或者文档的时候常常需要引用图片.倘或引用图片的链接是外网的,常常会出现加载过慢的情况,并且不稳定的图片来源不方便管理.所以如果建立一个博客专用的图片仓库,统一管理维护方面就方便得 ...
- linux 头文件路径
linux 头文件路径 /usr/include
- 算法问题实战策略 PICNIC
下面是另一道搜索题目的解答过程题目是<算法问题实战策略>中的一题oj地址是韩国网站 连接比较慢 https://algospot.com/judge/problem/read/PICNIC ...
- python pyquery 基本用法
1.安装方法 pip install pyquery 2.引用方法 from pyquery import PyQuery as pq 3.简介 pyquery 是类型jquery 的一个专供pyth ...
- Java流程控制之循环语句
循环概述 循环语句可以在满足循环条件的情况下,反复执行某一段代码,这段被重复执行的代码被称为循环体语句,当反复执行这个循环体时,需要在合适的时候把循环判断条件修改为false,从而结束循环,否则循环将 ...
- 数据可视化-matplotlib包
pyplot官网教程https://matplotlib.org/users/pyplot_tutorial.html #导入matplotlib的pyplot模块 import matplotlib ...
- A1100 Mars Numbers (20 分)
一.技术总结 这一题可以使用map进行想打印存储,因为数据量不是很大,最后直接输出.但是还是觉得没有必要. 主要考虑两个问题,首先是数字转化为字符串,实质就是进制转化,但是有点不同,如果十位有数字,个 ...
- UmiJS 目录及约定
在文件和目录的组织上,umi 更倾向于选择约定的方式. 一个复杂应用的目录结构如下: . ├── dist/ // 默认的 build 输出目录 ├── mock/ // mock 文件所在目录,基于 ...
- Spring案例--打印机
目录: 1.applicationContext.xml配置文件 <?xml version="1.0" encoding="UTF-8"?> &l ...